

Avaliar agentes de IA é uma tarefa complexa; verificar a precisão de tarefas de observabilidade é ainda mais desafiador. Embora agentes de IA tenham evoluído significativamente em codificação e utilização de ferramentas, o cenário de observabilidade impõe exigências diferentes. Em um incidente real, o desafio crítico raramente é escrever uma query; o ponto central é discernir qual sinal é relevante, diferenciar ruído de sintomas, correlacionar métricas, logs e traces e, por vezes, realizar alterações no Grafana sem desestabilizar dashboards críticos utilizados por outros engenheiros.
Para auxiliar a comunidade na transição para uma observabilidade assistida por IA, estamos tornando open source o grafana/o11y-bench. Trata-se de um benchmark projetado para avaliar agentes autônomos em fluxos de observabilidade. A ferramenta submete agentes a uma stack funcional do Grafana, integrada ao Grafana MCP server, e os avalia em um conjunto de tarefas práticas.
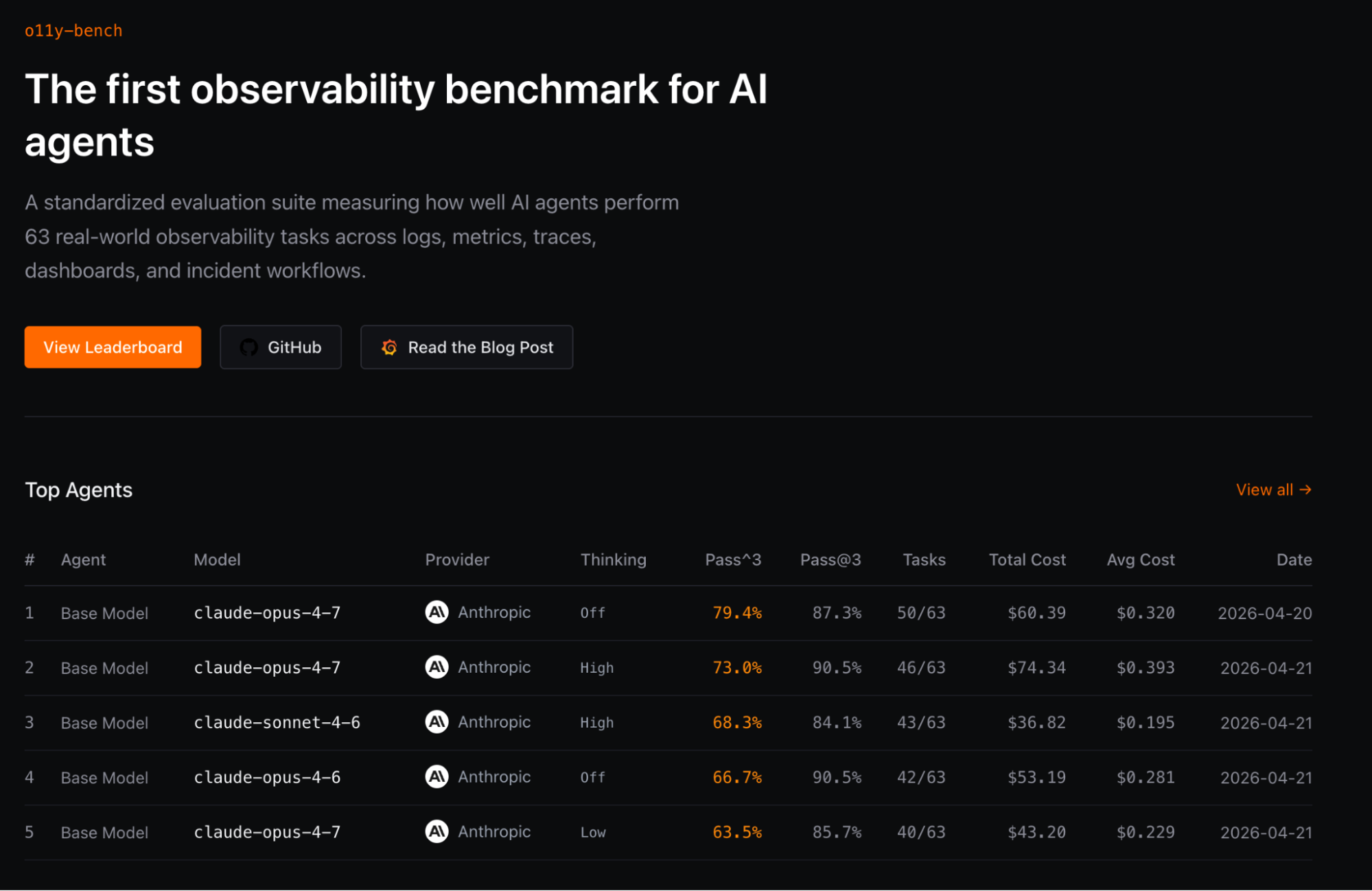
O o11y-bench utiliza o Harbor — um framework open source dos criadores do Terminal Bench — para padronizar ambientes de teste contra tarefas específicas. Nosso foco recai sobre o que realmente importa no dia a dia do SRE: execução de queries em métricas, logs e traces, investigação de incidentes e modificações de dashboards.
Por que a observabilidade precisa do seu próprio benchmark
Observabilidade não é meramente um problema trivial de tool-calling por agentes. Investigar a causa raiz (root cause analysis) ou editar dashboards demanda a interação entre grandes volumes de dados (métricas, logs, traces) e diferentes janelas de tempo, além do estado da aplicação. Devido a essa complexidade, validar se o agente executou a tarefa corretamente é difícil: uma query pode ser sintaticamente válida, mas retornar a série de dados errada; um dashboard pode ser renderizado, mas salvo incorretamente sob a perspectiva de configuração.
Para avaliar sistemas de IA com eficácia, os benchmarks precisam simular a realidade. O o11y-bench coloca o agente contra uma stack do Grafana real para medir resultados com base na complexidade de um ambiente moderno.
Essa medição padronizada fornece insights cruciais, permitindo discernir entre um agente que parece eficaz em demos e um em que você realmente pode confiar durante um incidente severo. Na observabilidade, os erros perigosos são, frequentemente, os mais sutis.
Open source, open testing
Construído sobre o Harbor, o o11y-bench permite que você execute seu modelo ou agent harness em um ambiente isolado (sandbox), acompanhado de um container Docker do Grafana com métricas, logs e traces sintéticos. O início é simples:
mise run bench:job -- --model openai/gpt-5.4-nano --task-name query-cpu-metrics --agent opencode
Este comando processa a tarefa, enviando os resultados para a pasta /jobs, onde é possível inspecionar a trajetória do agente e analisar o desempenho através de heurísticas e LLM-as-a-judge.
Estamos incentivando a comunidade a explorar essas possibilidades. Lançamos o leaderboard com modelos base, mas convidamos a experimentação com diferentes configurações de agentes para impulsionar a tecnologia nesta área.
O que o o11y-bench testa
A primeira versão pública inclui 63 tarefas cobrindo:
- Prometheus e PromQL
- Loki e LogQL
- Tempo e TraceQL
- Investigação de incidentes em múltiplos passos
- Edição e reparo de dashboards
As tarefas são desenhadas para serem determinísticas, facilitando a gradação, mas com complexidade suficiente para expor falhas. Um exemplo é a tarefa promql-retry-backlog-triage:
"Acreditamos que o incidente de pagamento acumulou retries ocultos. Nas últimas seis horas, qual serviço apresentou a maior profundidade de retry/backlog, qual a magnitude disso e o serviço seguinte parece apenas um reflexo ou um problema primário comparável?"
Agentes focados em "pensamento excessivo" tendem a consumir muitos tokens e exceder o tempo limite, enquanto agentes de alta precisão diagnosticam o sistema rapidamente.
Por que verificar o trabalho de observabilidade é difícil
Se um usuário solicita a investigação de latency ou a atualização de um dashboard, o resultado visual não basta. O benchmark utiliza queries de referência (via PromQL ou LogQL) para validar os dados citados pelo modelo. Para dashboards, inspecionamos o JSON salvo e executamos as queries para comparar. Nossa filosofia: verificar a verdade factual (o que foi feito), e não apenas a fluidez da resposta.
Medindo confiabilidade vs. sucesso de "melhor de três"
Utilizamos duas métricas principais:
- Pass^3: Métrica de consistência, calculada pela média do benchmark em três execuções.
- Pass@3: Métrica de sucesso, verificando se o modelo acertou ao menos uma vez em três tentativas.
Nota: Priorizamos o Pass^3, pois a consistência é vital em observabilidade, onde um erro sutil pode desviar a equipe durante o troubleshooting.
Os resultados
O lançamento inicial avaliou 29 variantes de modelos em 5.481 tentativas totais.
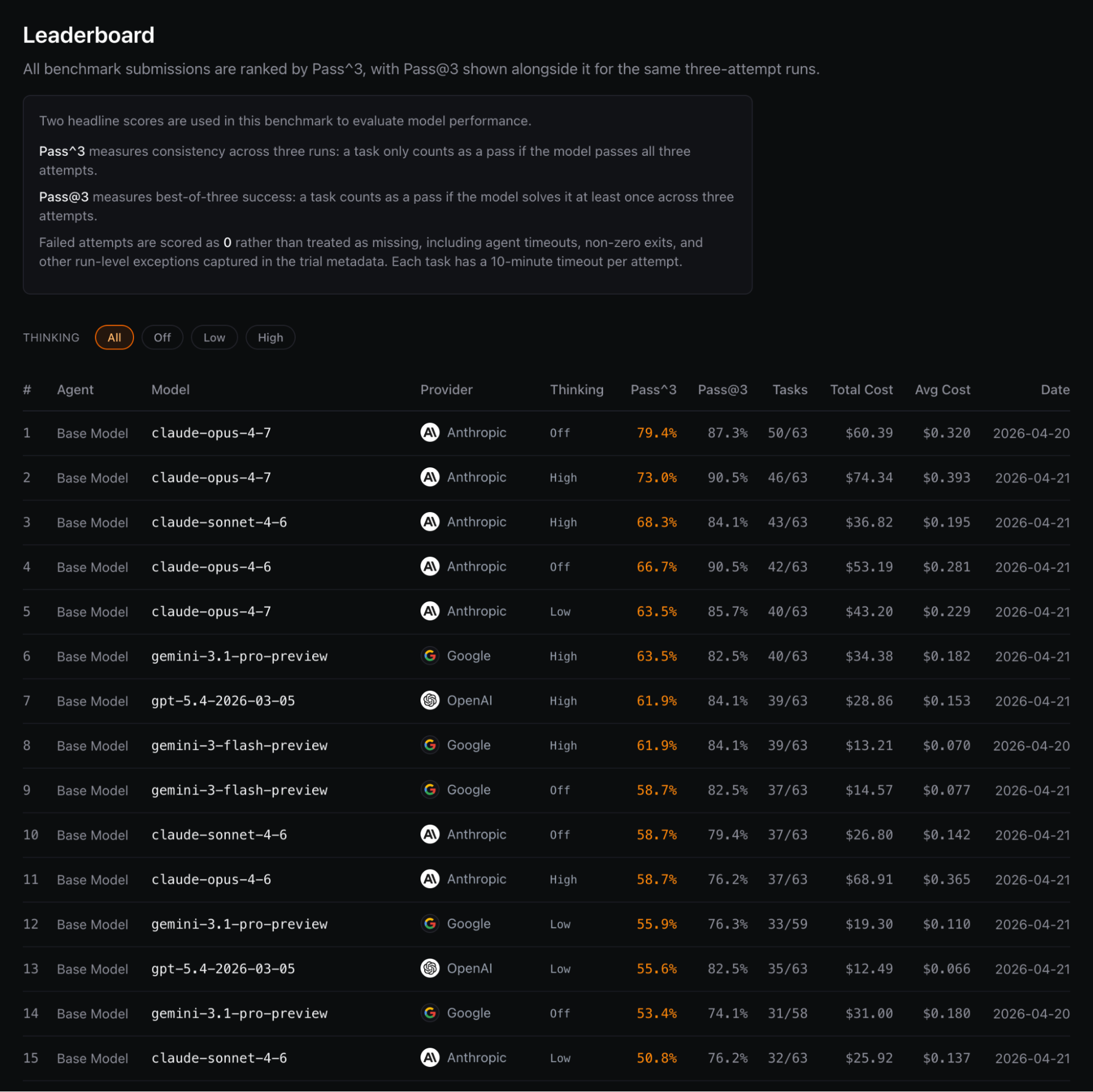
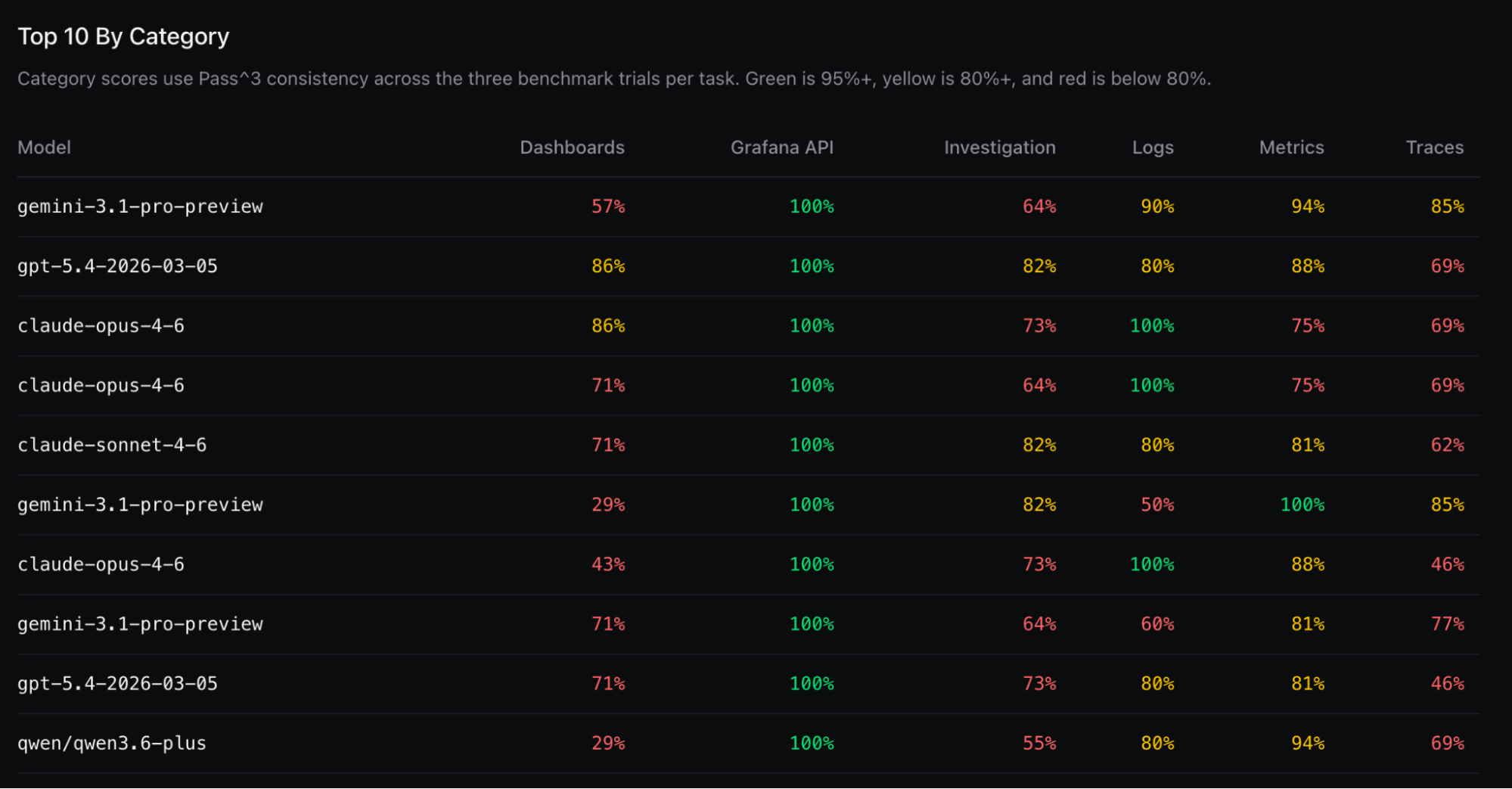
O Qwen 3.6 Plus destacou-se como o melhor modelo open source testado. A lição central: a confiabilidade é o divisor de águas. Muitos modelos acertam uma vez, mas poucos mantêm a consistência necessária para serem confiáveis operacionalmente.
Experimente você mesmo
O caminho mais rápido é clonar o repositório grafana/o11y-bench, seguir as instruções do README e submeter seus próprios modelos e configurações. Contribuições ao leaderboard no HuggingFace e feedbacks via GitHub Issues são muito bem-vindos.
Para saber mais sobre o ecossistema Grafana e como o Grafana Cloud pode simplificar a observabilidade da sua stack, visite nossa página de AI observability.
Artigo originalmente publicado por Yasir Ekinci em Grafana Labs blog on Grafana Labs.
