

Imagine que você tem um LLM rodando em seu cluster Kubernetes. Os pods estão saudáveis, os logs não apresentam erros e a interface de chat responde aos usuários. Aparentemente, tudo está em conformidade.
Contudo, precisamos de uma visão analítica: o Kubernetes é excelente para o orquestramento de workloads e isolamento de processos, mas ele é agnóstico ao conteúdo que processa. Um LLM não é apenas um serviço comum de computação; é um motor que consome inputs não confiáveis e toma decisões baseadas neles. Esse novo paradigma impõe um modelo de ameaças distinto, exigindo controles que o Kubernetes, por si só, não provê.
Entendendo o que você está operando
Considere um deployment típico: você implanta o Ollama em um pod, expõe via Service e conecta uma interface como Open WebUI. Para o seu monitoramento, o sistema está estável.
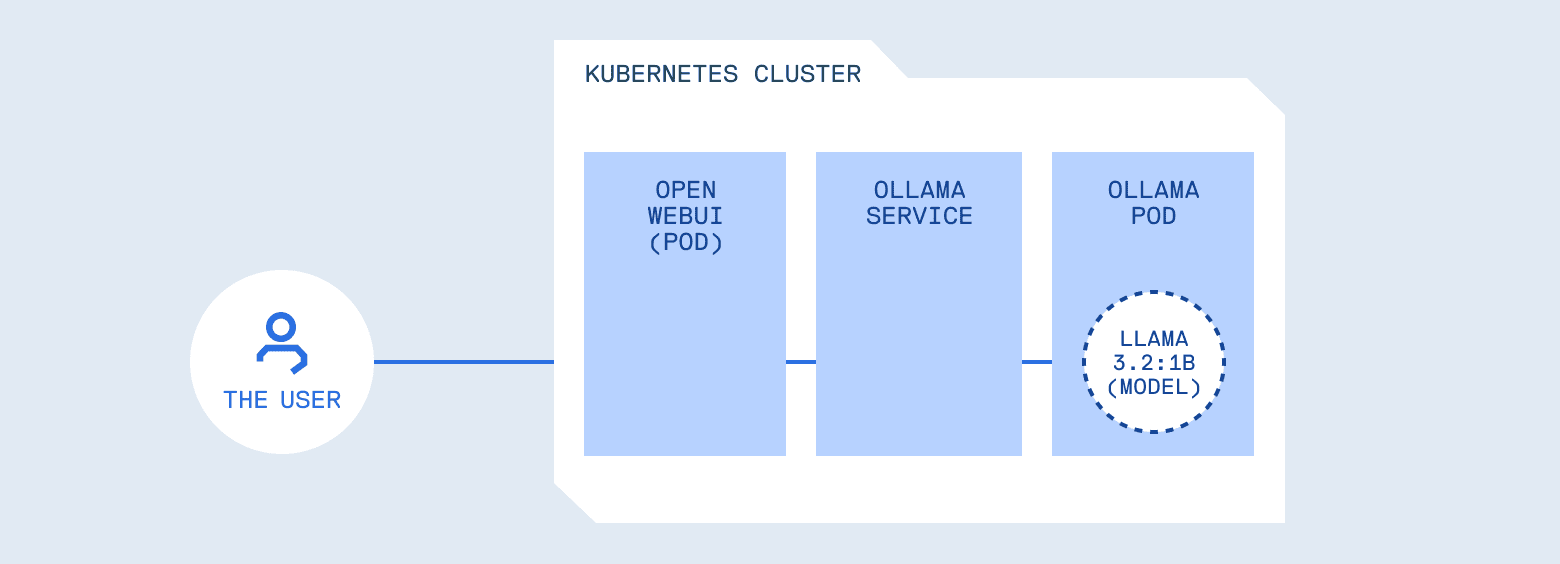
O risco real reside na natureza do que foi construído: um sistema programável com acesso a serviços internos, ferramentas, logs e, potencialmente, credenciais. O Kubernetes cumpriu seu papel de infraestrutura, mas ele não valida se uma prompt é maliciosa, se a resposta contém dados sensíveis ou se o modelo possui privilégios excessivos. A segurança de LLMs assemelha-se à segurança de APIs: a infraestrutura cuida da rede e do isolamento, mas a autenticação, autorização e a higienização de inputs devem ocorrer na camada de aplicação.
OWASP LLM Top 10: O framework de referência
Não podemos tratar LLMs como aplicações legadas. O OWASP Top 10 para aplicações de LLM mapeia riscos críticos, como:
- LLM01: Prompt Injection: Manipulação de comportamento do modelo.
- LLM02: Sensitive Information Disclosure: Vazamento de dados em respostas.
- LLM03: Supply Chain: Uso de modelos de procedência duvidosa.
- LLM04: Data and Model Poisoning: Envenenamento do treinamento.
- LLM05: Improper Output Handling: Confiar cegamente na saída fornecida pelo modelo.
- LLM06: Excessive Agency: Modelos com autonomia perigosa.
- LLM07: System Prompt Leakage: Exposição das instruções de sistema.
- LLM08: Vector and Embedding Weaknesses: Vulnerabilidades em sistemas de RAG.
- LLM09: Misinformation: Geração de dados falsos.
- LLM10: Unbounded Consumption: Negação de serviço por consumo excessivo de recursos.
Quatro riscos críticos para operadores Kubernetes
1. Prompt Injection (LLM01)
Assim como o SQL Injection, o Prompt Injection explora a confiança cega do sistema no input do usuário. Operacionalmente, você precisa implementar mecanismos de validação de input que entendam a natureza probabilística da linguagem natural, indo além das regras padrões de WAFs.
2. Sensitive Information Disclosure (LLM02)
Um modelo pode, facilmente, exibir chaves de API se elas estiverem acessíveis no prompt original ou em documentos indexados. A solução é técnica: você precisa de filtros de saída (output scrubbing) que funcionam de maneira similar à higienização de logs para evitar vazamento de segredos.
3. Supply Chain Risks (LLM03)
Modelos são "caixas pretas". Diferente de um repositório Git, você não audita o código-fonte manualmente. O gerenciamento de supply chain aqui foca na governança: uso de registries verificados, versionamento rígido e verificação de assinatura (provenance) para evitar modelos comprometidos ou com viés malicioso.
4. Excessive Agency (LLM06)
Se o seu LLM pode disparar comandos, ele deve seguir o princípio do privilégio mínimo. Evite dar acessos administrativos ao pod do LLM. O IAM do seu provedor cloud ou políticas de RBAC no K8s devem restringir drasticamente o que o modelo pode executar.
Onde a política deve residir?
O runtime do modelo (ex: Ollama) tem apenas uma função: inferência. Colocar regras de segurança dentro dele é um erro de design (cobblestone coupling). A estratégia recomendada é a adoção de um AI Gateway entre o cliente e o serviço de inferência.
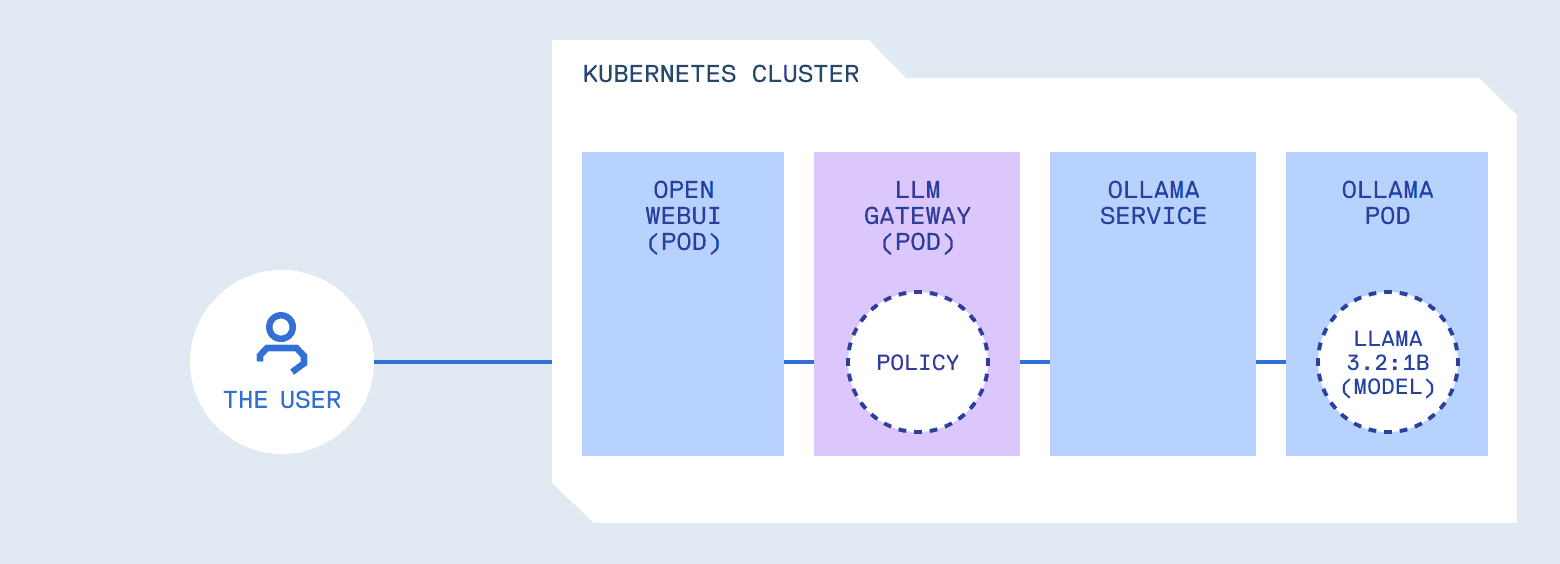
Escolhendo sua camada de políticas
Para empresas que buscam controle, o mercado oferece opções robustas na camada de Gateway:
- LiteLLM: Excelente para unificar APIs e gerenciar custos.
- Kong AI Gateway: Ideal para quem já escala com infraestrutura Kong.
- Portkey: Focado em observabilidade e caching.
- kgateway: A escolha para quem prioriza o Gateway API padrão do Kubernetes.
No nosso próximo artigo, detalharemos como implementar esses controles na prática, focando em detecção de injeção e governança de artefatos de IA.
Artigo originalmente publicado por Nigel Douglas, CloudSmith em Cloud Native Computing Foundation.
