

TL;DR
Este artigo analisa o uso de 'proxy models' em instâncias como BigQuery e AlloyDB para viabilizar funções de IA em SQL. Ao substituir chamadas constantes de LLMs por modelos ultra-leves treinados em embeddings, reduz-se a latência em até 100x e o custo em 400x. A conclusão é estratégica: empresas devem adotar essa arquitetura para cargas de trabalho operacionais, reservando LLMs robustos apenas para tarefas que exigem raciocínio complexo, equilibrando eficiência e precisão semântica.
As funções SQL integradas com IA trouxeram o poder dos LLMs para dentro de nossos datasets, permitindo queries complexas como: "Quais avaliações de produto são pessimistas quanto à durabilidade?". Contudo, na prática de engenharia, isso gerou gargalos operacionais críticos: invocações de LLMs aumentam a latência entre 10x e 100x, com custos operacionais multiplicados por 1000x.
A resposta acadêmica e prática para isso reside nos proxy models: modelos ultra-leves (como regressão logística) que, ao serem treinados sob medida para uma query específica e alimentados por embeddings, substituem a necessidade de chamadas constantes aos modelos de fundação. Este conceito foi validado em um recente paper do SIGMOD e integrado nativamente ao BigQuery e AlloyDB.
Por que os Proxy Models funcionam com baixa latência?
O segredo está no reuso de embeddings. Ao utilizar geradores de embeddings (como os do Gemini), o esforço semântico é realizado uma única vez. Uma vez que o dado está vetorizado, o proxy model apenas executa uma classificação rápida em CPU, eliminando a dependência de hardware dedicado durante o runtime de consulta.
Fundamentalmente, não estamos abandonando a qualidade do LLM, mas aplicando uma técnica de aproximação. Em benchmarks, o ratio de performance (medido pelo F1 score) variou entre 90% e 116% em relação a chamadas puras de LLMs, provando que, para uma vasta gama de casos de uso corporativo, a especialização supera a generalização.
Como ocorre a execução dos Proxy Models?
O processador de query realiza, de forma orquestrada, as seguintes etapas:
- Coleta de amostras (cerca de 1.000 linhas).
- Rotulagem dessas amostras via LLM (TRUE/FALSE).
- Treinamento da regressão logística como proxy model.
- Avaliação de qualidade contra o set de teste.
- Decisão baseada no otimizador: usar o proxy ou realizar fallback para o LLM.
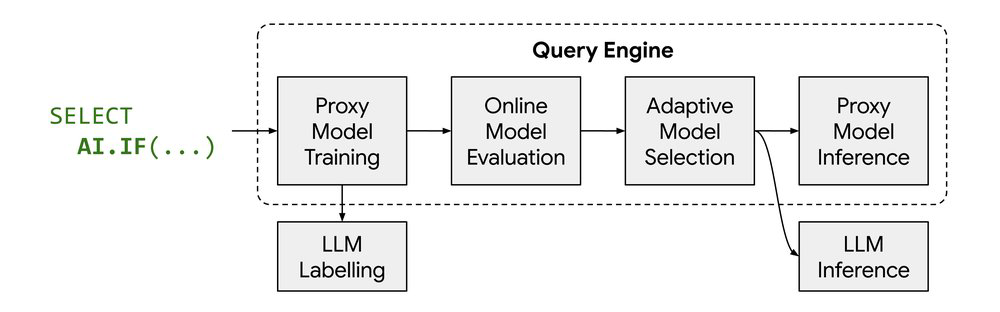
Enquanto no BigQuery isso ocorre on-the-fly, no AlloyDB o custo de treinamento é movido para fora do caminho crítico através de instruções de PREPARE.
Por que não usar apenas Vector Search?
É comum o ceticismo imediato, confundindo proxy models com vector search. Contudo, métricas de similaridade de cosseno não entregam a classificação binária ou multiclasse que o AI.IF provê. O proxy model, ajustado ao seu prompt específico, atua como um classificador treinado, enquanto o vector search baseia-se apenas em proximidade geométrica.
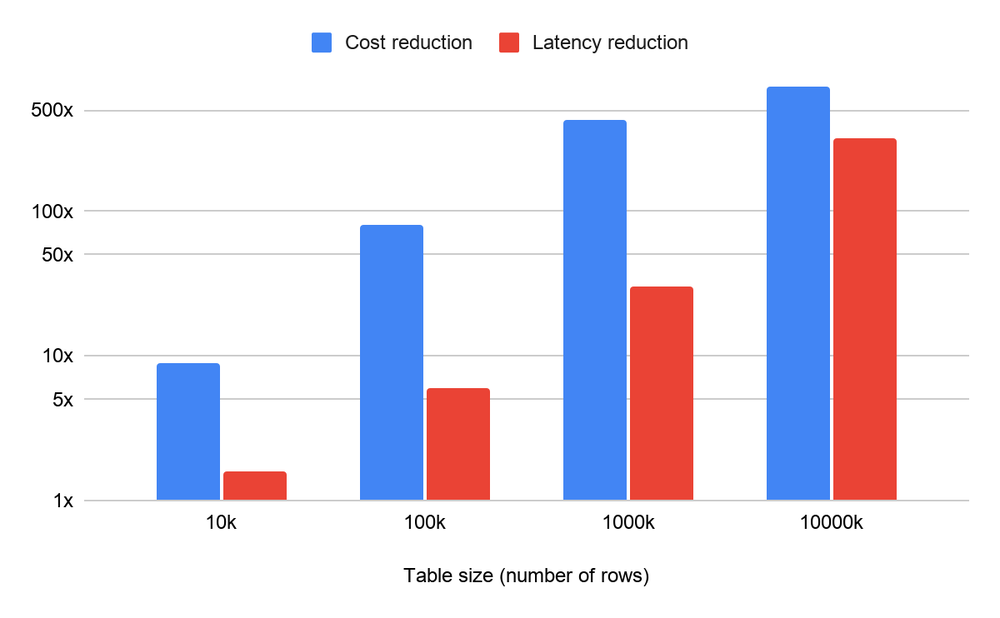
Resultados Experimentais e Ganhos de Performance
Os resultados demonstram que, além da economia de tokens que pode chegar a 400x, o ganho de latência (speedup) varia de 30x a 100x.
Conclusão
Não se trata de substituir a inteligência dos LLMs, mas de realizar o right-sizing do modelo. Para problemas simples, o proxy model é a solução de engenharia correta. À medida que modelos de embedding evoluem, a capacidade de identificar padrões semânticos complexos via classificadores não-lineares só tende a crescer, tornando essa arquitetura indispensável para quem escala aplicações de dados em nuvem.
Artigo originalmente publicado por Yannis PapakonstantinouDistinguished Engineer em Cloud Blog.
