

Migração Segura de Managed Disks no Azure com Terraform e IA
TL;DR: Usuários de Terraform no Azure frequentemente sofrem com a recriação indesejada de dispositivos ao alterar arquivos de configuração, devido ao uso de índices em loops 'for_each'. Este artigo analisa como mitigar este risco de produção através da implementação de chaves estáveis (baseadas em IDs de domínio, como VM + LUN) e o uso de automação via GitHub Copilot para gerenciar a migração do state do Terraform, evitando perda de dados e downtime.
Um dos problemas mais críticos que times de Engenharia enfrentam ao gerenciar infraestrutura no Azure via Terraform é a destruição e recriação inadvertida de Managed Disks. O que parece ser uma alteração trivial — como adicionar um novo disco de dados a uma VM existente — pode desencadear uma série de eventos disruptivos em ambientes de produção.
Em grandes empresas, esse comportamento é um risco operacional inadmissível. Este artigo detalha como transitar de chaves baseadas em índices para chaves estáveis, utilizando estratégias de state migration e automação para garantir a integridade dos dados.
A causa raiz: O uso de índices em for_each
É comum encontrar módulos de Terraform que consolidam definições de VMs e seus discos em listas, iterando sobre elas através do índice da lista:
for_each = { for index, sp in local.managed_disks : index => sp }
Este padrão parece inofensivo, mas é inerentemente instável:
- Adicionar um disco a uma VM desloca os índices de todos os discos subsequentes na lista.
- Qualquer reordenamento em arquivos JSON de ambiente altera a ordem de processamento.
- O Terraform, sensível a essas mudanças, interpreta o deslocamento como uma ordem para destruir o recurso antigo e criar um novo com a nova posição.
O resultado é o agendamento de uma destruição massiva de discos, ainda que a infraestrutura desejada no Azure permaneça a mesma.
Por que este cenário é um risco de alta severidade no Azure?
Os Managed Disks no Azure sustentam camadas críticas de aplicações stateful. Quando falamos de bancos de dados, servidores de middleware ou workloads de processamento em lote, uma substituição forçada de disco resulta em:
- Perda Irversível de Dados: Dependendo da configuração, o volume original é removido.
- Outages Prolongados: O tempo para provisionar, formatar e restaurar a aplicação impacta o SLA drásticamente.
- Janelas de Mudança de Falha: Erros de planejamento que levam ao descarte de recursos de produção geram horas extras e estresse na equipe.
Portanto, a estabilidade do state deve ser tratada como um requisito de design, não como um detalhe técnico secundário.
Como implementar o padrão de chaves estáveis
A solução é adotar um identificador fixo para cada disco. Em vez do índice, utilize as propriedades imutáveis do recurso, como a LUN (Logical Unit Number) atrelada à VM:
"${sp.vm}-${sp.data_disk.lun}"
Esta chave é:
- Determinística: Não depende da posição na lista.
- Legível: Facilita o troubleshooting no state.
- Consistente: Mantém-se idêntica em diferentes ambientes (dev/prod).
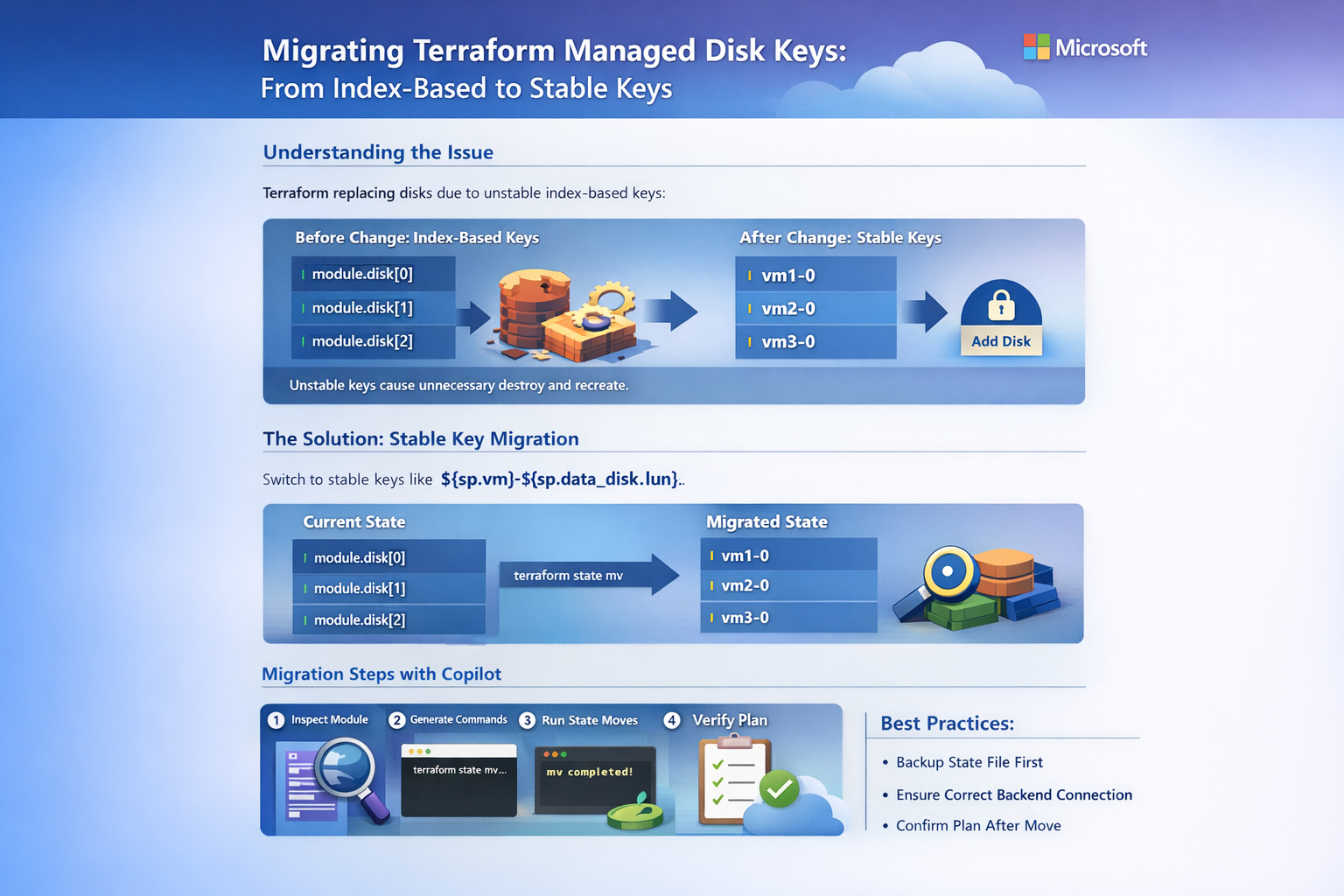
O desafio da migração de state
Alterar o código não é suficiente. Como o Terraform rastreia recursos pelo endereço no state, você precisa notificar o arquivo sobre a alteração das chaves utilizando o comando terraform state mv.
Automação com GitHub Copilot Skills
Para eliminar o erro humano na manipulação de endereços do state, nossa recomendação é utilizar skills de automação. Esse script/skill deve realizar a inspeção dos módulos, ler os arquivos de configuração (ex: JSON do Azure Landing Zone) e gerar os comandos terraform state mv necessários antes mesmo de qualquer terraform plan chegar ao pipeline.
Isso torna o processo de migração auditável, versionado e, acima de tudo, seguro.
Fluxo de trabalho recomendado
- Validação: Garanta que o
terraform planatual não apresente alterações pendentes. - Atualização: Modifique o código trocando os índices por chaves estáveis.
- Backup: Realize com segurança um backup do seu state file (especialmente se usar Azure Storage).
- Migração: Execute
terraform state mvcom base no mapeamento gerado. - Verificação: Rode um novo
terraform plan. O esperado é "no changes" para os discos existentes.
Considerações de CI/CD e Backends
Lembre-se: terraform state mv modifica o state remoto em tempo real. Em esteiras de CI/CD, garanta que suas migrações sejam executadas de forma atômica e coordenada por ambiente. Nunca realize o merge do código com chaves estáveis antes de garantir que a migração do estado foi propagada para todos os ambientes (sandbox, staging e production).
Conclusão
Ao focar em designs de estado estáveis e utilizar automação para migrar recursos legados, você remove o componente de incerteza das mudanças de infraestrutura. Tornar o deployment "tedioso" e repetível — sem surpresas no Azure — é o objetivo final de qualquer time que busca excelência operacional.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
