

No Google Cloud Next '26, o Google apresentou uma atualização relevante para gestores de infraestrutura e engenharia: uma reestruturação da sua stack de armazenamento focada na triade de performance, inteligência e gerenciamento. Para empresas brasileiras que buscam escalar modelos de IA ou aplicações data-intensive, o anúncio transcende o marketing e toca em um ponto crítico: a latência e o throughput entre o storage e os aceleradores.
Storage como motor, não apenas repositório
Historicamente, o storage era visto como um destino passivo. Na era da IA, essa visão é técnica e financeiramente perigosa. Se o pipeline de dados não alimenta os GPUs na velocidade necessária, a conta não fecha: você paga pelo uptime de instâncias caras que permanecem ociosas. A nova estratégia do Google foca em integrar inteligência na camada de dados, reduzindo o custo total de propriedade (TCO) ao otimizar a movimentação de dados para modelos e agentes.
As principais novidades incluem a família Cloud Storage Rapid, melhorias no Google Cloud Managed Lustre e capacidades nativas de Smart Storage para annotating dados de forma automatizada.
Infraestrutura de alta performance: O fim do trade-off
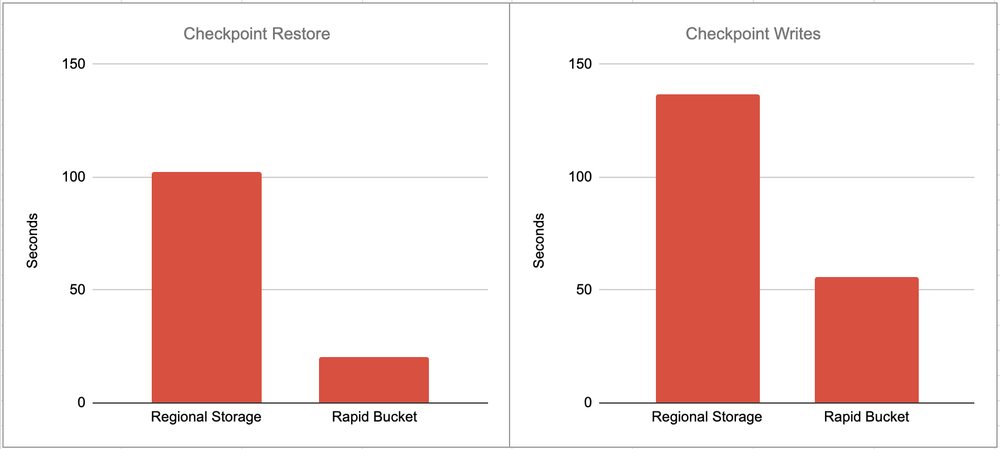
O grande desafio até hoje era a escolha entre a durabilidade do object storage e a performance de sistemas especializados. O Cloud Storage Rapid (com Rapid Bucket e Rapid Cache) promete mudar esse cenário. Com a tecnologia Colossus por trás, o Rapid Bucket entrega até 15 TB/s de banda e sub-milissegundos de latência. Na prática, isso significa uma redução de 50% no tempo em que GPUs ficam bloqueadas esperando dados — um ganho direto de ROI para times de Data Science.
Para cenários que exigem extrema performance, o Managed Lustre agora suporta 10 TB/s de throughput com o novo Dynamic Tier. Esta é uma atualização vital para empresas de médio e grande porte no Brasil que operam em ambientes HPC (High Performance Computing) ou processam grandes volumes de LLMs.
Smart Storage e a era do dado autodescritivo
Um dos pontos mais interessantes para equipes de Engenharia de Dados é o amadurecimento do Smart Storage. A capacidade de realizar automated annotations elimina a necessidade de construir e manter pipelines customizados para catalogar dados. Ao tornar o dado autodescritivo no momento do write, o Google permite que agentes de IA acessem metadados de contexto sem sobrecarregar a camada de compute com processos de busca e indexação.

Gestão e Ecossistema
Além da performance bruta, o Google está consolidando o gerenciamento via Storage Intelligence. Com zero-configuration dashboards integrados ao Security Command Center (DSPM), a visibilidade sobre custos e vetores de risco (como permissões IAM em objetos expostos) torna-se muito mais tangível. Para empresas que operam em regime de conformidade rigorosa, como o setor financeiro ou de saúde no Brasil, a capacidade de identificar anomalias de acesso em escalas de bilhões de objetos é um diferencial de segurança relevante.
Por fim, melhorias no NetApp Volumes e Filestore for GKE facilitam a transição entre ambientes on-premises e nuvem, permitindo que times de DevOps apliquem automação via Terraform e APIs ONTAP de forma consistente em ambientes multi-cloud ou híbridos.
Artigo originalmente publicado por Asad Khan, Sr. Director of Product Management, Google Cloud em Cloud Blog.
