

Para engenheiros de plataforma, líderes de infraestrutura de IA e desenvolvedores, o objetivo ao escalonar workloads no Kubernetes é pragmático: garantir capacidade no momento certo, com a melhor eficiência de custo possível.
No entanto, enquanto o escalonamento baseado em CPU e memória é trivial, configurar o escalonamento por sinais da aplicação — como profundidade de fila (queue depth) ou requisições ativas — historicamente tem sido um desafio. No Brasil, onde a eficiência operacional é crucial para a competitividade, a complexidade de configurar monitoramento, IAM e agentes específicos criava um overhead operacional proibitivo.
A Google Cloud está removendo esse atrito com o suporte nativo a custom metrics para o Horizontal Pod Autoscaler (HPA) no Google Kubernetes Engine (GKE). Trata-se de uma evolução que transforma sinais customizados de workloads em uma funcionalidade nativa da plataforma.
O desafio atual: O "imposto" das métricas customizadas
Se você já tentou escalonar um workload com base em métricas de negócio ou técnicas específicas (como requisições ativas, KV Cache ou contagem de jogadores em um servidor de games), sabe que a arquitetura necessária é surpreendentemente pesada. Não se trata apenas de algumas linhas de YAML; é necessário orquestrar sistemas distintos.
Atualmente, para fazer o HPA rodar com métricas customizadas, é preciso configurar diversos componentes:
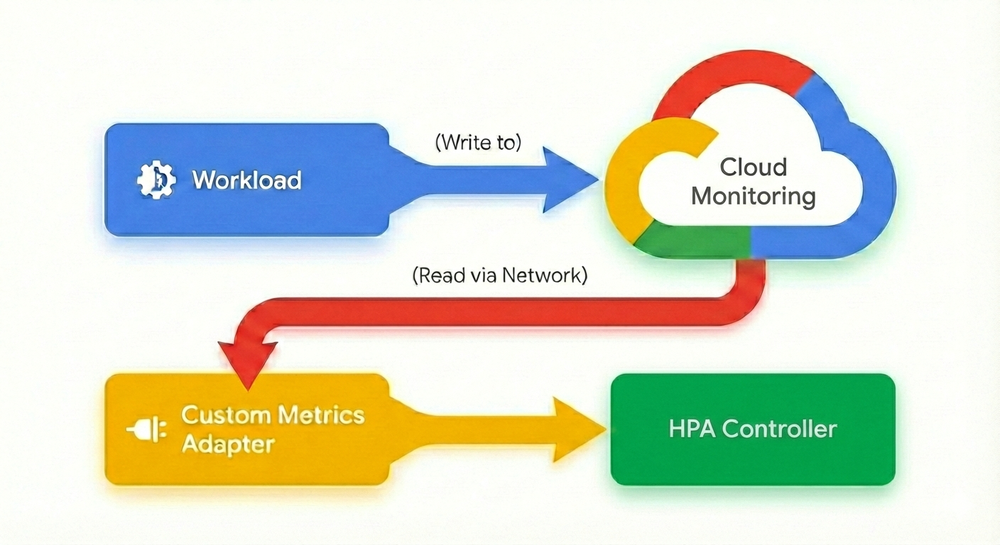
- Exportar a métrica: Configurar o Pod para enviar métricas ao Cloud Monitoring, Google Managed Prometheus ou outro sistema.
- Configurar o "intermediário": Instalar e gerenciar o
custom-metrics-stackdriver-adapterou oprometheus-adapterno cluster para traduzir os dados para o HPA. A manutenção desses adaptadores é complexa e propensa a erros. - Navegar no labirinto de IAM: Este é, muitas vezes, o maior obstáculo. Para permitir que o adaptador leia as métricas, você deve:
- Habilitar o Workload Identity Federation no cluster.
- Criar uma Google Cloud IAM Service Account.
- Criar e anotar uma Kubernetes Service Account.
- Vincular as contas via IAM policy binding.
- Conceder roles específicas de IAM.
- Gerenciar o risco operacional: A lógica de autoscaling passa a depender da disponibilidade do stack de observabilidade. Se houver lag na ingestão ou falha no adaptador, o escalonamento quebra.
Na prática, isso cria uma dependência circular perigosa. Se o sistema de monitoramento falha, seu workload para de escalonar, reduzindo a resiliência do serviço — algo que vai contra as melhores práticas de infraestrutura crítica.
Escalabilidade nativa e sem agentes
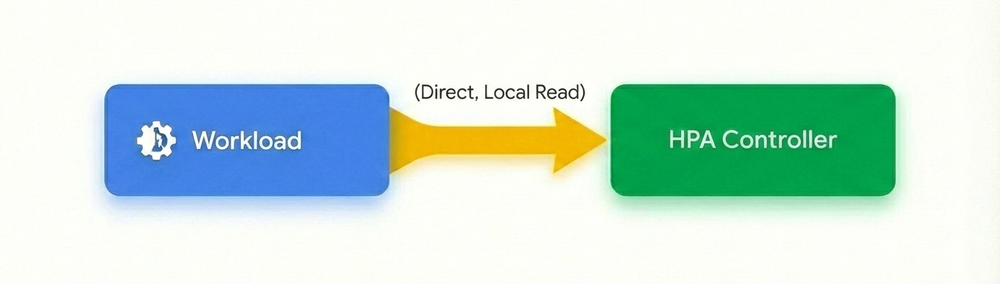
Com o suporte nativo no GKE, o fluxo de autoscaling foi redesenhado para eliminar intermediários. Escalonar workloads baseando-se em métricas em tempo real agora é tão simples quanto configurar memória ou CPU, sem dependências circulares de IAM ou adaptadores.
Sem agentes, sem adaptadores, sem IAM complexo: As custom metrics agora são extraídas diretamente dos seus Pods e entregues ao HPA. Com essa arquitetura agentless, não há necessidade de manter adaptadores ou vínculos complexos de Workload Identity.
Suporte nativo para métricas customizadas:
Para empresas brasileiras que operam workloads exigentes — como inferência de IA, serviços financeiros com picos de transações, varejo (e-commerce) e gaming — esta atualização é um divisor de águas:
- Fim do "Middleman": Elimina a complexidade de sidecars e roles de IAM. Se sua aplicação expõe a métrica, o GKE escala.
- Latência reduzida: Ao eliminar o round trip para um sistema externo de monitoramento, o HPA reage muito mais rápido, essencial para evitar a degradação do serviço durante rajadas de tráfego (bursts).
- Eficiência de custos (FinOps): Reduz custos de ingestão de métricas que serviriam apenas para decisões de autoscaling. Além disso, a precisão no escalonamento evita o desperdício de recursos de computação.
- Confiabilidade aprimorada: A lógica de escalonamento torna-se autocontida no cluster, não dependendo do uptime de ferramentas externas.
Para simplificar a coleta, um novo controller permite configurar quais métricas o HPA deve observar:
apiVersion: autoscaling.gke.io/v1beta1
kind: AutoscalingMetric
metadata:
name: vllm-autoscaling-metric
namespace: autoscaling-metrics
spec:
metrics:
- pod:
selector:
matchLabels:
app: vllm-metrics
containers:
- endpoint:
port: metrics
path: /metrics
metrics:
- gauge:
name: kv_cache_usage_perc
prometheusMetricName: vllm:kv_cache_usage_perc
filter:
matchLabels:
label: v1
Com a configuração criada, basta apontar o HPA para a métrica definida através do controller AutoscalingMetric:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
...
metrics:
- type: Pods
pods:
metric:
name: autoscaling.gke.io|vllm-autoscaling-metric|kv_cache_usage_perc
Conclusão: O caminho para o Intent-Based Autoscaling
Este lançamento é o primeiro passo em direção ao intent-based autoscaling, onde se define a performance desejada (similar aos SLOs) em vez de apenas limites de recursos. Seja para otimizar o uso de GPUs em LLMs ou gerenciar jobs batch voláteis, o GKE agora permite expressar estratégias de escalonamento baseadas na realidade operacional do seu negócio.
Artigo originalmente publicado por Nabil Dabouz em Cloud Blog.
