

A explosão dos Large Language Models (LLMs) elevou a demanda por aceleradores de alta performance, como GPUs e TPUs, a um novo patamar. Para empresas que sustentam suas operações em modelos de IA, a escassez de poder computacional não é apenas um desafio de custo: é um gargalo operacional que exige gestão precisa de cada ciclo de processamento.
O Kubernetes consolidou-se como o padrão para rodar cargas de trabalho de IA em escala. Recentemente, a adoção de drivers de Dynamic Resource Allocation (DRA) por grandes players — com NVIDIA e Google doando tecnologias para a comunidade — sinaliza uma mudança estrutural necessária. Mais do que um anúncio de funcionalidade, o DRA representa uma modernização na forma como o orquestrador lida com hardware, algo que times de engenharia no Brasil devem observar atentamente para garantir a portabilidade e a eficiência de seus clusters.
Superando a era da infraestrutura estática
Por anos, o framework de Device Plugins foi o padrão de mercado para expor aceleradores de hardware ao Kubernetes. No entanto, ele impõe limitações restritivas: a capacidade é tratada como um inteiro simples (ex: gpu: 1), sem suporte nativo a fractional GPUs ou granularidade fina. Além disso, o modelo exige que o cluster tenha o hardware pré-provisionado antes que o pod seja agendado, gerando atrito operacional.
Com o status de “estável” alcançado no Kubernetes 1.34, o DRA muda o jogo. Ele transita de um modelo de alocação estática para um baseado em requisições dinâmicas, endereçando problemas críticos:
- Fim do node pinning manual: O scheduler agora é nativamente consciente das capacidades do hardware, eliminando a dependência de nodeSelectors ou affinities espalhados pelo código.
- Flexibilidade e parametrização: Diferente do modelo "tudo ou nada", o DRA permite definir requisitos técnicos granulares (memória VRAM mínima, modelo específico ou topologia de interconexão) via ResourceClaims.
- Abstração via DeviceClasses: Platform admins podem definir blueprints de hardware. Isso desacopla a demanda do desenvolvedor da infraestrutura subjacente, permitindo que a mesma
DeviceClassatenda diferentes modelos de hardware conforme a disponibilidade.
Mergulho técnico: Como o DRA opera
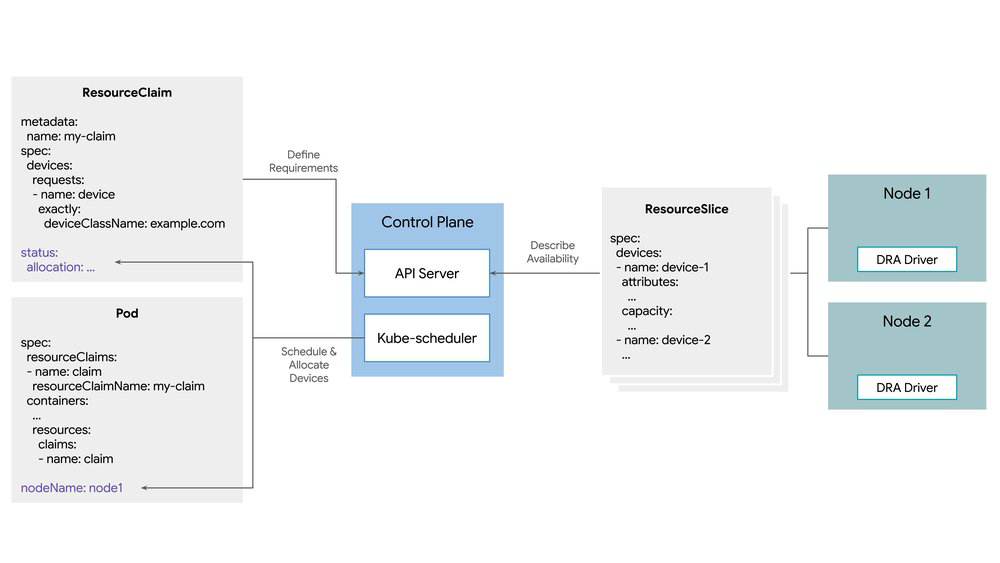
O DRA introduz dois pilares que, estrategistas de TI devem notar, separam a camada de inventário da camada de requisitos: ResourceSlice e ResourceClaim.
ResourceSlice: A visibilidade do inventário
Este API permite que os resource drivers publiquem os atributos reais do hardware. Ao contrário do que ocorria com Device Plugins, que frequentemente escondiam detalhes técnicos sob labels genéricas, o ResourceSlice expõe métricas de alta fidelidade como arquitetura, versão de hardware e topologia de NUMA.
ResourceClaim: A definição precisa da demanda
Já o ResourceClaim permite ao time de engenharia de dados declarar o que a carga de trabalho exige, não o que ela espera encontrar. É aqui que ganham força as seleções baseadas em atributos (ex: "qualquer GPU com pelo menos 40 GB de VRAM") e as restrições complexas — como garantir que uma GPU e uma NIC estejam no mesmo barramento PCIe para minimizar latency e maximizar throughput.
Agendamento inteligente baseado em capacidades
Ao separar o "quê" (a claim) do "onde" (o slice), o Kube-scheduler ganha uma visão semântica do cluster. Em vez de forçar o placement através de taints e tolerations rígidos, o orquestrador passa a avaliar a disponibilidade real. Isso transforma o pool de hardware em um recurso "líquido", otimizando o deployment de workloads complexos de forma automatizada e eficiente.
Impacto para empresas brasileiras
Para quem opera em ambientes multi-cloud ou pretende escalar workloads de ML, o DRA é fundamental. O fato de o Kubernetes AI Conformance program ter estabelecido o suporte ao DRA como critério obrigatório na versão 1.35 indica que este será o padrão para todas as plataformas de IA daqui para frente. Ignorar essa mudança é aceitar um débito técnico que se tornará evidente na medida em que a densidade de processadores de IA aumentar em seus clusters.
Artigo originalmente publicado por Bo FuSenior Product Manager em Cloud Blog.
