

Se você opera workloads em Databricks, provavelmente já enfrentou gargalos de visibilidade que impactam diretamente o seu negócio: “Quanto esse processamento está consumindo?”, “Por que esse job de ETL falhou?”, ou “Por que a latência das consultas em SQL Warehouse subiu?”.
Essas questões não são apenas técnicas; são indicadores de eficiência operacional. O Databricks é uma ferramenta poderosa para data engineering e ML, mas, em escala, a falta de uma camada de observabilidade unificada gera custos ocultos e riscos SRE. A nova integração oficial entre Databricks e Grafana Cloud resolve isso, permitindo extrair métricas diretamente dos System Tables sem a complexidade de gerenciar exporters customizados ou desenhar dashboards complexos do zero.
Quem se beneficia com essa integração?
A observabilidade eficiente é transversal e deve atender diferentes personas dentro da sua engenharia:
- Times de FinOps: Precisam de controle sobre o consumo de DBU, tendências de custo e detecção imediata de picos inesperados no billing.
- Times de Platform e SRE: Focam na saúde dos jobs e pipelines. Precisam responder: a ingestão está saudável? Os SLAs estão sendo cumpridos?
- Times de Analytics e BI: Focam na experiência do usuário final. Quando a latência de um SQL Warehouse aumenta, os relatórios travam e o negócio para.
O que você recebe: Dashboards práticos
A integração entrega três dashboards nativos que cobrem os pilares de operação:
1. Databricks Overview
Funciona como um resumo executivo para monitoramento de saúde da plataforma e custos.
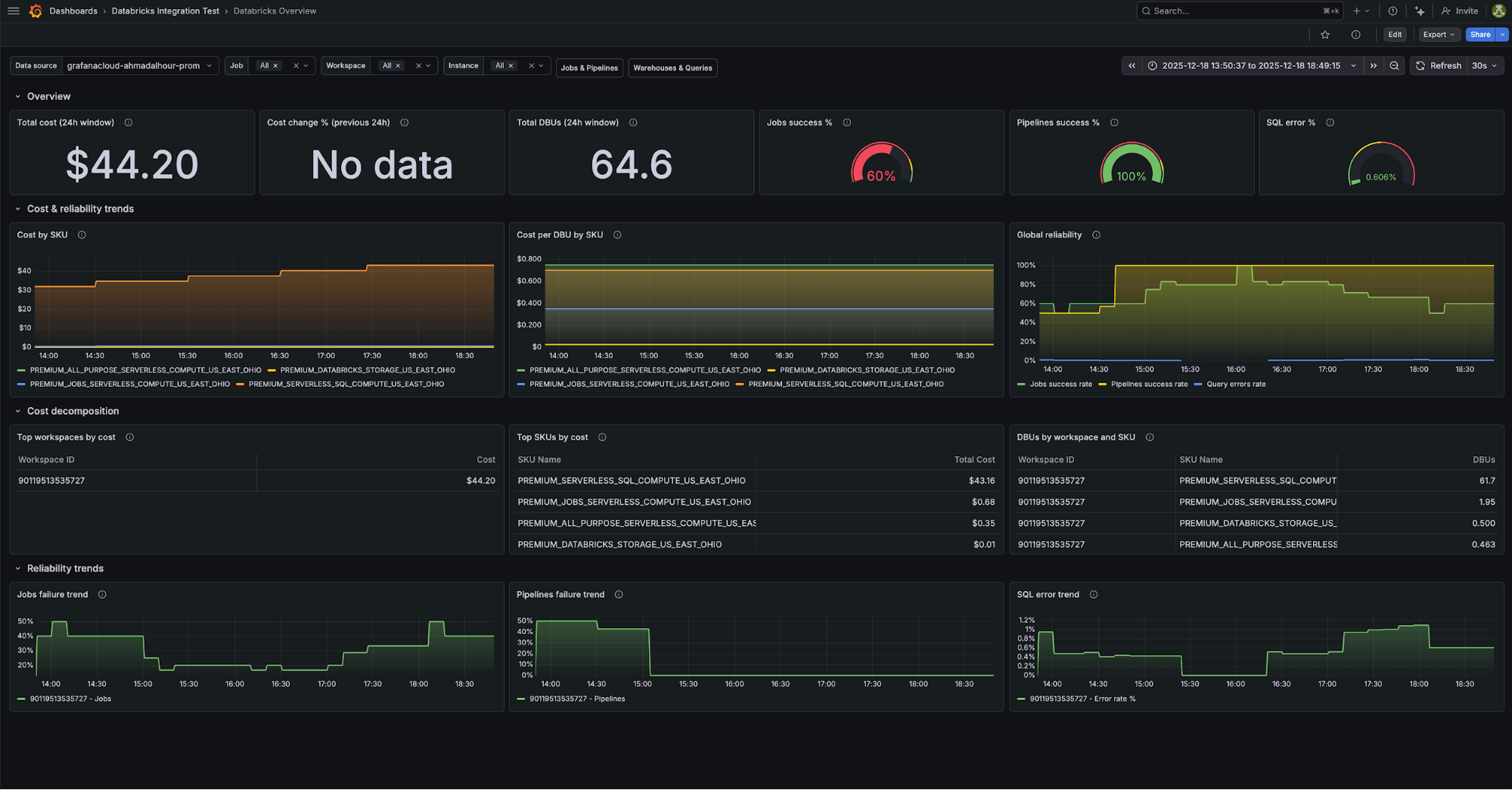
Métricas-chave:
databricks_billing_cost_estimate_usd_slidingdatabricks_billing_dbus_slidingdatabricks_job_run_status_slidingdatabricks_pipeline_run_status_sliding
2. Databricks Jobs and Pipelines
Focado nos times de engenharia, fornece visibilidade granular sobre a execução de tarefas.
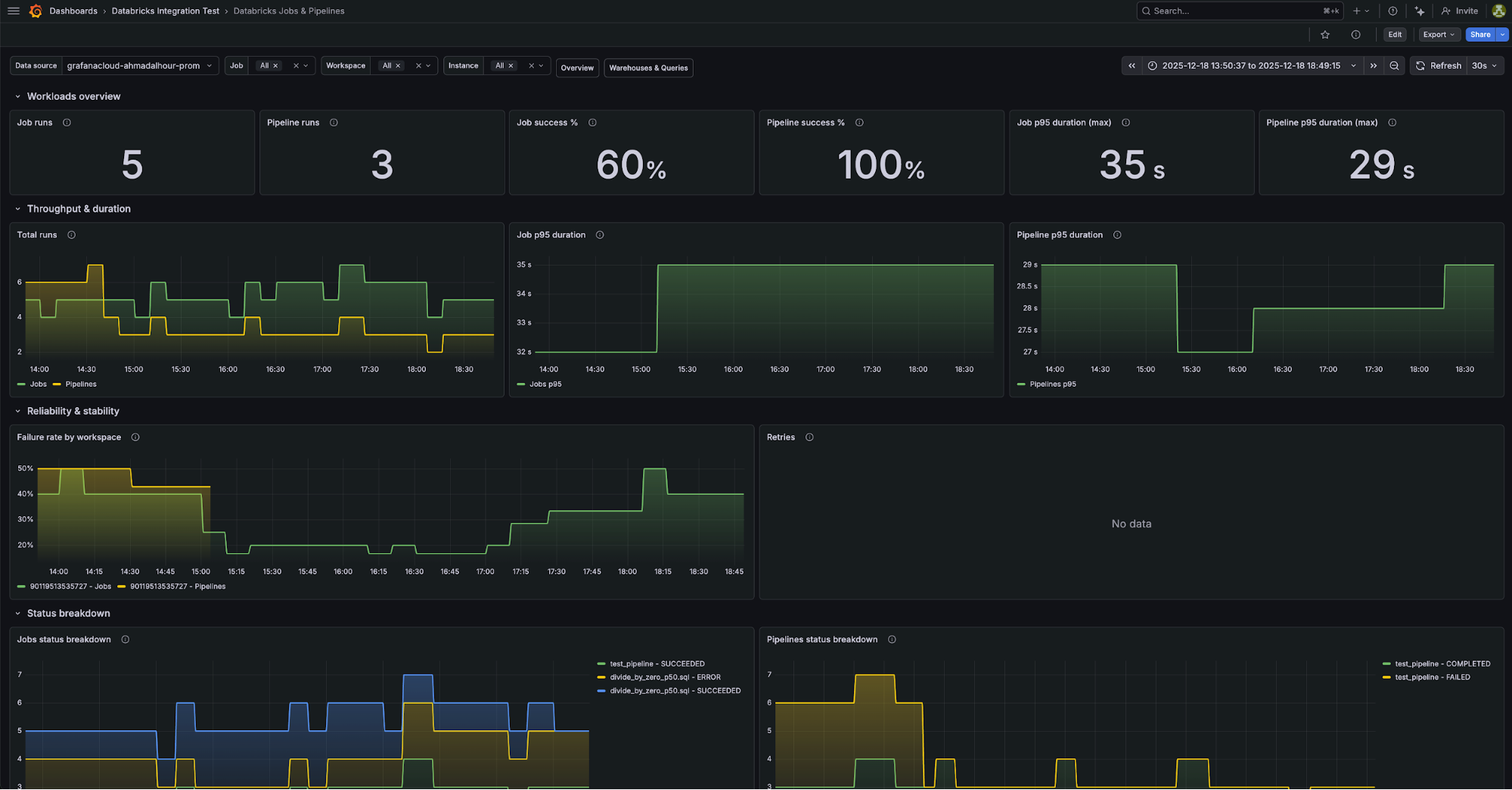
Métricas-chave:
databricks_job_runs_slidingdatabricks_job_run_duration_seconds_sliding(p50, p95, p99)databricks_pipeline_runs_slidingdatabricks_pipeline_freshness_lag_seconds_sliding
3. Databricks Warehouses and Queries
Essencial para diagnosticar degradações de performance em SQL queries.
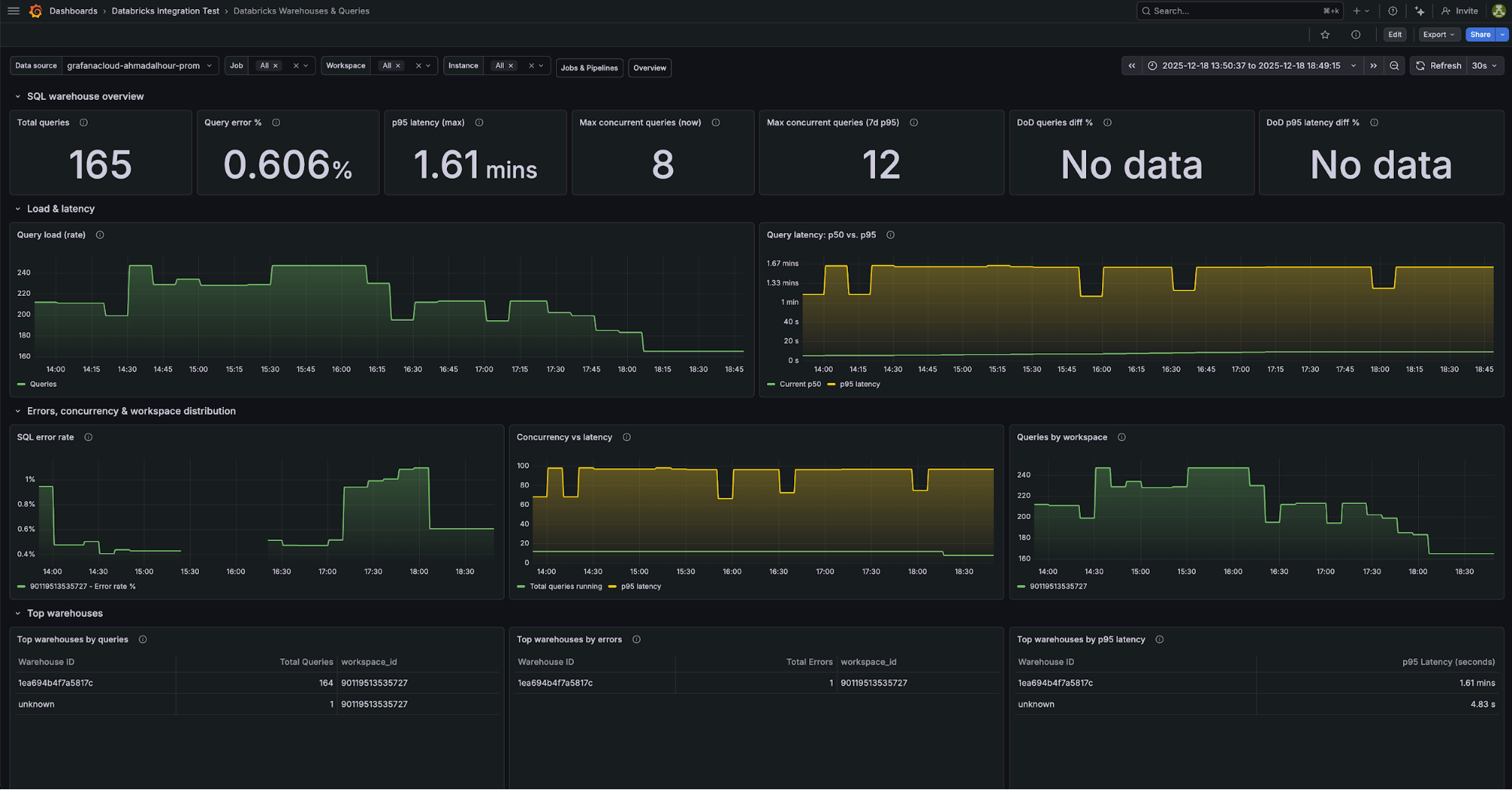
Métricas-chave:
databricks_queries_slidingdatabricks_query_duration_seconds_sliding(p50, p95, p99)databricks_query_errors_slidingdatabricks_queries_running_sliding
Configuração e pontos de atenção
A integração utiliza o databricks-prometheus-exporter embutido no Alloy. Você apenas precisa configurar as credenciais do seu service principal e conceder acesso às System Tables específicas (system.billing, system.lakeflow, e system.query).
Pontos críticos para o seu time:
- Atraso no Billing: Os dados de billing no Databricks possuem um lag natural de 24 a 48 horas. Não conte com esse dashboard para controle de custo em tempo real, mas sim para análise de tendências históricas.
- SQL Warehouse: Como a coleta consome recursos de computação, certifique-se de que o SQL Warehouse não entre em suspensão automática durante os intervalos programados de scraping (o padrão é 10 minutos).
- Permissões de Pipeline: Algumas tabelas do Lakeflow exigem grants de
SELECTexplícitos além dos permissões padrão da conta.
Essa solução é um ganho imediato de eficiência operacional, alinhando-se a uma cultura de monitoramento proativo em ambientes cloud complexos.
Artigo originalmente publicado por Grafana Labs Team em Grafana Labs blog on Grafana Labs.
