

No cenário atual de escalabilidade de agentes conversacionais, o design da camada de dados é, muitas vezes, o divisor de águas entre o sucesso e a falha de um projeto. Para suportar milhões de usuários simultâneos, os agentes precisam de continuidade conversacional — a capacidade de manter chats responsivos preservando todo o contexto que os modelos de backend exigem para performar.
Este artigo analisa como utilizar as soluções do Google Cloud para resolver dois desafios críticos de dados em AI: a atualização rápida de contexto para interações em real-time e a recuperação eficiente de históricos de longo prazo. Exploraremos uma abordagem poliglota utilizando Redis, Bigtable e BigQuery, garantindo que seu agente retenha detalhes e continuidade, desde interações recentes até arquivos com meses de idade.
Estratégia de armazenamento poliglota para históricos de curto, médio e longo prazo
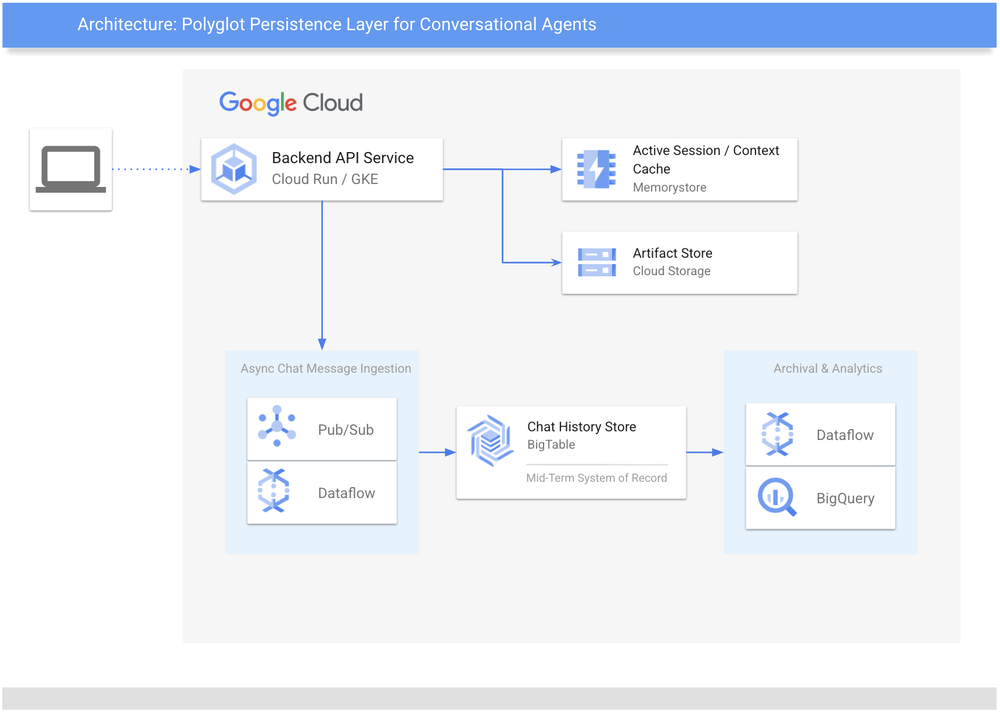
O que é uma abordagem poliglota?
Uma abordagem poliglota utiliza uma estratégia de armazenamento em várias camadas, aproveitando diversos serviços de dados especializados em vez de um único banco de dados genérico para gerenciar diferentes ciclos de vida da informação. Isso permite que a aplicação utilize os pontos fortes específicos de cada ferramenta — como caches in-memory para velocidade, bancos NoSQL para escala, blob storage para artefatos não estruturados e data warehousing para analytics — tratando a "temperatura" e o volume dos dados de forma granular e eficiente.
Definindo a camada de dados no Google Cloud
Para manter a continuidade conversacional, implementamos essa abordagem poliglota utilizando o Memorystore for Redis para recuperação de contexto "hot" com latência de sub-milissegundos, o Cloud Bigtable como system of record em escala de petabytes para histórico durável, e o BigQuery para arquivamento de longo prazo e insights analíticos. O Cloud Storage entra na equação lidando com multimídia não estruturada, enquanto um pipeline assíncrono é construído com Pub/Sub e Dataflow.
1. Memória de curto prazo: Memorystore for Redis
Os usuários esperam que o histórico do chat carregue instantaneamente. Para o contexto imediato da conversa, o Memorystore for Redis atua como o cache primário. Como um data store em memória totalmente gerenciado, ele fornece a baixíssima latência necessária para um fluxo natural. Como sessões de chat expandem de forma incremental, armazenamos o histórico usando Redis Lists. Através do comando nativo RPUSH, a aplicação transmite apenas a mensagem mais recente, evitando ciclos de "read-modify-write" que oneram a rede em soluções mais simples como o Memcached.
2. Memória de médio prazo: Cloud Bigtable
À medida que a conversa evolui, as aplicações agenticas precisam de um armazenamento de maior escala. É aqui que o Bigtable atua como o storage de médio prazo e o system of record definitivo. O Bigtable é um banco NoSQL de escala petabyte projetado para workloads de alta velocidade e escrita intensa, ideal para capturar milhões de interações simultâneas.
Para manter a eficiência operacional, os times podem implementar políticas de garbage collection — retendo, por exemplo, apenas os últimos 60 dias de dados na camada de alta performance. Para acelerar as buscas, utilizamos uma estratégia de chaves com o padrão user_id#session_id#reverse_timestamp. Isso co-localiza todas as mensagens de uma única sessão, permitindo range scans eficientes para recuperar as mensagens mais recentes durante recarregamentos de histórico.
3. Memória de longo prazo e analytics: BigQuery
Para fins de arquivamento e análise profunda, os dados fluem para o BigQuery. Enquanto o Bigtable é otimizado para servir a aplicação live, o BigQuery é o data warehouse serverless do Google focado em consultas SQL complexas. Isso permite que os times transcendam o simples logging e extraiam insights analíticos. No fim do dia, esses dados operacionais tornam-se um feedback loop vital para melhorar o agente e a experiência do usuário sem degradar a performance dos componentes voltados ao cliente.
4. Armazenamento de artefatos: Cloud Storage (GCS)
Dados não estruturados, como arquivos multimídia enviados pelo usuário ou gerados por modelos generativos, residem no Cloud Storage. Utilizamos uma pointer strategy, onde os registros no Redis e no Bigtable contêm um URI pointer (ex: gs://bucket/file) para o objeto. Por segurança, a aplicação serve esses arquivos via signed URLs, fornecendo acesso temporário ao cliente sem expor o bucket publicamente.
Estratégia híbrida Sync-Async para fluxo de dados ideal
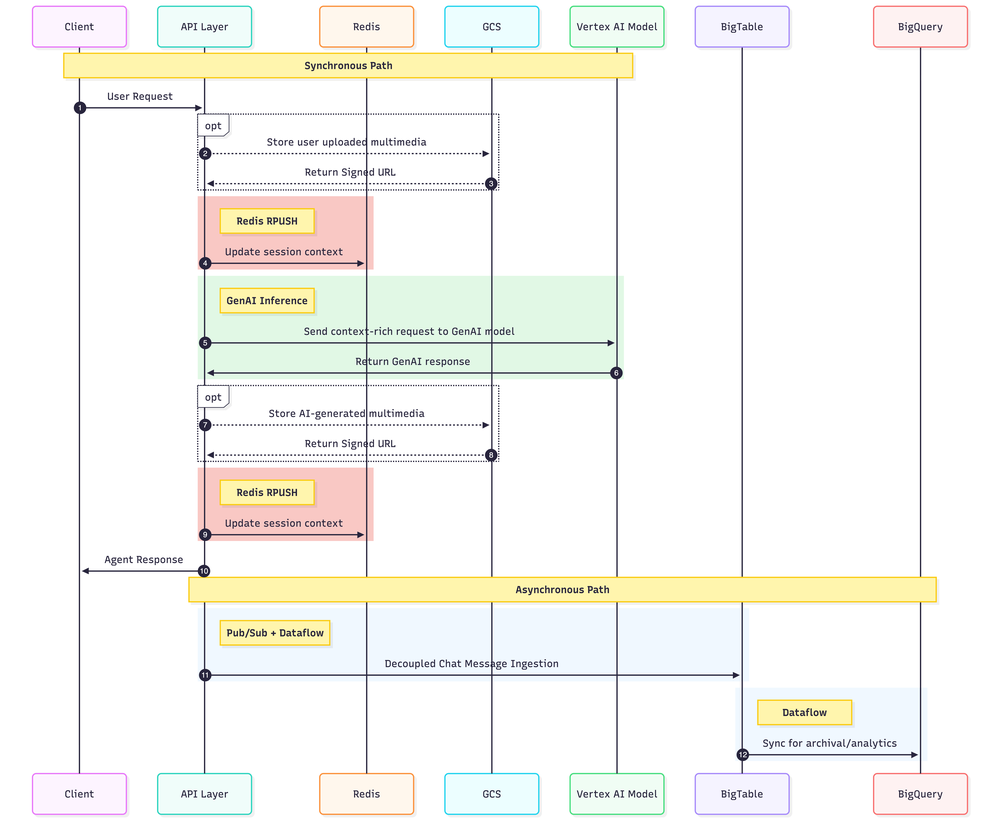
Abaixo, os diagramas de sequência ilustram como a estratégia híbrida equilibra consistência de alta velocidade com persistência durável.
O diagrama a seguir mostra como uma mensagem do usuário e a resposta do agente atravessam a arquitetura:
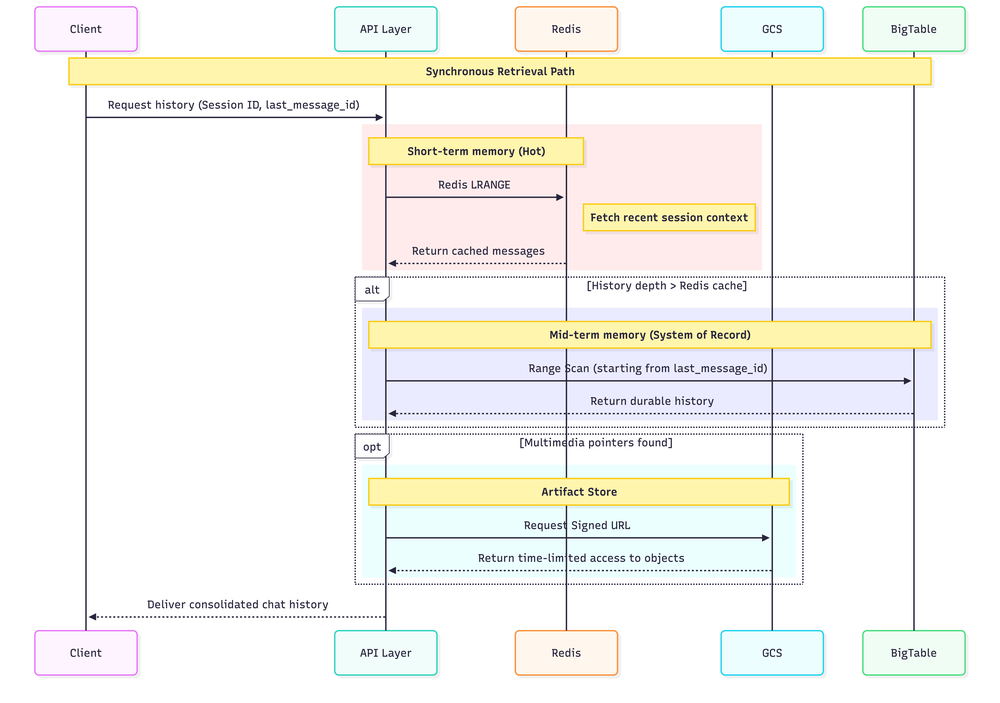
Este segundo diagrama detalha o fluxo de dados quando um usuário solicita a recuperação do histórico de uma sessão específica:
Considerações para Engenharia e Implementação
Se você está pronto para estruturar uma camada de persistência robusta para seus agentes de IA, considere os seguintes passos técnicos:
- Prototipagem de Workflows: Inicie seus fluxos agenticos via Vertex AI Agent Builder para acelerar o time-to-market.
- Configuração de Cache: Avalie as configurações do Memorystore for Redis que melhor atendem aos seus SLAs de latência e disponibilidade.
- Schema Design no Bigtable: O design da Row Key é crítico. Siga as best practices de design de schema para evitar hotspots.
- Integração Analítica: Utilize o template de Bigtable change stream para BigQuery para transformar logs de chat em inteligência de negócio em tempo real.
- Inteligência Conversacional: Explore o Looker Conversational Analytics para basear decisões de produto em dados reais de interação.
Artigo originalmente publicado por Yun Pang em Cloud Blog.
