

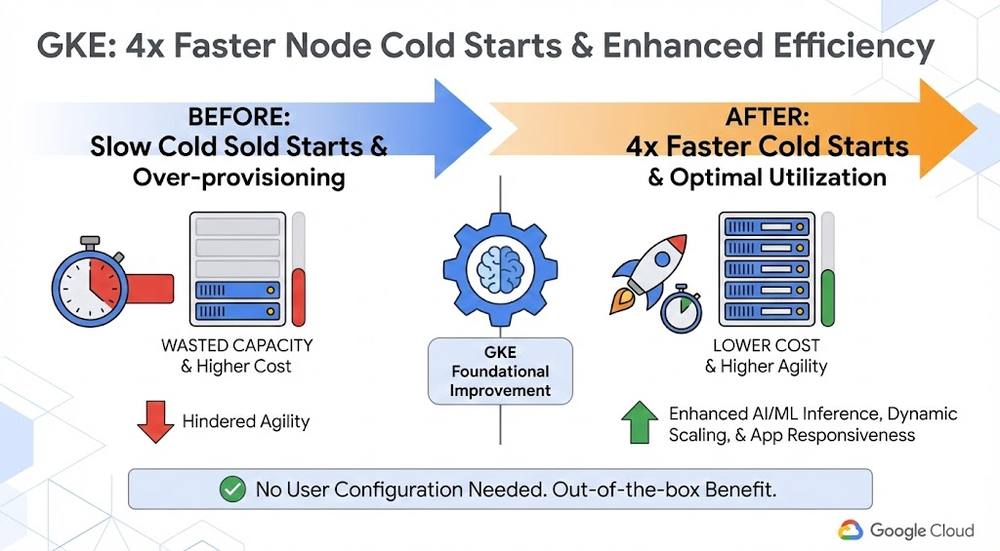
Esta atualização do GKE reduz em até 4x o tempo de inicialização de nodes através de melhorias arquiteturais no provisionamento. Para empresas brasileiras, isso elimina a dependência do over-provisioning como seguro contra latência em workloads de IA e processamento em lote. O ganho de agilidade é nativo, não exige mudanças em IaC (Terraform/YAML) e libera orçamentos anteriormente alocados para recursos ociosos, permitindo uma estratégia de escalonamento mais agressiva e eficiente em termos de custos.
O problema que o mercado enfrenta: o custo do "cold start"
Quem opera workloads de alta variabilidade — especialmente em cenários de inferência de IA ou batch processing — conhece bem o gargalo: o tempo que o cluster leva para provisionar um novo node durante um pico de demanda. Para mitigar o impacto de performance nos usuários finais, muitos times de engenharia recorrem ao over-provisioning, mantendo instâncias caras ligadas preventivamente. Na prática, isso infla a conta no fim do mês e reflete uma falha de eficiência operacional ao pagar por capacidade ociosa para evitar latência.
A solução: arquitetura de provisionamento repensada
O Google reestruturou a lógica de provisionamento de VMs e nodes do GKE. Utilizando uma combinação de buffers de computação inteligentes e uma arquitetura onde VMs podem ser reajustadas sem a necessidade de um reboot completo, conseguimos uma redução drástica no tempo de startup. Para os tomadores de decisão brasileiros, o impacto é direto: o escalonamento horizontal de pods torna-se muito mais ágil, permitindo uma arquitetura de aplicação mais enxuta e alinhada às melhores práticas de FinOps.
O que isso muda na prática para o seu time de Engenharia:
- Redução de desperdício: Com nodes subindo mais rápido, o autoscaler é tecnicamente validado para atuar conforme a demanda real, reduzindo a necessidade de manter pools de instâncias ociosas.
- Performance em IA: Reduzimos drasticamente o tempo entre o pico de requisições e a disponibilização de GPUs para inferência, garantindo menor time-to-market em soluções de IA.
- Zero Overhead de Ops: A aceleração é nativa. Não há necessidade de refatorar deploys, pipelines de CI/CD ou arquivos de configuração.
Disponibilidade e Expansão
O provisionamento acelerado já está em produção para workloads rodando em GKE Autopilot (ou Autopilot dentro de clusters Standard) para as seguintes famílias de hardware:
- NVIDIA L4 (G2 nodes)
- NVIDIA A100 (A2 nodes)
- NVIDIA RTXPRO6000 (G4 nodes)
- NVIDIA H100 (A3 nodes)
- Autopilot "General Purpose" Compute
A roadmap do Google indica que suporte para NVIDIA H200 (A3 ultra), B200 (A4 nodes) e Cloud TPUs chegará em breve, estendendo o ganho de agilidade operacional para quase a totalidade da camada de compute acelerado.
Perspectiva Estratégica
Se você já utiliza o modelo Autopilot nas instâncias suportadas, o ganho de performance é automático. Para times em ambientes Standard, a recomendação é avaliar o uso de ComputeClass para direcionar workloads específicos para essa nova camada de provisionamento, sem a necessidade de migrar todo o cluster de uma só vez. O foco, agora, deve ser ajustar as métricas de autoscaling para tirar proveito desse novo teto de velocidade de provisionamento.
Perguntas Frequentes
-
Preciso alterar meu Terraform ou manifestos YAML para habilitar essa aceleração?
Não. Trata-se de uma melhoria estrutural no plano de controle do GKE. A redução no tempo de provisionamento ocorre de forma transparente, sem necessidade de ajustes em infraestrutura como código (IaC). -
Essa atualização resolve a necessidade de manter buffers de instâncias ociosas?
Sim, em grande parte. Com a inicialização significativamente mais rápida dos nodes, o autoscaler consegue reagir em tempo real sem a necessidade de manter instâncias ociosas para mascarar a latência de startup, otimizando o seu spend em nuvem. -
Quais tipos de hardware são elegíveis atualmente para essa inicialização rápida?
No momento, o benefício está disponível para GKE Autopilot (incluindo workloads em clusters Standard) utilizando GPUs NVIDIA L4 (G2), A100 (A2), RTXPRO6000 (G4), H100 (A3) e máquinas de uso geral do Autopilot.
Artigo originalmente publicado por Karen AleksanyanPrincipal Software Engineer, Google Cloud em Cloud Blog.
