

Para atingir os níveis 4 e 5 de Operações de Rede Autônoma (ANO), o setor de telecomunicações está recorrendo cada vez mais à IA para construir redes de autorrecuperação e auto-otimização, capazes de manutenção preditiva.
No entanto, existe um obstáculo significativo: a IA é tão boa quanto os dados que a alimentam. Enquanto a indústria se concentra em agentes de IA, Large Language Models (LLMs) e AIOps, os dados subjacentes permanecem desorganizados e fragmentados. Não se constrói um modelo de IA válido sobre dados corrompidos.
Hoje, analisamos a nova colaboração entre o Google Cloud e a DigitalRoute, provedora de plataforma de monetização e uso de dados, para resolver um dos maiores gargalos do setor: a preparação de dados (data readiness). Estão sendo lançados pipelines de dados reutilizáveis que transformam o ruído bruto e caótico da rede em dados de alta qualidade e "AI-ready", viabilizando a próxima geração de agentes autônomos.
Saindo de "Data Swamps" para Digital Twins
Antes que um agente de IA possa resolver uma anomalia de rede, ele precisa primeiro entender o ambiente. Em uma rede de telecomunicações moderna, isso representa um desafio massivo de engenharia por quatro razões principais:
- Disparidade de formatos: Os dados de rede chegam em dezenas de formatos proprietários (ex: ASN.1, XML, CSV, Binary) que variam de acordo com o vendor e o domínio. A IA não consegue ler isso sem um tradutor.
- Volume e velocidade: Redes 5G geram bilhões de registros de cobrança e eventos diariamente. Processar isso em tempo real com ultra-low latency pode sobrecarregar sistemas de mediação legados.
- Evolução de schema: Cada vez que uma função de rede é atualizada ou um novo recurso 5G é implementado, a estrutura de dados subjacente muda. Isso geralmente causa o "quebra" de sistemas de dados tradicionais.
- Complexidade de correlação: Uma única sessão de cliente é frequentemente fragmentada em múltiplos elementos de rede. Sem costurar esses fragmentos, a IA carece de contexto para entender a experiência real do usuário.
O resultado é um "data swamp" (pântano de dados) — volumes massivos de informações não refinadas que os modelos de IA não conseguem utilizar de forma eficaz.
A solução: Uma arquitetura cloud-native para prontidão de dados
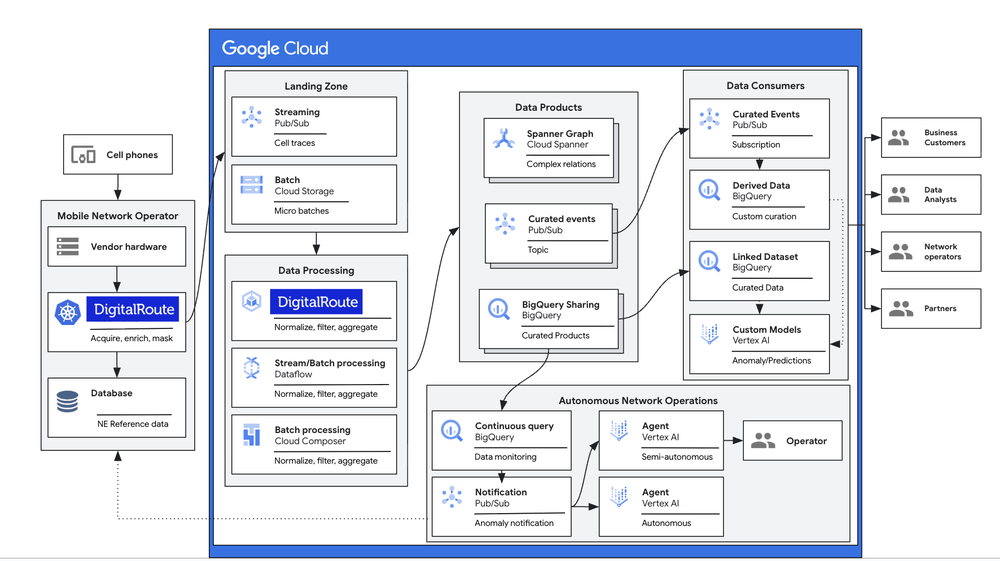
Para enfrentar isso, foi desenhada uma arquitetura com a DigitalRoute que conecta protocolos de telecomunicações legados à inteligência cloud-native. Ao executar o Usage Engine Private Edition da DigitalRoute no Google Kubernetes Engine (GKE), criamos um pipeline reutilizável que escala dinamicamente entre locais de edge e cloud.
Esta arquitetura oferece três vantagens estratégicas:
- Normalização no edge e no core: Decodificamos mensagens binárias complexas em um common data model unificado e filtramos o ruído irrelevante antes que ele chegue ao storage. Isso garante que a IA downstream seja desacoplada de restrições específicas de vendors, reduzindo significativamente os custos de data egress.
-
Estratégia de "caminho duplo" (dual-path): Uma vez normalizados, os dados fluem para dois ambientes especializados:
- Para operações em tempo real: Os dados são enviados ao Spanner para construir um "digital twin da rede". Isso permite que agentes de IA analisem a topologia da rede ao longo do tempo para realizar um rápido root cause analysis.
- Para analytics de longo prazo: Dados históricos fluem para o BigQuery. Como o BigQuery é serverless e escala instantaneamente, permite que operadoras analisem petabytes de tráfego sem gerenciar infraestrutura, alimentando 'data products' diretamente no Vertex AI para treinamento rápido de modelos.
-
Traces de assinantes contextualizados: Através da solução Network and Subscriber Trace Analysis (NSTA), alinhamos mensagens de diferentes nodes baseadas em timestamps e identificadores. Isso constrói um fluxo de sessão cronológico e coerente, dando aos agentes de IA o contexto end-to-end da jornada do assinante.
Essa arquitetura garante que, se um agente de IA precisar reagir a um corte de fibra quase em tempo real (via Spanner) ou prever um gargalo de capacidade no próximo mês (via BigQuery e Vertex AI), ele estará sempre consumindo dados consistentes e de alta qualidade.
Do dado ao resultado: Viabilizando agentes autônomos
Esta parceria foca em habilitar casos de uso de IA em nível de produção. Ao estabelecer esses pipelines reutilizáveis, fornecemos a base para:
- Detecção rápida de anomalias: Agentes podem detectar desvios sutis na performance da rede porque os dados de baseline são consistentes e livres de ruído.
- Análise de causa raiz automatizada: Quando ocorre uma falha, os agentes podem correlacionar problemas de Radio Access Network (RAN) com dados de core trace instantaneamente para identificar a correção.
- Manutenção preditiva: Usando dados históricos no BigQuery, operadoras podem treinar Graph Neural Networks (GNN) para prever gargalos de capacidade com dias de antecedência.
Acelere sua missão de rede autônoma
A prontidão de dados é a diferença entre um "projeto de laboratório" e uma rede autônoma de nível de produção. Ao padronizar a camada de ingestão hoje, as empresas de telecomunicações podem construir a base essencial para as redes movidas a IA de amanhã.
Artigo originalmente publicado por Naresh Rao, Senior Product Manager em Cloud Blog.
