

A IA deixou de ser um mecanismo passivo de respostas para se tornar um sistema de raciocínio orientado a ações. Para empresas que buscam liderança na chamada "era dos agentes", a estratégia de infraestrutura não pode mais ser baseada em componentes isolados. O desafio agora é sustentar um fluxo onde um objetivo de negócio ativa cadeias de agentes especializados que colaboram em tempo real, preservando estados e operando através de reinforcement learning.
Escalar essa complexidade sem ver os custos de cloud dispararem ou encontrar gargalos críticos de latency exige uma visão de AI Hypercomputer. Não se trata apenas de provisionar mais instâncias, mas de integrar hardware, software open-source e modelos de consumo flexíveis. Abaixo, analisamos o que essa atualização no portfólio do Google Cloud significa na prática para a sua engenharia.
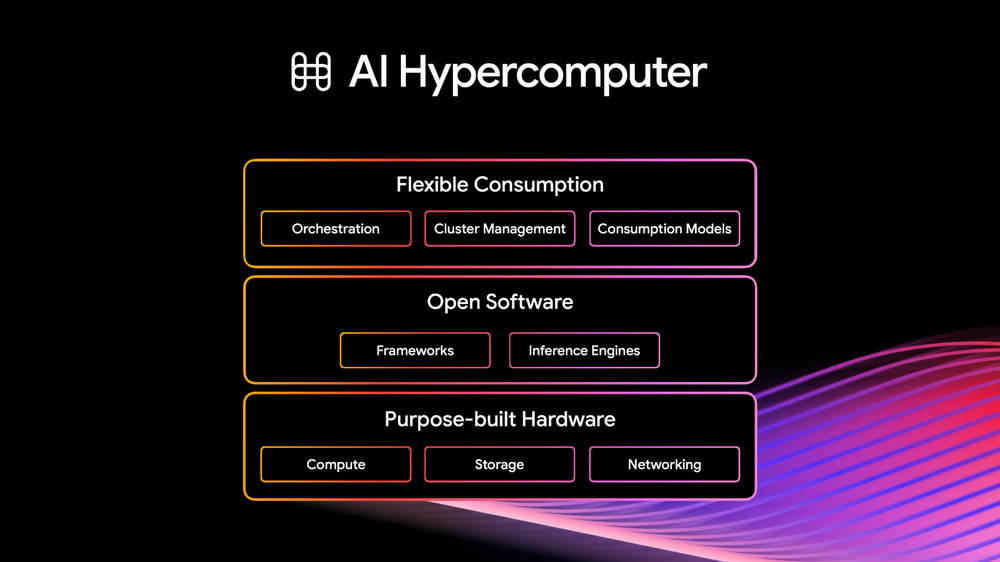
O foco no hardware: TPU 8t e TPU 8i
O anúncio da oitava geração de TPUs separa claramente dois mundos: o TPU 8t como força bruta para training (com ganhos de escala massivos via inter-chip interconnects) e o TPU 8i focado em inferência e RL. Para gestores de TI, o ponto de atenção no TPU 8i é a redução de latency através do aumento de HBM e SRAM local, o que permite manter o KV Cache no nível do silício. Isso resolve um gargalo comum em aplicações de larga escala que sofrem com o overhead de memória.
A rede e o armazenamento como base de performance
A introdução da Virgo Network é o movimento mais estratégico para quem opera clusters de grande porte. A arquitetura de fabric eliminando o "taxa de escala" permite conectar até 1 milhão de TPUs em um único training cluster. Paralelamente, o Google Cloud Managed Lustre atingindo 10 TB/s de largura de banda remove o gargalo de I/O que frequentemente subutiliza instâncias de alta computação, garantindo um TCO mais eficiente — um tópico vital para estratégias de FinOps.
GKE e a orquestração de "Agentes-Nativos"
A transformação do GKE (Google Kubernetes Engine) em uma plataforma otimizada para agentes é um movimento direto para times de DevOps. A redução de 80% no tempo de startup dos pods e a utilização de AI-powered Inference Gateway com roteamento consciente de latency muda o jogo para aplicações que dependem de respostas em tempo real. A adoção de frameworks como o llm-d (projeto CNCF Sandbox) reforça que o ecossistema está se movendo para uma padronização agnóstica ao acelerador.

Para o mercado brasileiro, o impacto é claro: a barreira de entrada para treinar modelos customizados está baixando, mas a complexidade da gestão dessa infraestrutura aumentou. O foco agora deve ser na automação da stack de orquestração e na escolha do hardware correto (seja TPU, A5X/NVIDIA ou instâncias Axion para lógica de orquestração) para evitar desperdícios em instâncias inadequadas para a carga de trabalho.
Artigo originalmente publicado por Mark LohmeyerVP and GM, AI and Computing Infrastructure em Cloud Blog.
