

Para empresas que operam na linha de frente da Inteligência Artificial, o maior desafio atual não é apenas treinar modelos, mas sustentá-los em ambientes de produção com estabilidade e eficiência. O Google Cloud tem focado sua estratégia de infraestrutura em atender essas necessidades massivas, e a recente aceitação do llm-d como projeto Sandbox da Cloud Native Computing Foundation (CNCF) — com contribuições diretas do Google, Red Hat, IBM Research, CoreWeave e NVIDIA — é um marco que sinaliza uma mudança de paradigma: o movimento rumo ao lema "any model, any accelerator, any cloud".
Essa iniciativa representa um esforço crítico para evitar o isolamento em walled gardens. Para CTOs e líderes de engenharia no Brasil, a entrada do llm-d sob a tutela da Linux Foundation traz a segurança de que o futuro da inferência distribuída será fundado em padrões abertos, mitigando riscos de vendor lock-in e permitindo que cargas de trabalho sejam otimizadas em qualquer provedor de nuvem.
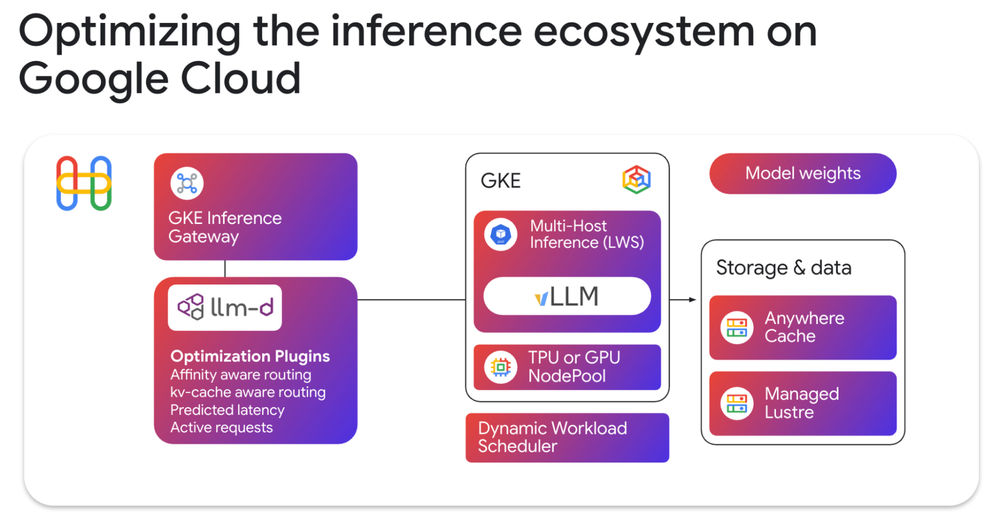
Otimizando o Kubernetes para alta carga de inferência
Embora o Kubernetes seja o padrão para orquestração, ele carece, nativamente, de mecanismos para lidar com a natureza altamente stateful das demandas de LLMs. O lançamento do GKE Inference Gateway é a resposta do Google Cloud a essa lacuna, utilizando o Endpoint Picker (EPP) do llm-d para elevar o nível do roteamento. Ao contrário de load balancers tradicionais, essa camada considera métricas como taxas de hit no KV-cache e latência de fila, garantindo que o request seja roteado para o backend mais capaz de processá-lo naquele milissegundo exato.
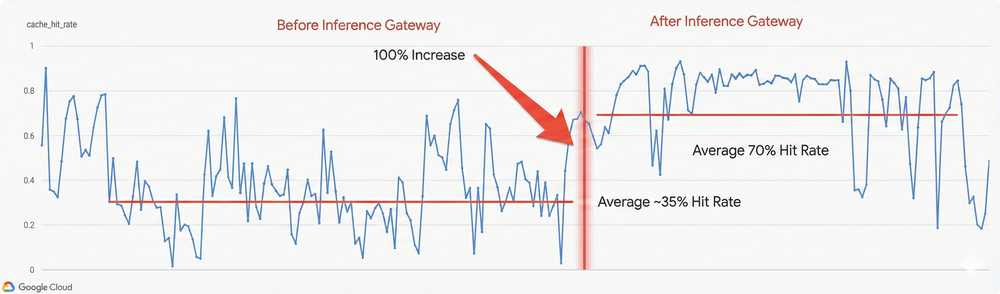
Para times de engenharia, os resultados práticos dessa inteligência de roteamento são volumosos. Implementações reais no Vertex AI demonstraram reduções de 35% no Time-to-First-Token (TTFT) para tarefas de codificação e uma melhora de 52% no P95 de latência para workloads bursty. Mais importante: o ganho na eficiência do prefix cache hit rate, que saltou de 35% para 70%, impacta diretamente o custo-por-token, um KPI fundamental para qualquer operação de FinOps em IA.
Além do roteamento, a orquestração de inferência em multinó exige primitivas robustas. O uso da API LeaderWorkerSet (LWS) permite que o llm-d desmembre fases computacionalmente intensivas (prefill) de fases intensivas em memória (decode) em pods escaláveis de forma independente. Com o suporte nativo do vLLM para Cloud TPUs e inovações como o Ragged Paged Attention v3, o ecossistema está entregando ganhos de throughput de até 5x, tornando o Kubernetes uma plataforma de execução de IA de classe mundial.
Construindo a infraestrutura para a próxima geração de IA
O desafio de levar GenAI para produção exige a ponte entre a agilidade do cloud-native e os requisitos rigorosos dos modelos de fronteira. A adoção do llm-d pela CNCF não é apenas uma notícia técnica; é uma oportunidade para empresas brasileiras adotarem blueprints testados (os chamados "well-lit paths") para suas arquiteturas.
Para quem busca evoluir, o caminho envolve explorar os guias do llm-d, participar da comunidade no GitHub e, fundamentalmente, alinhar a infraestrutura de orquestração com a maturidade que a complexidade da IA hoje exige.
Artigo originalmente publicado por Abdel SghiouarSenior Cloud Developer Advocate em Cloud Blog.
