

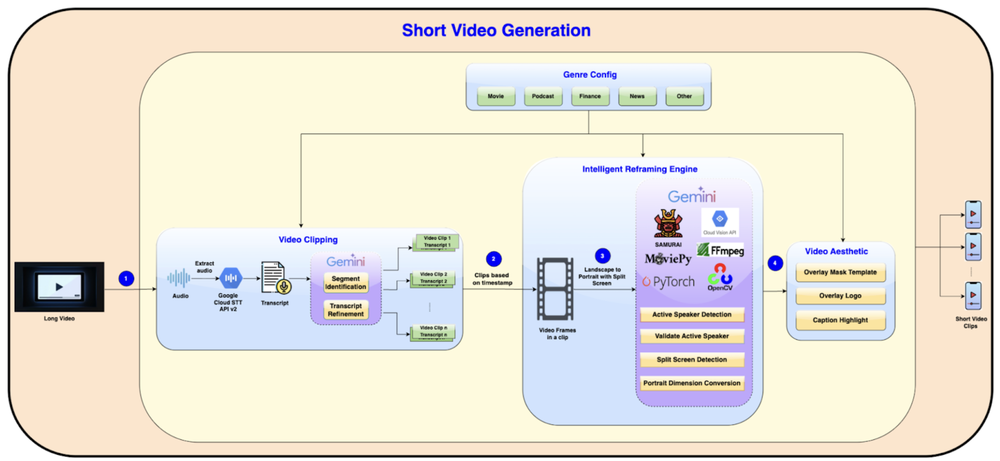
Este artigo analisa como a plataforma Glance automatizou a transformação de vídeos longos em clipes verticais de alta conversão usando uma pipeline de IA. Combinando Google Cloud Speech-to-Text, Gemini e Vision API, a arquitetura resolve desafios complexos como detecção de locutor ativo, segmentação inteligente e legendagem dinâmica. A conclusão é que automações baseadas em, computer vision e generative AI são viáveis e necessárias para empresas que precisam escalar produção de conteúdo sem sacrificar qualidade operacional.
Diariamente, horas de conteúdo em formatos horizontais (16:9) tornam-se obsoletas frente ao consumo massivo de feeds verticais em dispositivos móveis. Para a Glance, esse desafio escalou para a necessidade de processar mais de 10 mil vídeos por dia. A solução não exigia apenas recortes simples, mas inteligência para manter a relevância visual, detectando oradores e mantendo a coesão das conversas.
Como a infraestrutura de vídeo suporta a 'era do lock screen'?
O objetivo foi construir um pipeline end-to-end capaz de processar material bruto e gerar entregáveis prontos para publicação, mantendo critérios técnicos rigorosos:
- Key Moment Identification: Seleção algorítmica de segmentos engajadores.
- Active Speaker Detection: Foco dinâmico no orador ativo, descartando estática.
- Split Screen Detection: Identificação e alinhamento de layouts de entrevista.
- Intelligent Reframing: Conversão de wide-screen para vertical sem perda de contexto.
- Dynamic Captioning: Legendagem word-level com foco em engajamento mobile.
- Automated Branding: Aplicação programática de ativos visuais.
O motor dessa transformação utiliza Google Cloud Speech-to-Text v2, Gemini e Google Cloud Vision API, integrados à manipulação via Samurai, OpenCV e MoviePy.
Qual a arquitetura por trás da eficiência operacional?
A pipeline é segmentada em três módulos core:
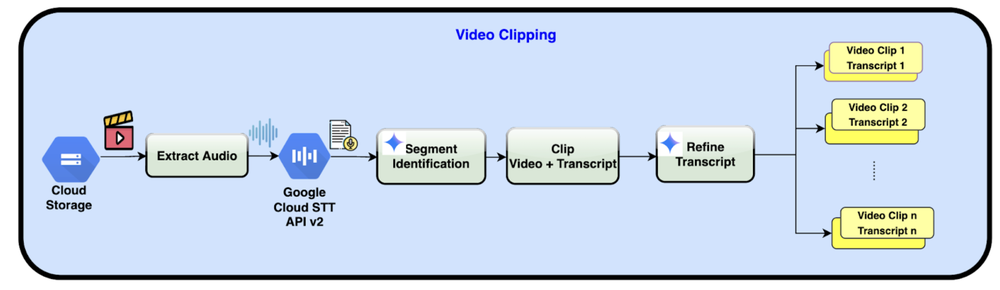
Como funciona o módulo de clipping?
O foco aqui é precisão. A extração de áudio, convertida por Speech-to-Text, é analisada pelo Gemini 2.5 Flash para determinar os pontos de corte ideais. O resultado é um conjunto de clipes com transcripts alinhados por tempo.
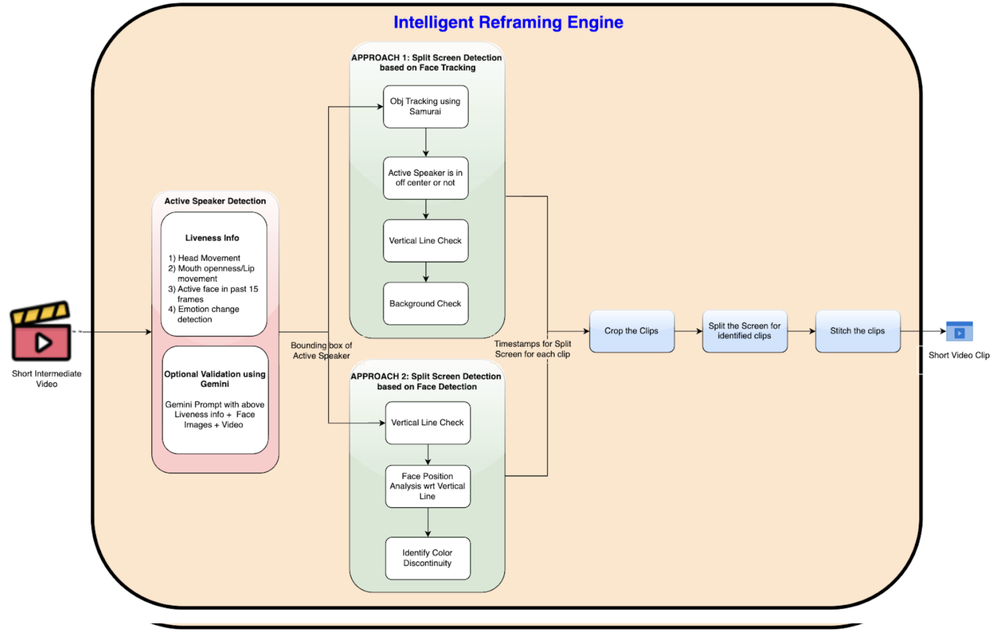
Como otimizar a reframe de conteúdo sem perda de inteligência?
O trunfo aqui é o Intelligent Reframing Engine, que evita o uso de cortes centrais genéricos, aplicando análise frame-a-frame via Vision API.
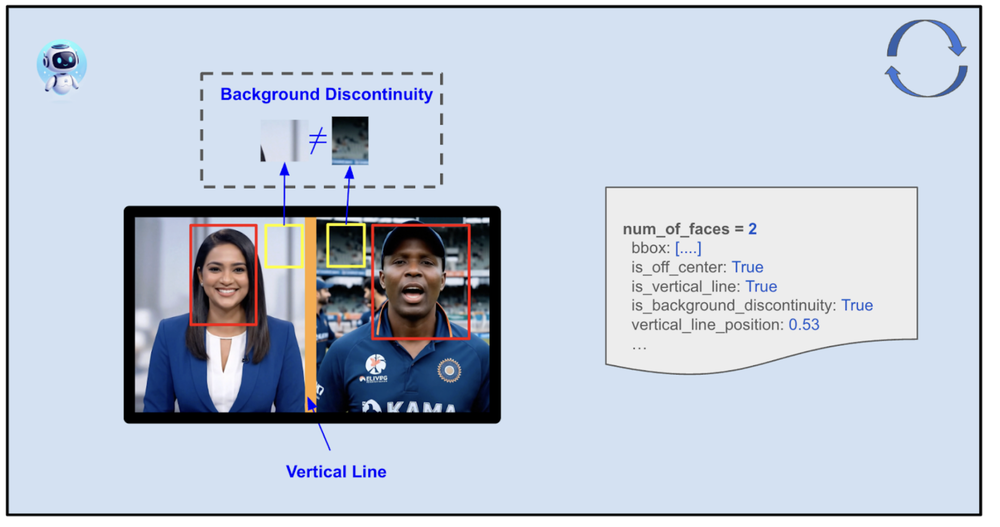
Detecção de Locutor Ativo
O sistema valida a 'vivacidade' do orador rastreando movimentos labiais e inclinações de cabeça, garantindo que o foco da câmera virtual nunca recaia sobre uma imagem estática ou um colaborador secundário que não esteja falando.


Como lidar com o desafio do Split-screen?
Para entrevistas divididas, o sistema utiliza duas abordagens: o tracking de objetos via Samurai para identificar linhas de separação e a análise de contraste de fundo via Vision API. O resultado é a reformatatação para um layout vertical stack.

Finalização e Branding
Por fim, a camada de branding utiliza máscaras (masks) com canal alfa e inserção dinâmica de logos, além de captions com destaque em texto para garantir que o consumo sem áudio não prejudique o engajamento.

Perguntas Frequentes
-
Como a IA consegue distinguir um locutor real de uma imagem estática ao fundo?
O sistema utiliza a detecção de pontos faciais para monitorar movimentos labiais e mudanças na pose da cabeça. Se não houver animação consistente baseada em parâmetros de 'liveness', o elemento é classificado como estático, evitando erros no crop inteligente. -
Quais ferramentas compõem a stack técnica citada para manipulação de vídeo?
A solução integra Google Cloud Speech-to-Text v2, Gemini e Vision API para inteligência, enquanto a manipulação de vídeo propriamente dita utiliza bibliotecas open-source como Samurai para tracking de objetos, OpenCV para processamento de imagem e MoviePy para a montagem final. -
Por que o uso de splitting de tela é importante em contextos de entrevistas?
O split-screen preserva o contexto do diálogo em layouts verticais (9:16). Ao identificar a divisão da tela, o sistema empilha os interlocutores verticalmente, mantendo a narrativa compreensível para o público mobile.
Artigo originalmente publicado por Himanshu AggarwalMachine Learning Engineer, Glance em Cloud Blog.
