

A indústria de observabilidade amadureceu significativamente na última década, fornecendo ferramentas robustas para monitorar aplicações cloud-native através de metrics, logs, traces e profiles. No entanto, estamos em um momento de transição acelerada: o salto do desenvolvimento cloud-native para o AI-native暴露 (exposes) lacunas críticas que as ferramentas tradicionais não suprem. Quando falamos de sistemas de IA, frequentemente nos vemos limitados à leitura manual de logs de conversas ou a uma interpretação reativa baseada em intuição, o que é insustentável para operações em produção.
Agentes de IA tomam decisões autônomas, consomem ferramentas externas, geram conteúdo dinâmico e interagem com usuários e serviços de formas complexas. Se o seu ambiente operacional depende desses agentes, tratá-los como caixas-pretas é um risco operacional e financeiro. Para preencher essa lacuna, o Grafana Labs lançou recentemente o AI Observability no Grafana Cloud (em public preview). Esta solução surgiu de desafios internos de engenharia — tratando o monitoramento de agentes com o mesmo rigor dos microservices tradicionais.
Considerações estratégicas para empresas no Brasil
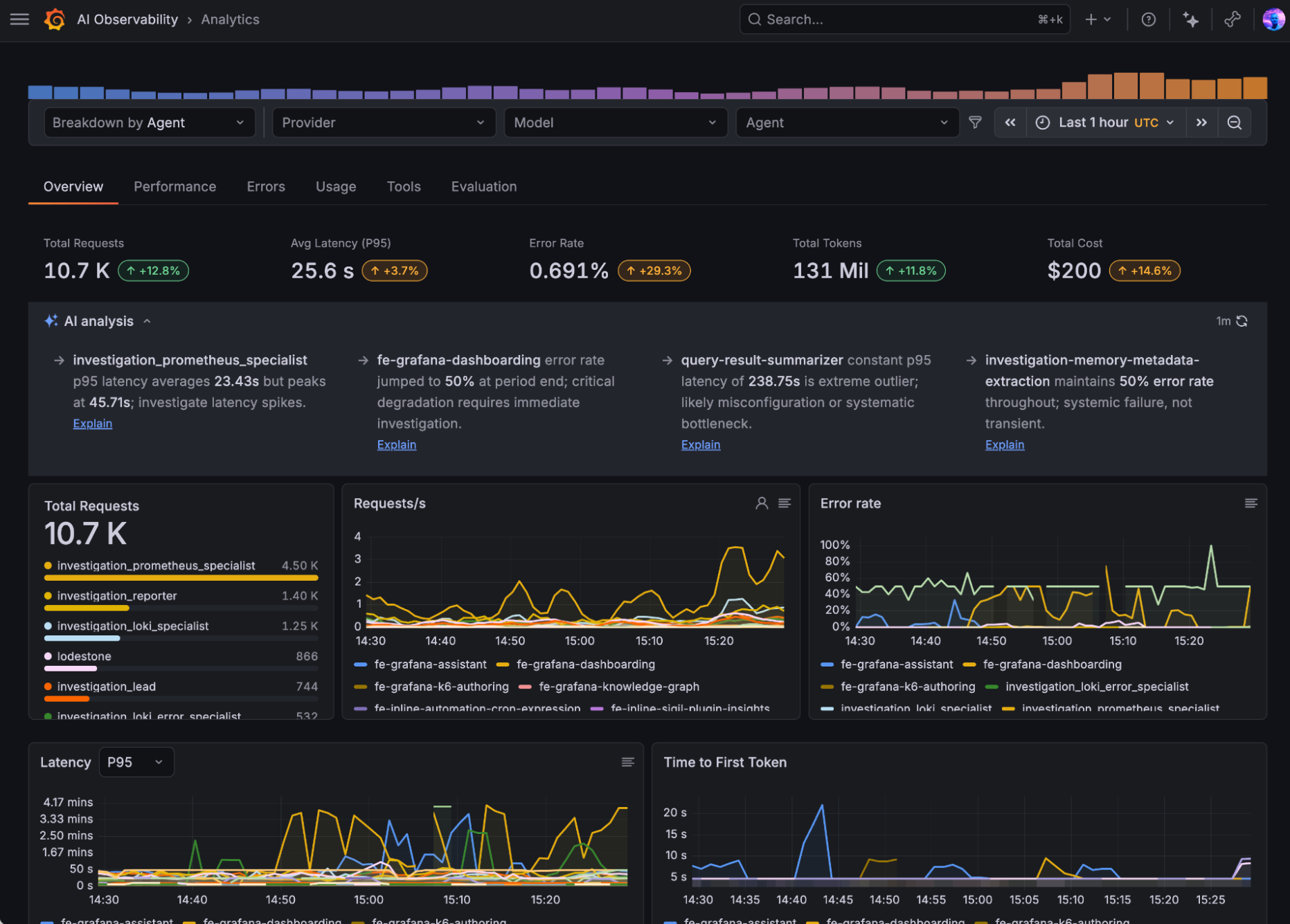
Ferramentas de SRE legadas fornecem signals como CPU usage, request latency e error rates. Eles são vitais, mas omissos em relação à semântica da IA: o agente está sendo útil? Ele está alucinando? A latência de tokens está degradando a experiência do usuário final?
O AI Observability no Grafana Cloud ajuda times de engenharia a:
- Observar comportamento de agentes em tempo real: Monitoramento de inputs, outputs e fluxos de execução sob demanda.
- Avaliação contínua de outputs: Configuração de alertas para respostas de baixa qualidade, violações de política ou comportamentos anômalos.
- Antecipação de riscos: Identificação precoce de exposição de dados, como vazamento de credentials em logs ou padrões de consumo de tokens atípicos.
- Correlação de telemetria: Tratar sessões de agentes como sinais de primeira classe, integrando-os ao mesmo ambiente onde já reside o monitoramento de infraestrutura.
Instrumentação simplificada com padrões abertos
A solução é totalmente compatível com OpenTelemetry, integrando-se naturalmente aos pipelines de observabilidade existentes. Através de um SDK leve, você captura automaticamente:
- Generations e conversas
- Metadados de modelos e provedores (LLM providers)
- Uso de ferramentas
- Métricas de latência e tokens
- Custos operacionais
Isso permite que você filtre por modelo, provider ou ambiente, facilitando a governança FinOps. É possível catalogar automaticamente diferentes versões de agentes (ex: mudanças em um system prompt) e auditar o desempenho de cada iteração de forma isolada.
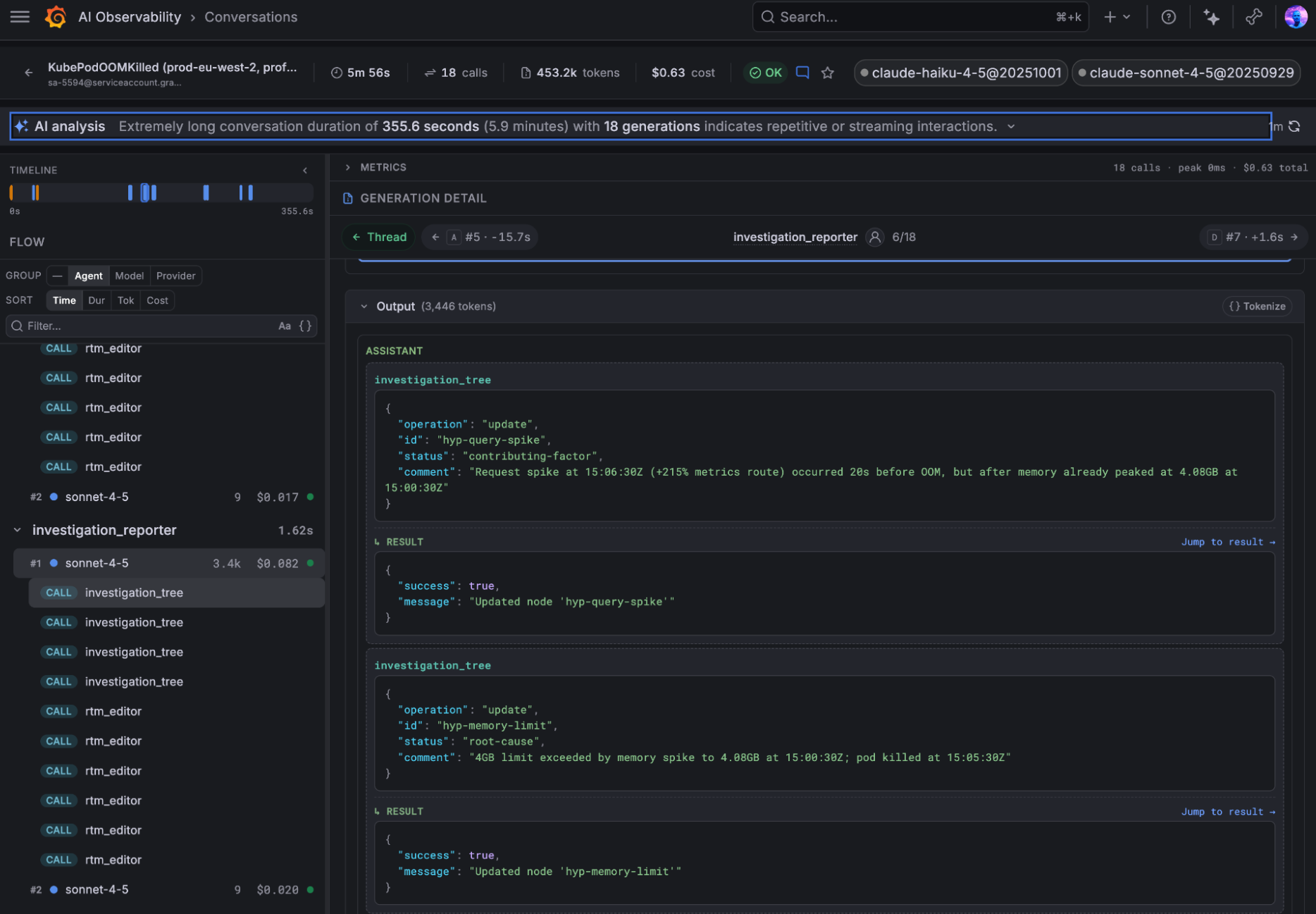
Quando os agentes falham de forma silenciosa
Um dos maiores desafios de rodar IA em produção é a falha sutil. Não há um crash na aplicação (crashed pod ou serviço offline), mas o sistema degrada a confiança do usuário, os custos de tokens disparam silenciosamente e a utilidade da resposta cai. Com o AI Observability, você tem o contexto necessário para o debug: drill-down em threads completas, rastreabilidade de tool calls e a correlação de custos por operação.
Se preferir, o Grafana Assistant pode atuar como um copiloto para análise de telemetria, correlacionando o uso de compute com as métricas de inferência da sua IA, permitindo identificar exatamente onde um custo elevado está sendo gerado.
Alertando o que realmente importa
Para cenários de escala, o uso de técnicas como LLM-as-a-judge, heurísticas ou regex para detectar saídas indesejadas é essencial. A integração nativa do AI Observability com o Grafana Alerting eleva o patamar de segurança. Ao receber um alerta de toxicidade, por exemplo, o time de SRE pode acionar runbooks específicos, utilizando as capacidades do Assistant para inspecionar o log da conversa e sugerir estratégias de mitigação imediatamente.
Esta abordagem de full-stack observability transforma como observamos a IA: não passamos a monitorar apenas o serviço, mas sim a inteligência que o rege.
Artigo originalmente publicado por Maurice Rochau em Grafana Labs blog on Grafana Labs.
