

Start with the framework, accelerate with the tool
O Application Resilience Framework surgiu da necessidade real observada em consultorias de resiliência: muitas equipes possuem diagramas arquiteturais, dados de monitoramento e runbooks, mas falta um elo técnico que conecte tudo isso a um modelo quantitativo.
O objetivo do framework é preencher essa lacuna, transformando o contexto arquitetural em um ciclo de vida estruturado, abrangendo risk identification, mitigation validation, health modeling, and governance. Ele é um complemento direto ao pilar de Reliability do Azure Well-Architected Framework, focando na implementação prática de Failure Mode Analysis e definição de metas de disponibilidade.
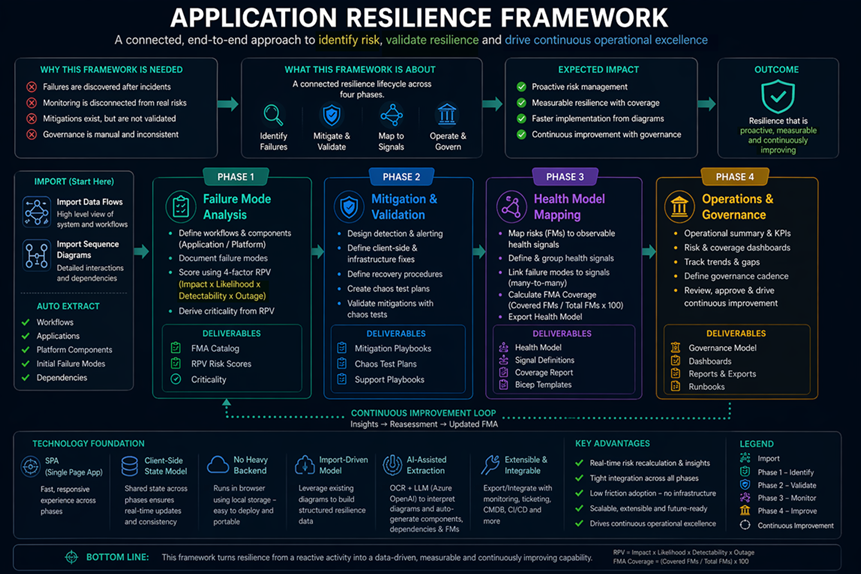
O Application Resilience Framework Tool acelera a aplicação desse framework ao consumir artefatos já existentes, como Mermaid ou imagens de diagramas de fluxo de dados/sequência. A ferramenta extrai componentes e dependências para guiar a equipe em um processo que segue quatro fases fundamentais:
- Import Artifacts: O ponto de partida para a ingestão da arquitetura.
- Phase 1: Failure Mode Analysis: Onde identificamos o que pode falhar e quão crítico isso é.
- Phase 2: Mitigation and Validation: Onde criamos planos documentados e, crucialmente, testados.
- Phase 3: Health Model Mapping: Conexão entre riscos e sinais de observabilidade.
- Phase 4: Operations and Governance: Manutenção do modelo como parte viva do dia a dia de SRE.
Como usar este guia
Este guia segue o fluxo da ferramenta, focando em:
- The decision: A escolha estratégica necessária.
- The options: Os caminhos disponíveis.
- The guidance: Quando aplicar cada cenário.
Question 1: What artifact should you import first?
O passo de importação é o ponto zero. O objetivo é converter representações estáticas em fluxos de trabalho (workflows) prontos para análise.
| Import option | Best for | What happens |
|---|---|---|
| Data flow diagram | System, module, data movement, and dependency views | Converte-se em fluxos estilo sequência para análise. |
| Sequence diagram | Transaction flow and service interaction views | Conversão direta para workflows. |
| Mermaid input | Diagrams maintained as code in Mermaid format | Conversão direta para workflows. |
| Image input | JPG or PNG diagrams | Utiliza Azure Foundry Vision para interpretação e conversão. |
| Manual entry | Missing or incomplete diagrams | Criação e correção manual. |
Question 2: Which workflows should be analyzed first?
A Failure Mode Analysis não deve tentar cobrir todos os aspectos do sistema de uma só vez. A priorização é estratégica:
- Critical user flows: Login, checkout, pagamentos, onboarding.
- High-risk platform flows: Operações em banco de dados, filas, identidade, APIs externas.
- Known issue areas: Workflows com histórico recente de incidentes ou alertas recorrentes.
Question 3: How should failure modes be prioritized?
Score cada modo de falha utilizando Risk Priority Value (RPV), equilibrando Impacto, Probabilidade, Detectabilidade e Severidade.
- Use o modelo gerado para uma visão rápida.
- Ajuste os scores RPV com o contexto da equipe técnica.
- Adicione modos de falha personalizados baseados em vivência operacional.
Question 4: Are mitigations defined or validated?
Mitigação sem validação é suposição. O roadmap é claro:
- Detection only: Sabemos do problema, mas não temos o plano de reação.
- Defined mitigation: Plano documentado (retry, fallback, failover).
- Validated mitigation: Plano testado e comprovado via, por exemplo, chaos test.
Question 5: Which risks need health signals?
Phase 3: Health Model Mapping. Conectamos o risco ao dado. Todo modo de falha crítico deve ter um sinal claro (métrica, log, alerta, disponibilidade) que indique um sistema saudável ou degradado.
Question 6: Should the health model be exported or deployed?
- Export for review: Validação humana antes da implementação.
- Generate monitoring templates: Padronização da implementação.
- Deploy to Azure: O modelo integrado diretamente às operações de TI.
Question 7: How will governance keep the model current?
A resiliência é um estado, não um projeto. Utilize:
- Recurring review: Cadência periódica de revisão.
- Closed-loop governance: Incidentes, falhas de testes e gaps de monitoramento geram ciclos de feedback automáticos para alimentar o modelo.
Putting it together: three adoption patterns
- Pattern A: Quick resilience review: Revisão rápida e early-stage.
- Pattern B: Full workload assessment: Assessment completo com planos de chaos testing.
- Pattern C: Operational health model: Focado em melhoria contínua e SRE de longo prazo.
A short checklist before using the tool
- Temos o mapeamento de dependências bem definido?
- Como o nosso RPV foi ajustado ao contexto da carga de trabalho?
- As mitigações foram realmente validadas através de testes?
- Quais gaps de observabilidade (health signals) ainda persistem?
- Quem assume a propriedade e a cadência de revisão deste modelo?
Closing thought
O Application Resilience Framework Tool é um catalisador prático para elevar a maturidade de SRE. A chave não é a ferramenta em si, mas a mudança de cultura: sair de documentos estáticos para uma visão de resiliência viva e mensurável.
Tool repo: Application Resilience Framework Tool
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
