

O Data Agent Kit unifica o ecossistema de engenharia e ciência de dados ao permitir que agentes de IA interajam diretamente com stacks cloud (como BigQuery) via Model Context Protocol (MCP). A ferramenta mitiga o 'context window tax' e a fragmentação de processos, permitindo engenharia baseada em intenção. Em conclusão, a solução reduz drasticamente o ciclo de desenvolvimento, permitindo que devs foquem em resultados de negócio enquanto a IA automatiza a infraestrutura de dados e a orquestração.
O ecossistema atual de desenvolvimento de software está migrando para ferramentas agenticas, mas a fragmentação das interfaces de gerenciamento de dados cria silos que elevam o risco operacional e degradam a experiência do desenvolvedor. A constante necessidade de alternar entre consoles, IDEs e documentação gera um 'imposto de contexto' que impede times de engenharia no Brasil de escalar a inovação com a agilidade que novos modelos de IA permitem.
O Data Agent Kit surge como uma solução para unificar esses fluxos, integrando skills de engenharia diretamente em ambientes como VS Code e CLIs de IA. Ao mover a abordagem para uma "engenharia orientada a intenção", o practitioner define o objetivo e a IA gerencia a complexidade subjacente da infraestrutura, otimizando o uso de compute engines como Spark ou BigQuery de forma transparente.
Como o Data Agent Kit centraliza o seu ciclo de vida de dados?
O kit atua como um hub onde o catálogo de dados, tarefas de orquestração e fluxos de Machine Learning coexistem, eliminando o context switching.
Como a inteligência codificada otimiza seus processos?
Em vez de prompts genéricos, o kit utiliza um repositório de skills validadas que seguem as melhores práticas de mercado para ELT e governança de dados.
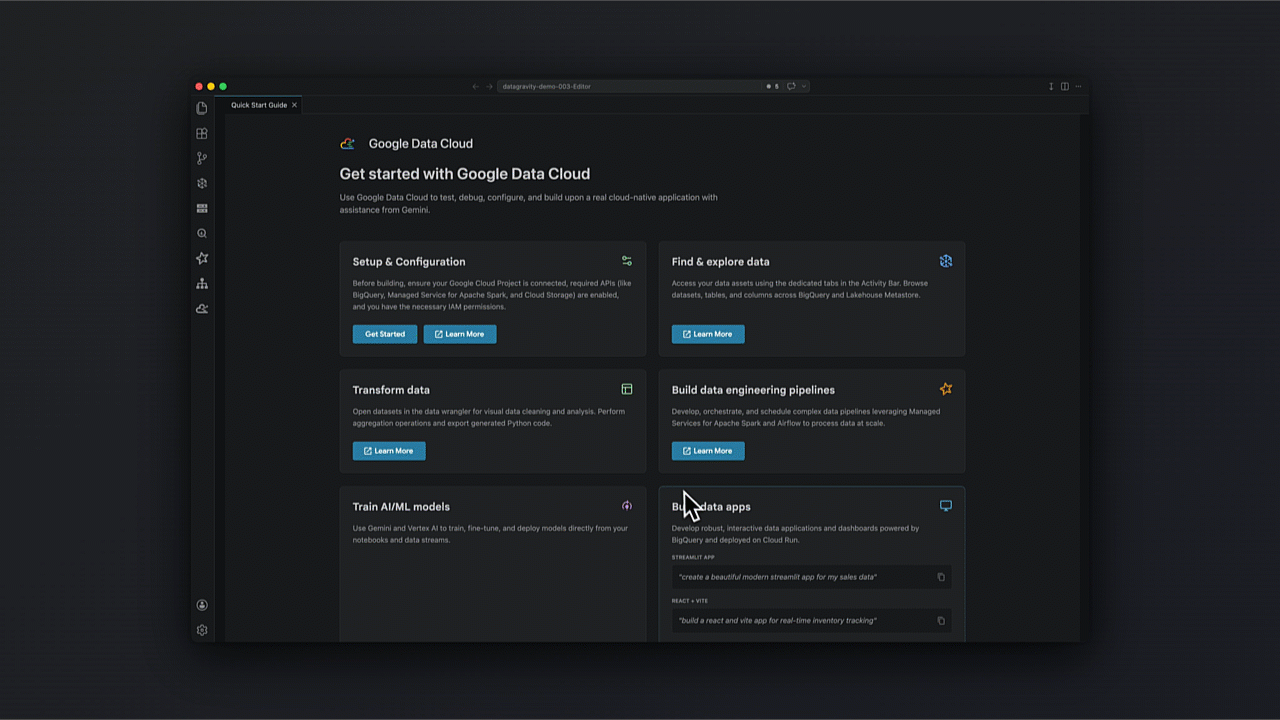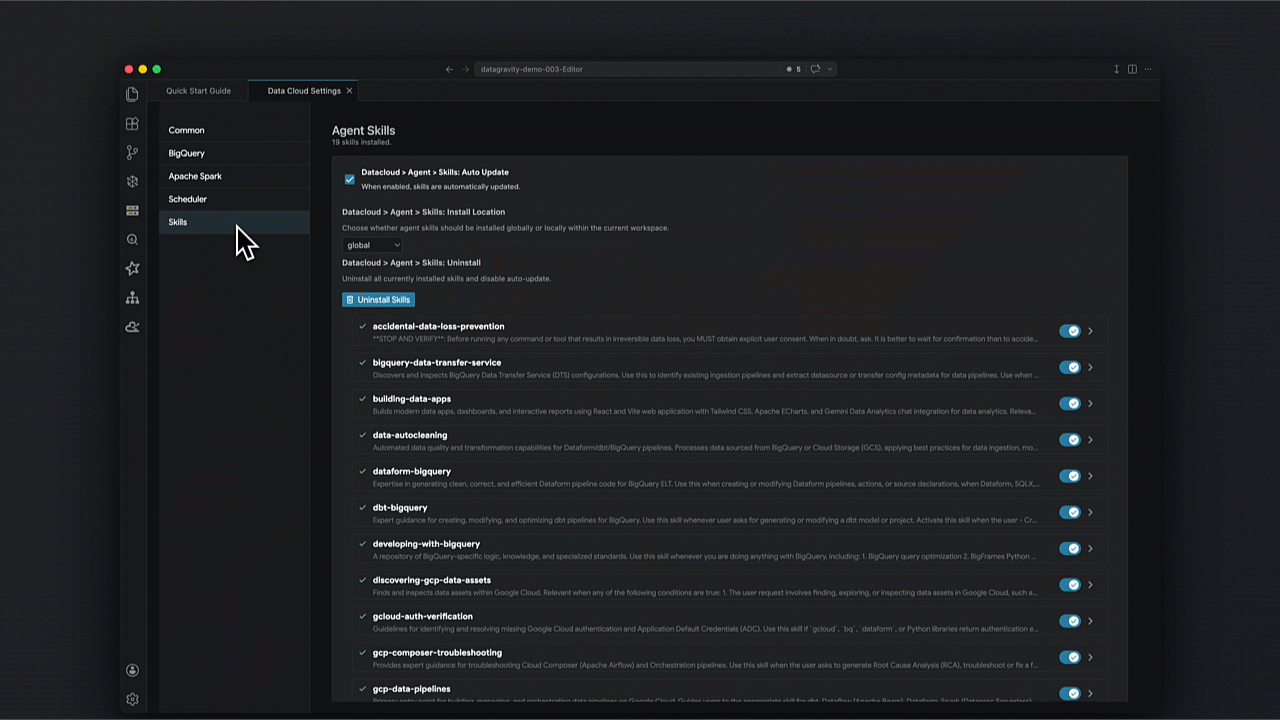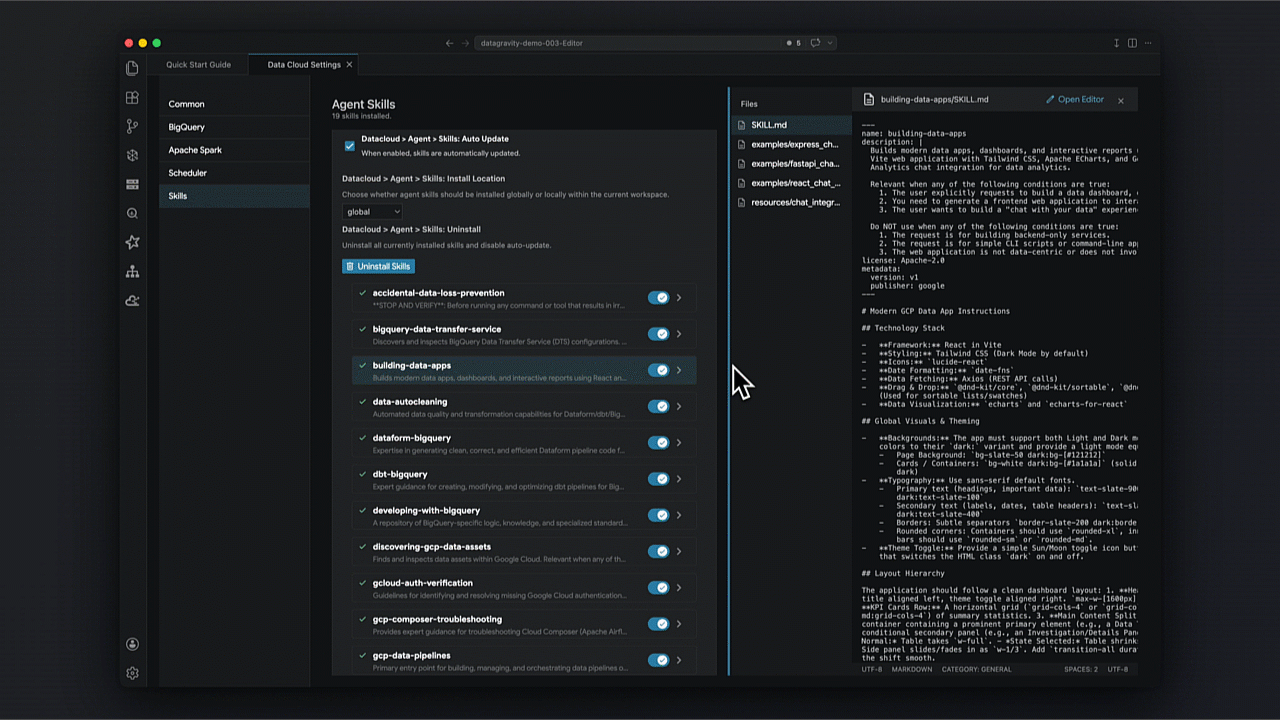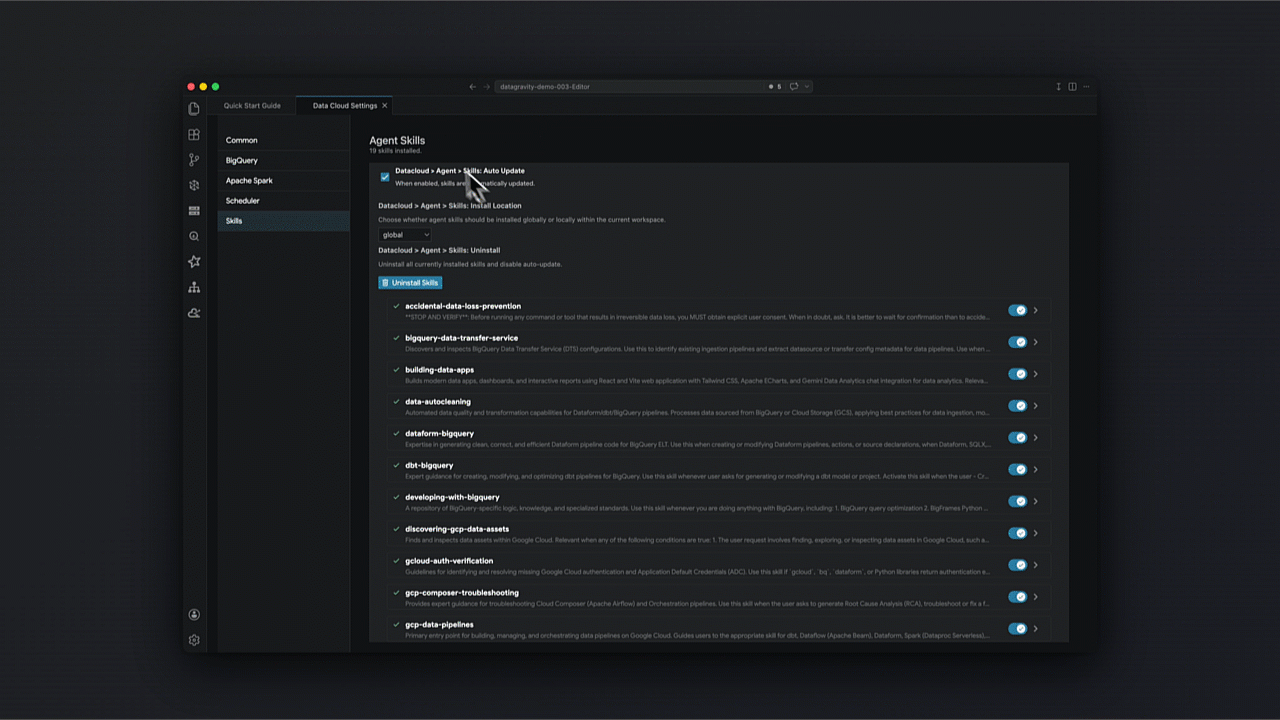
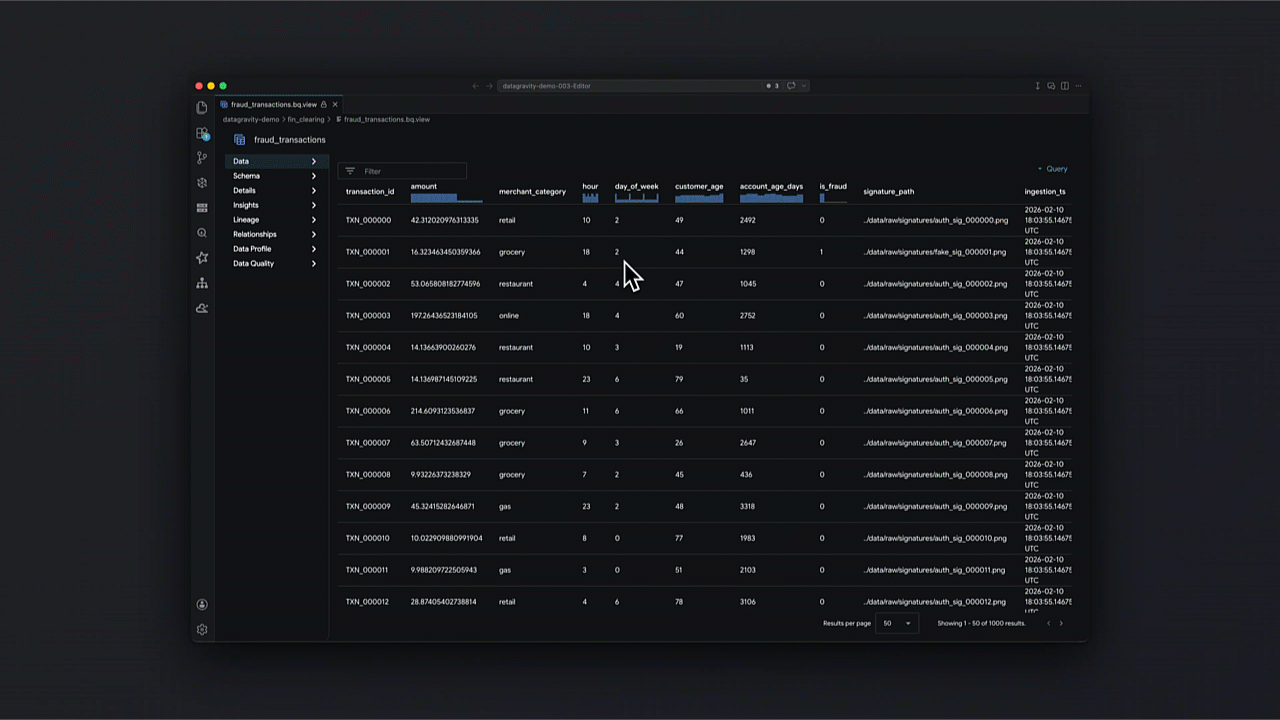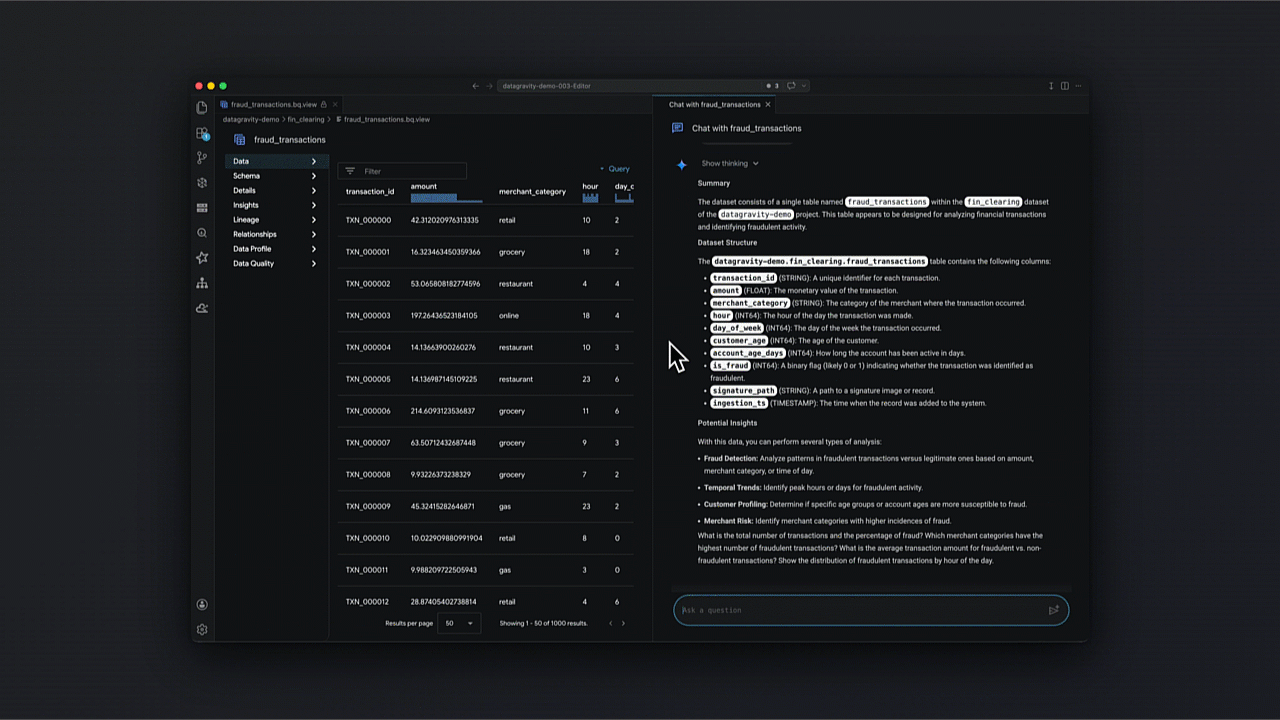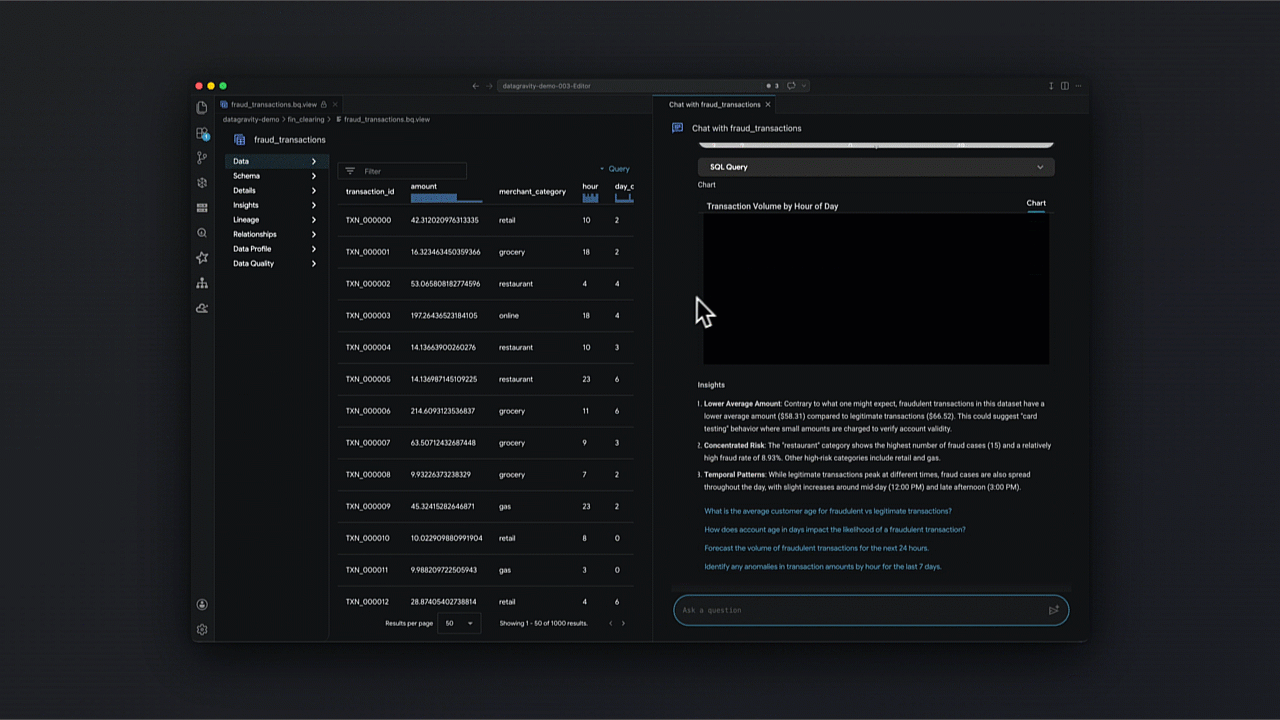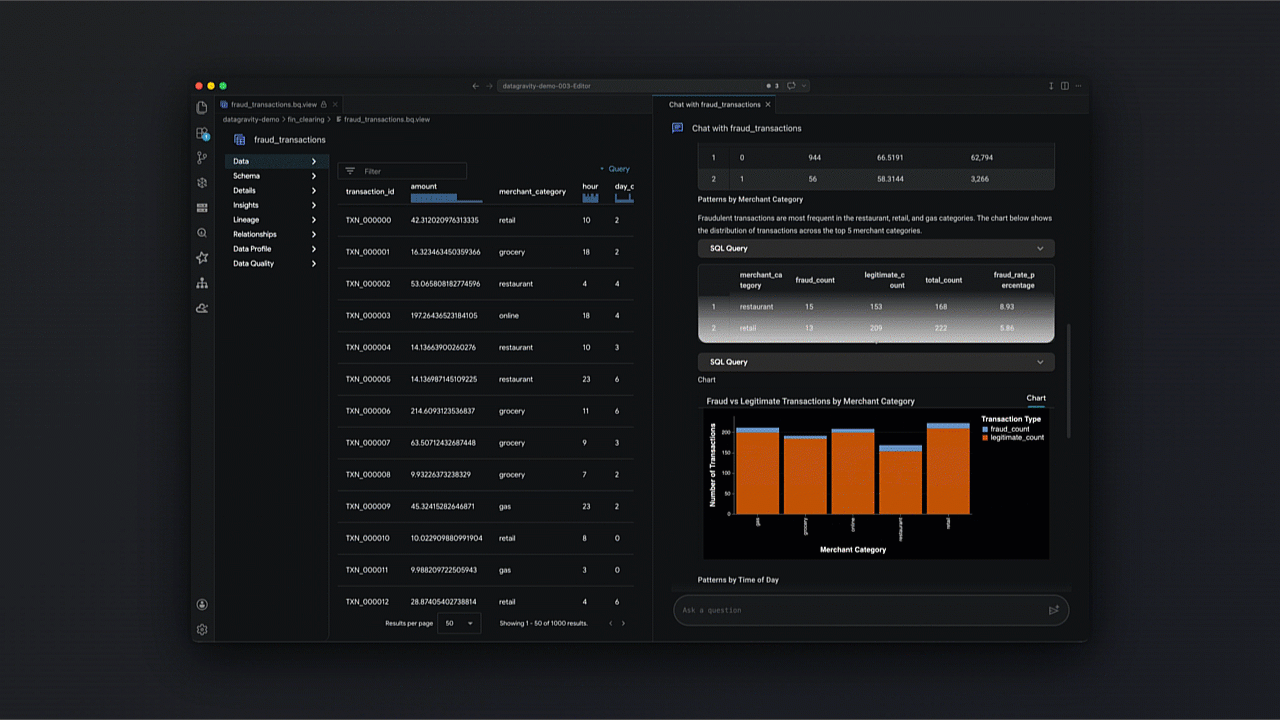
Como transformar a exploração de dados via linguagem natural?
Com a integração da tecnologia Gemini, o Data Agent Kit viabiliza analytics conversacional, permitindo que a equipe explore datasets e valide hipóteses sem escrever SQL complexo manualmente.
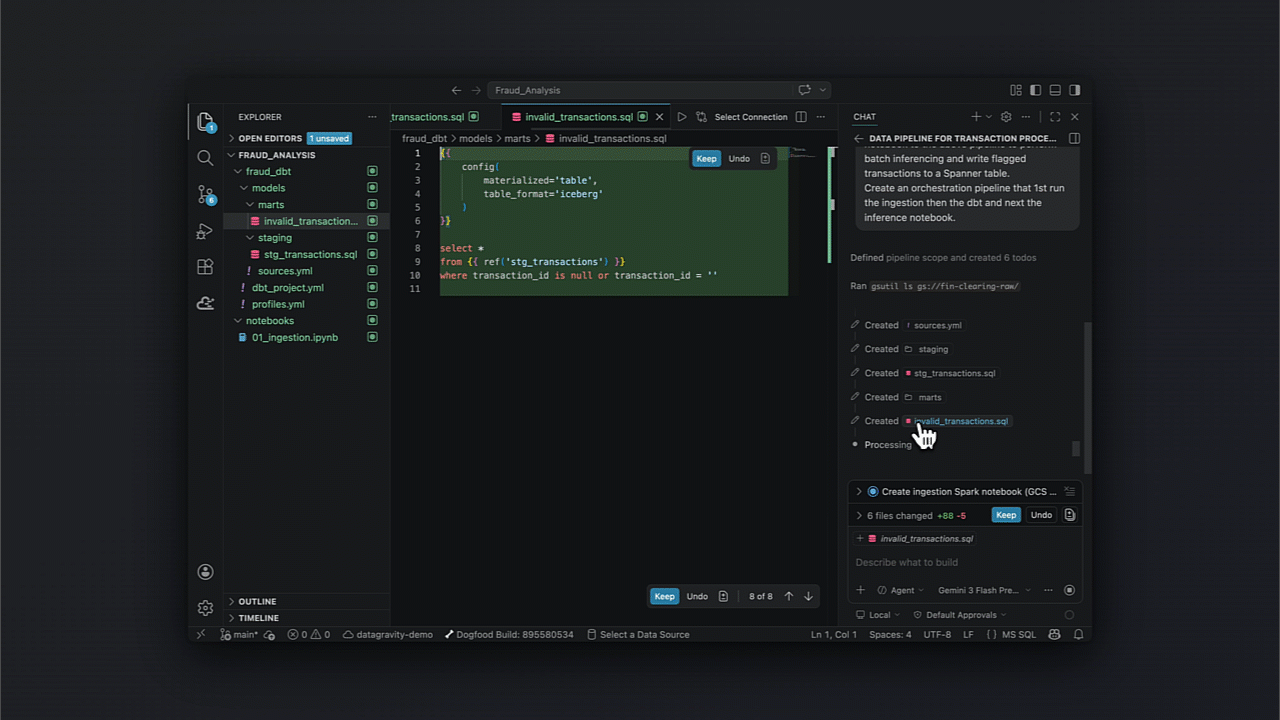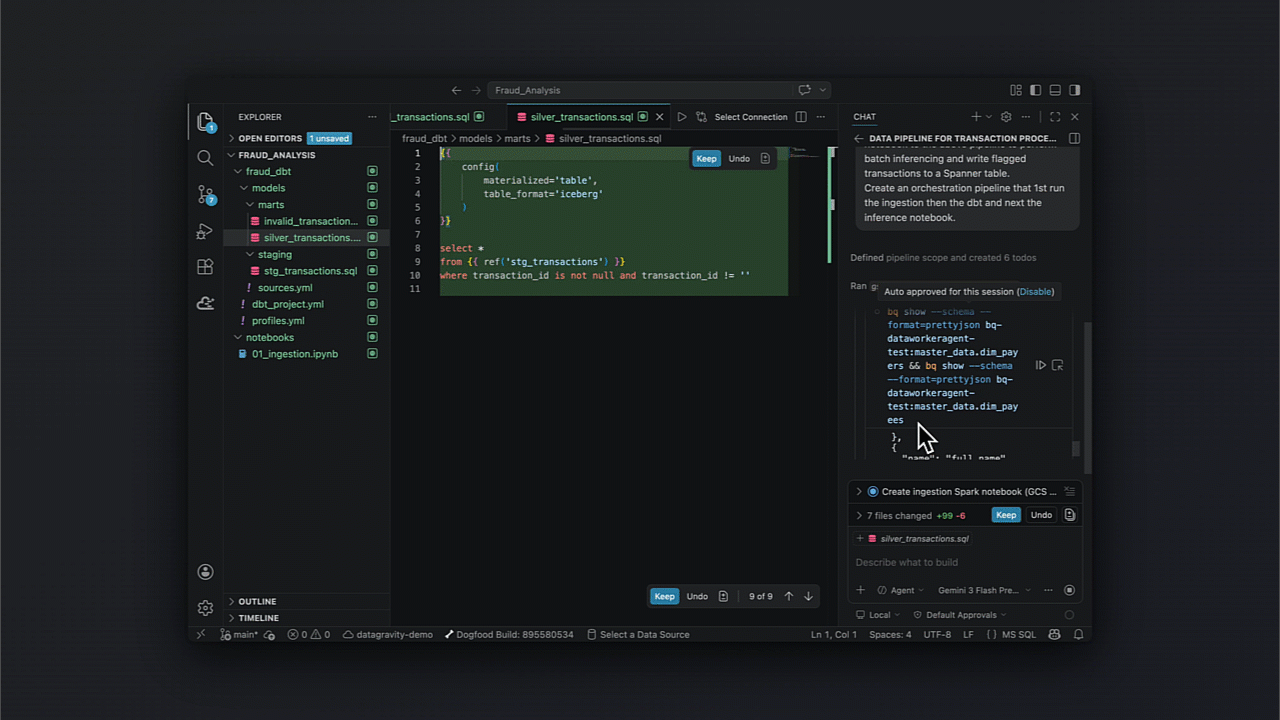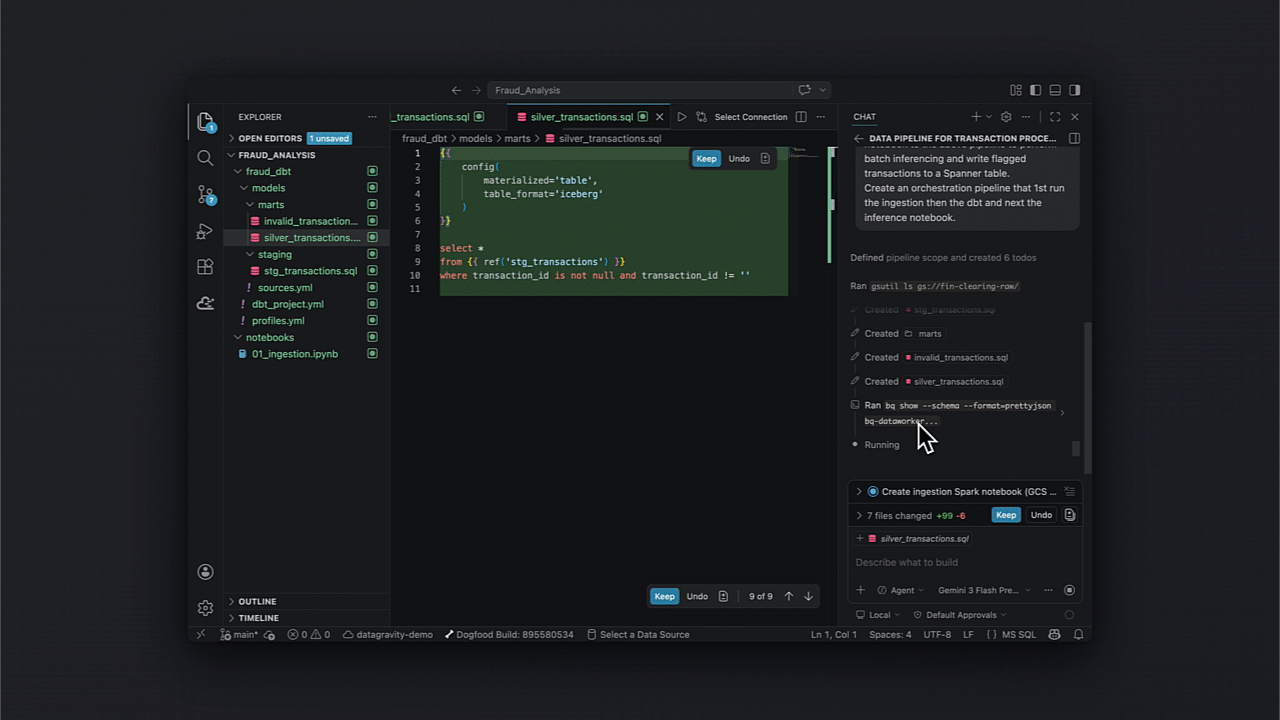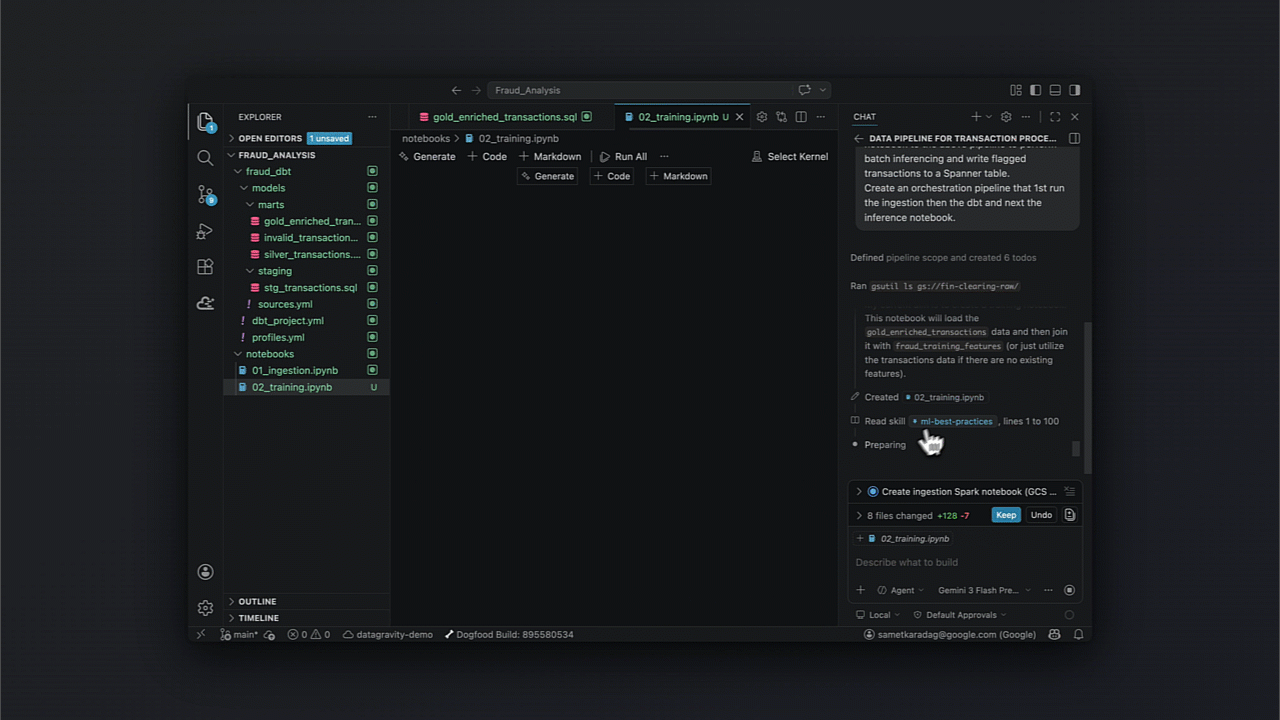
Um exemplo prático: Engenharia baseada em intenção
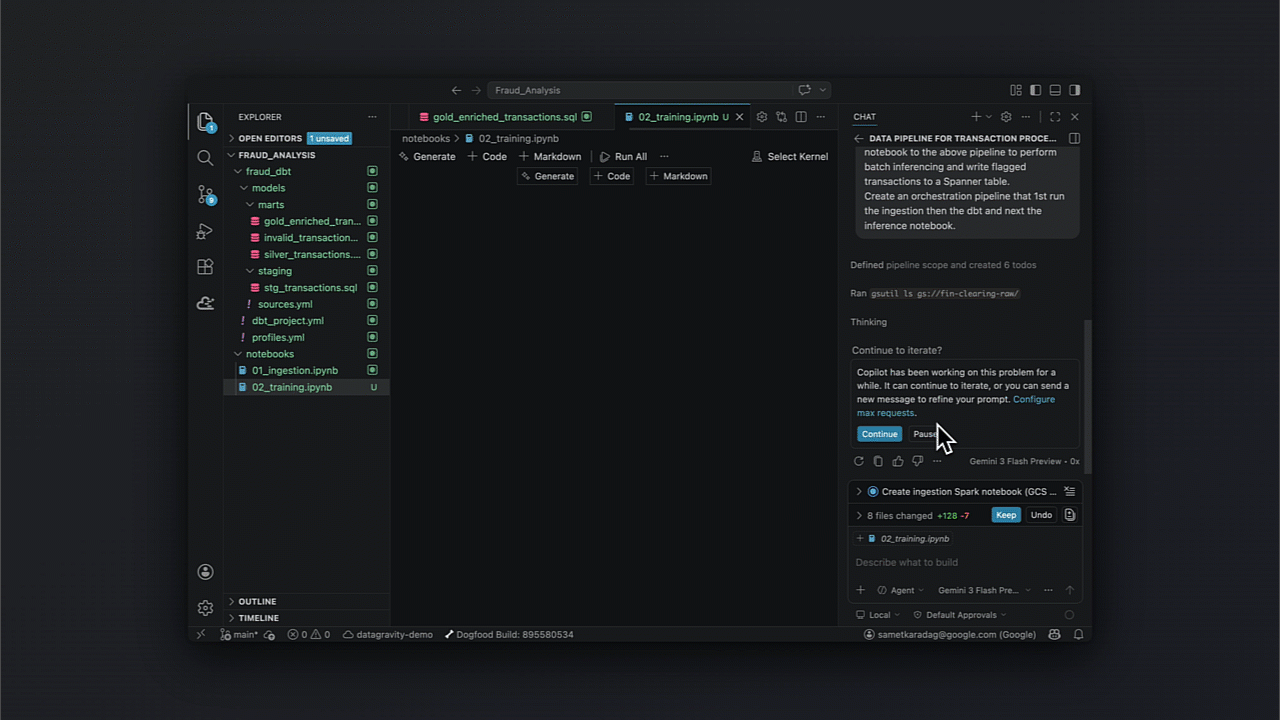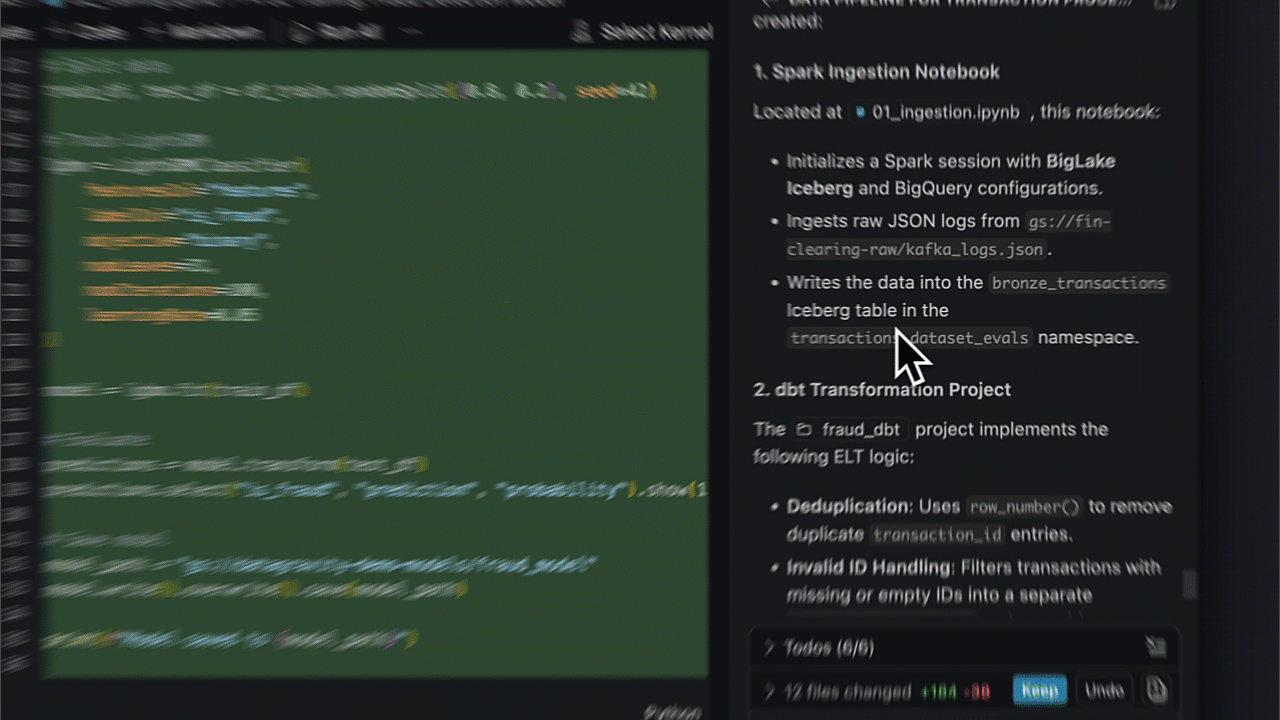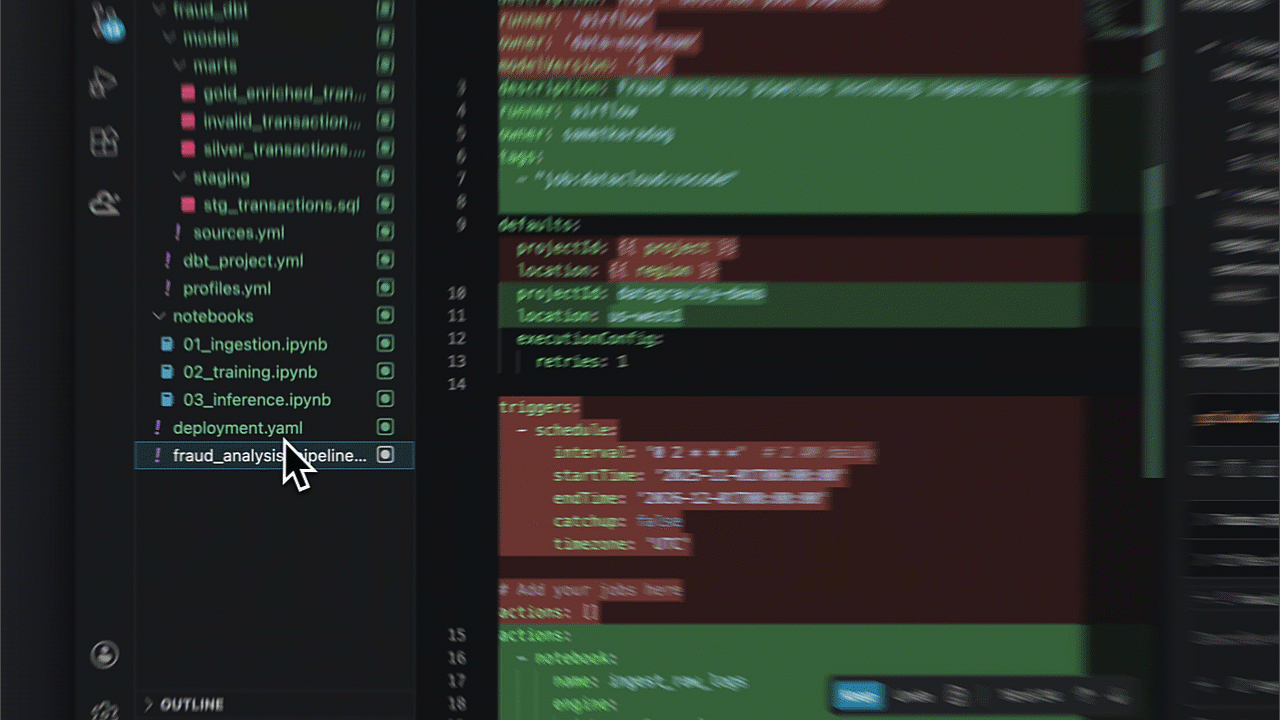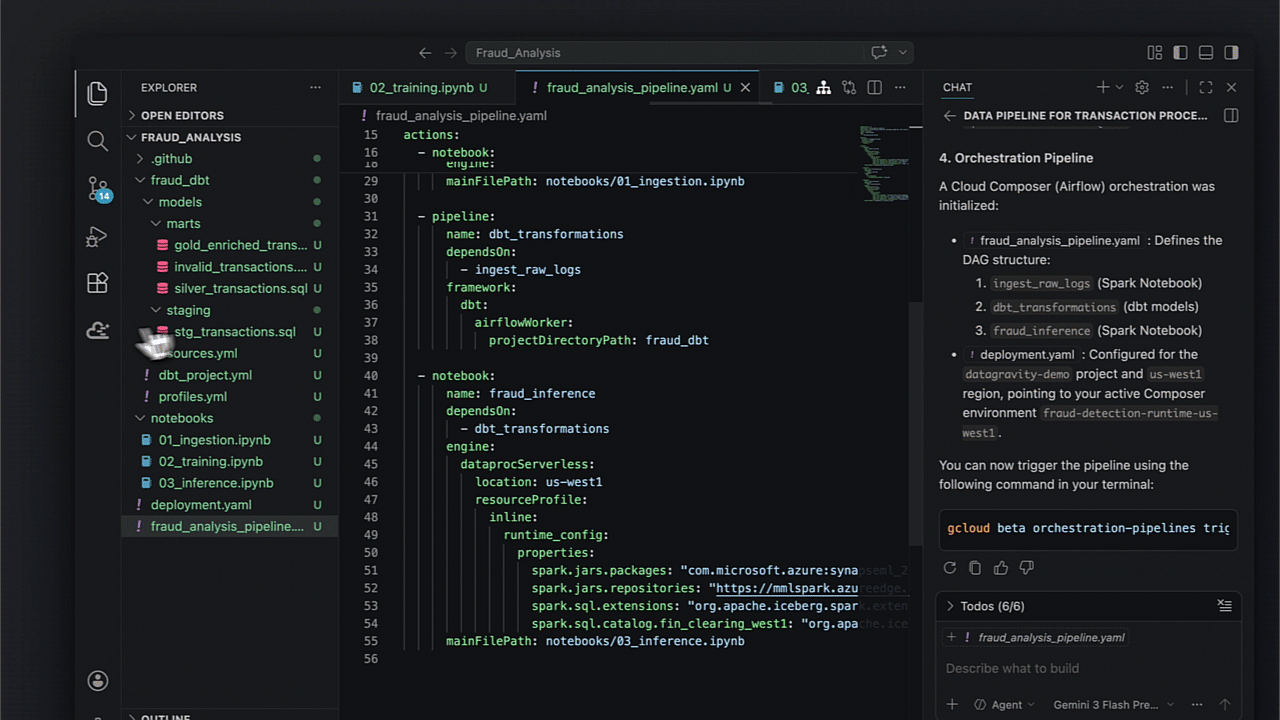
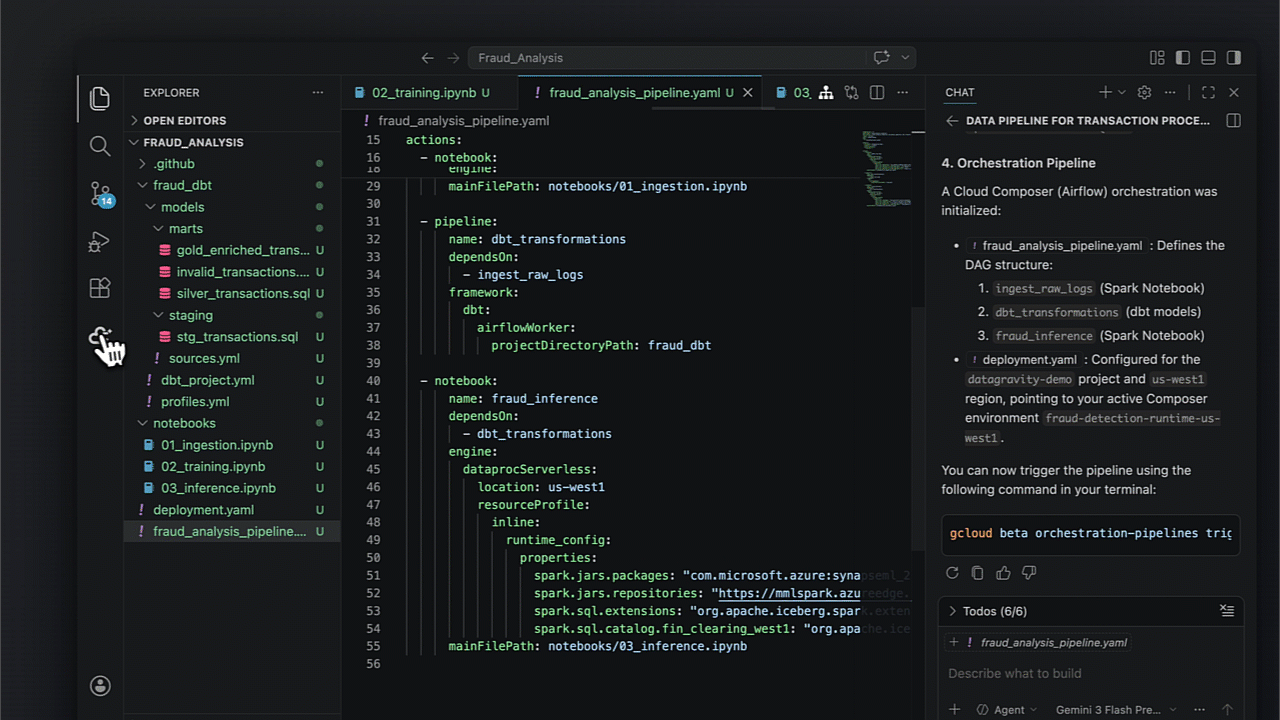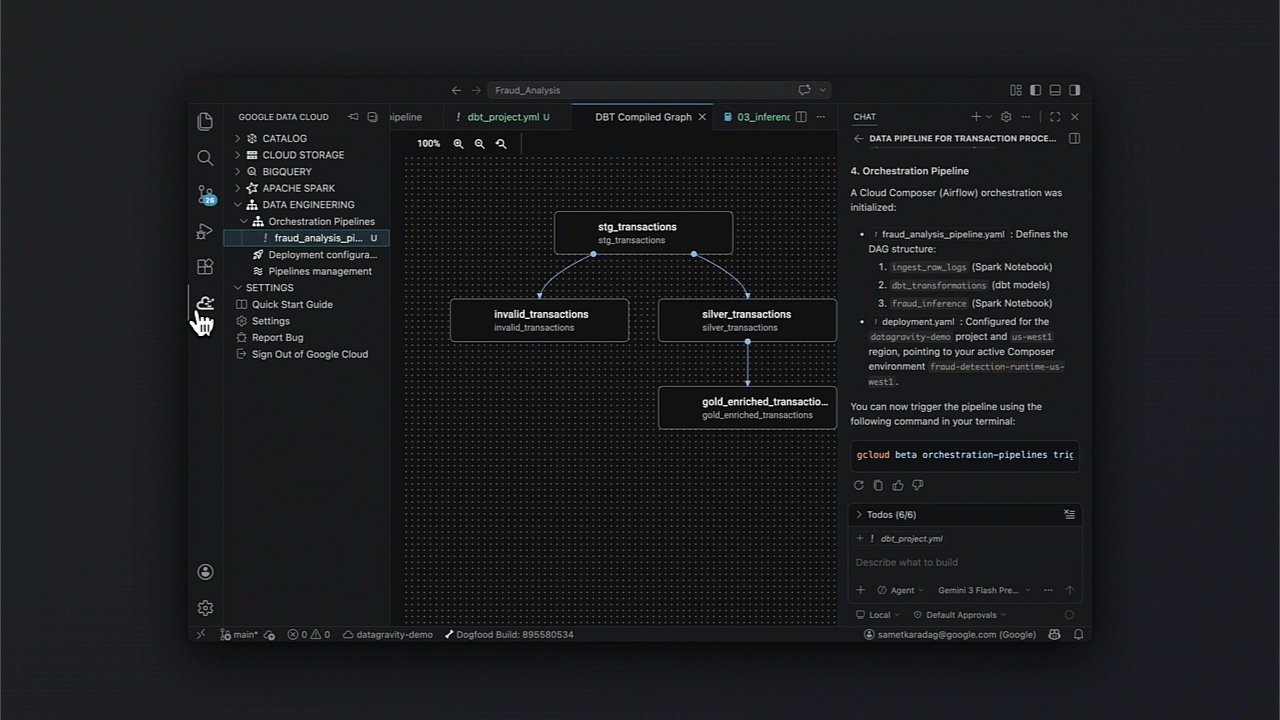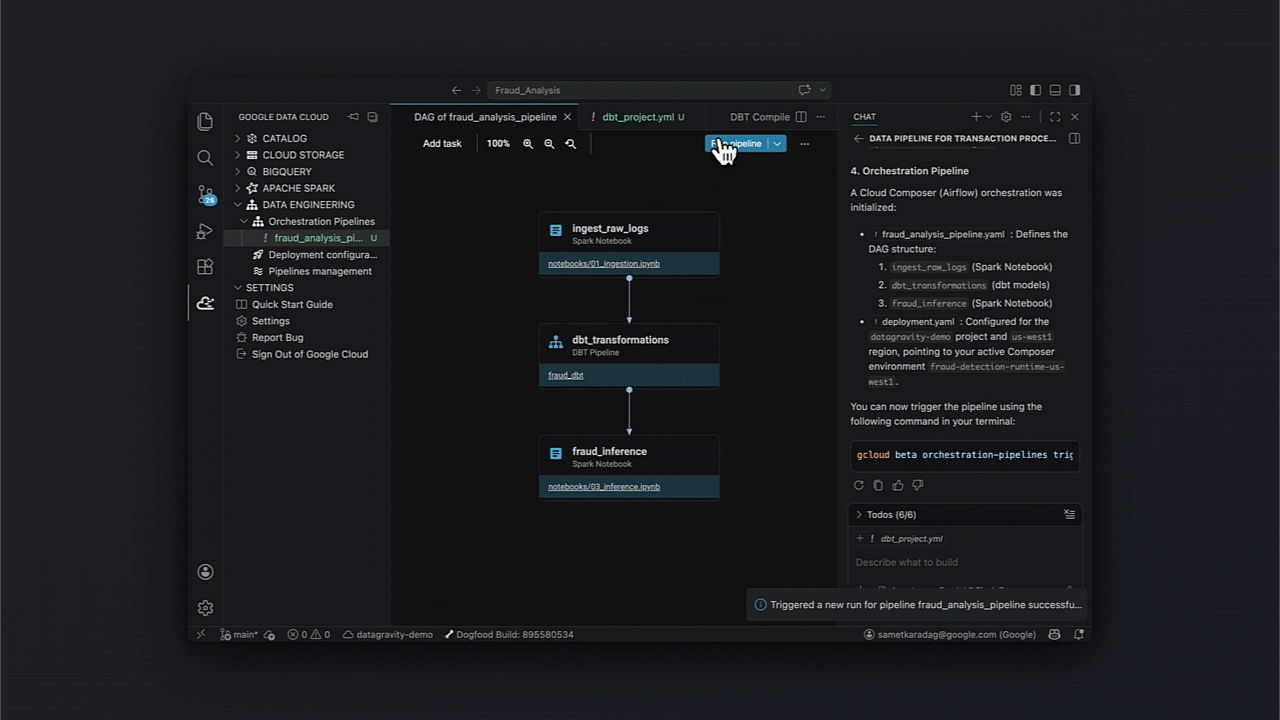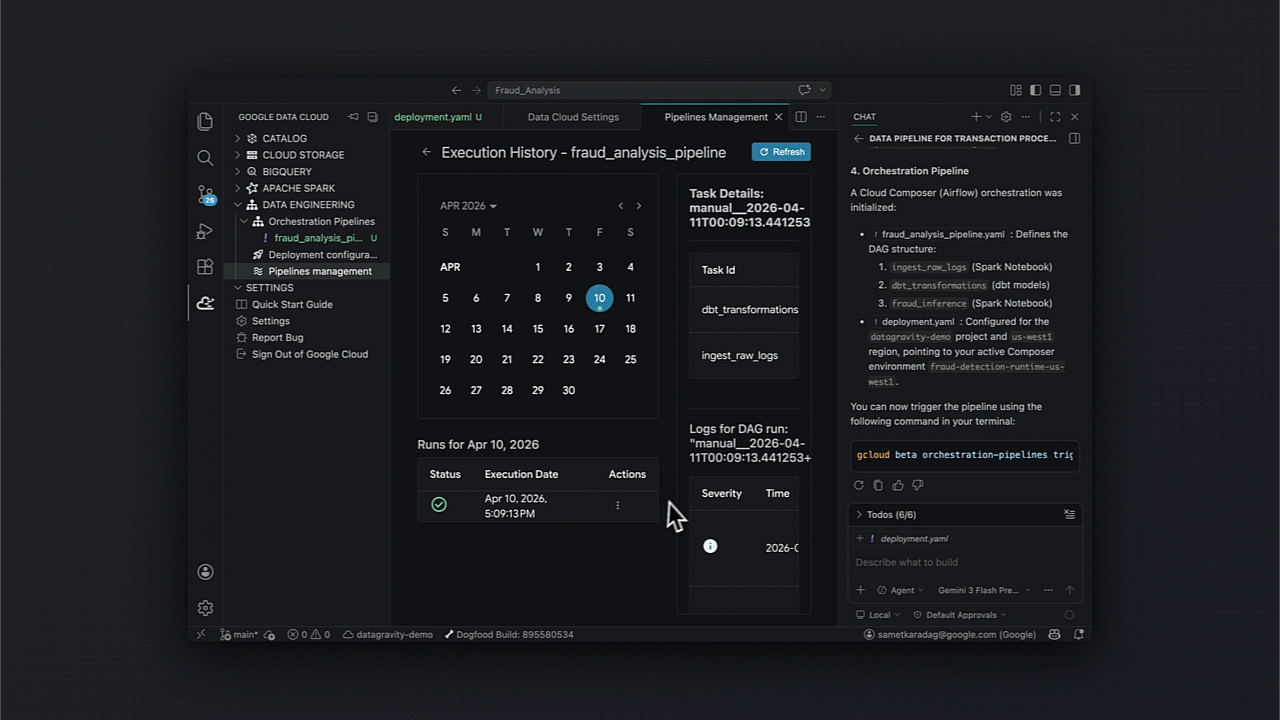
Dentro de um cenário de detecção de fraude, a capacidade de automatizar desde a ingestão via Cloud Storage até o model serving em Spanner transforma processos de horas em minutos.

Após o setup IAM no seu IDE, a orquestração do pipeline segue etapas bem definidas:
- Ingestão para tabelas Iceberg;
- Transformação via dbt para limpeza e enriquecimento;
- Treinamento de modelos com Spark;
- Batch inferencing e persistência em Spanner.
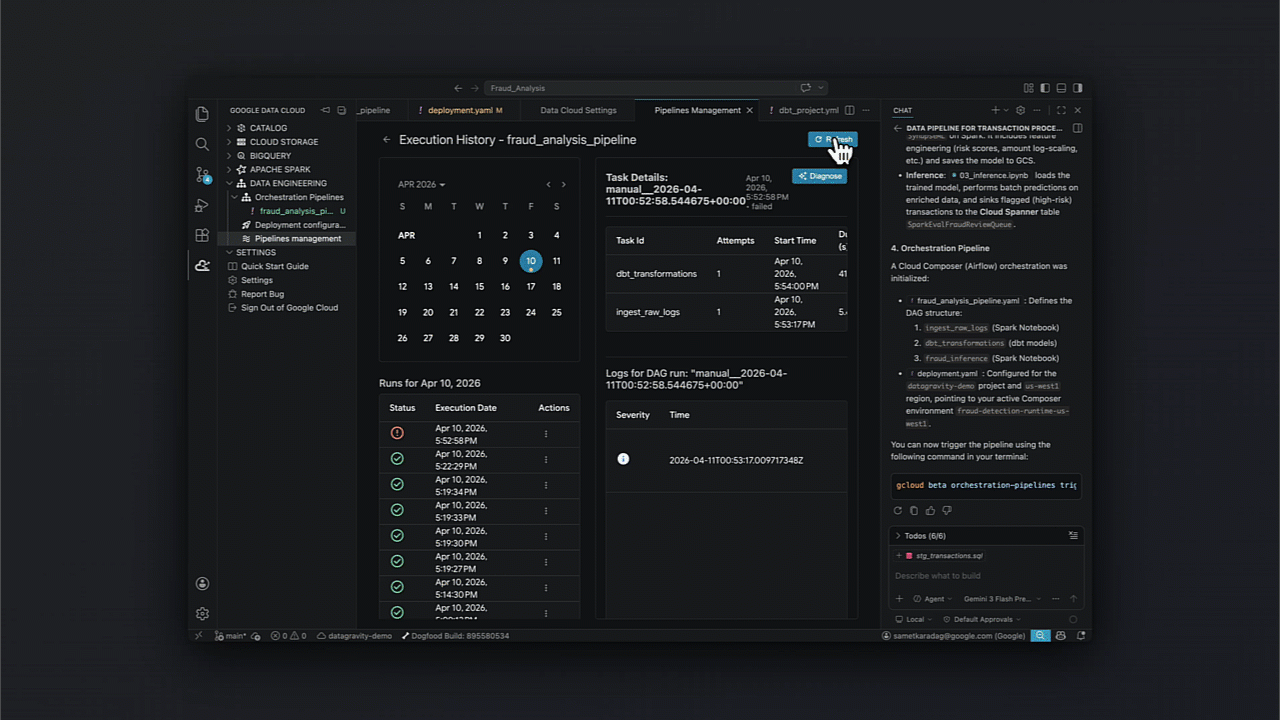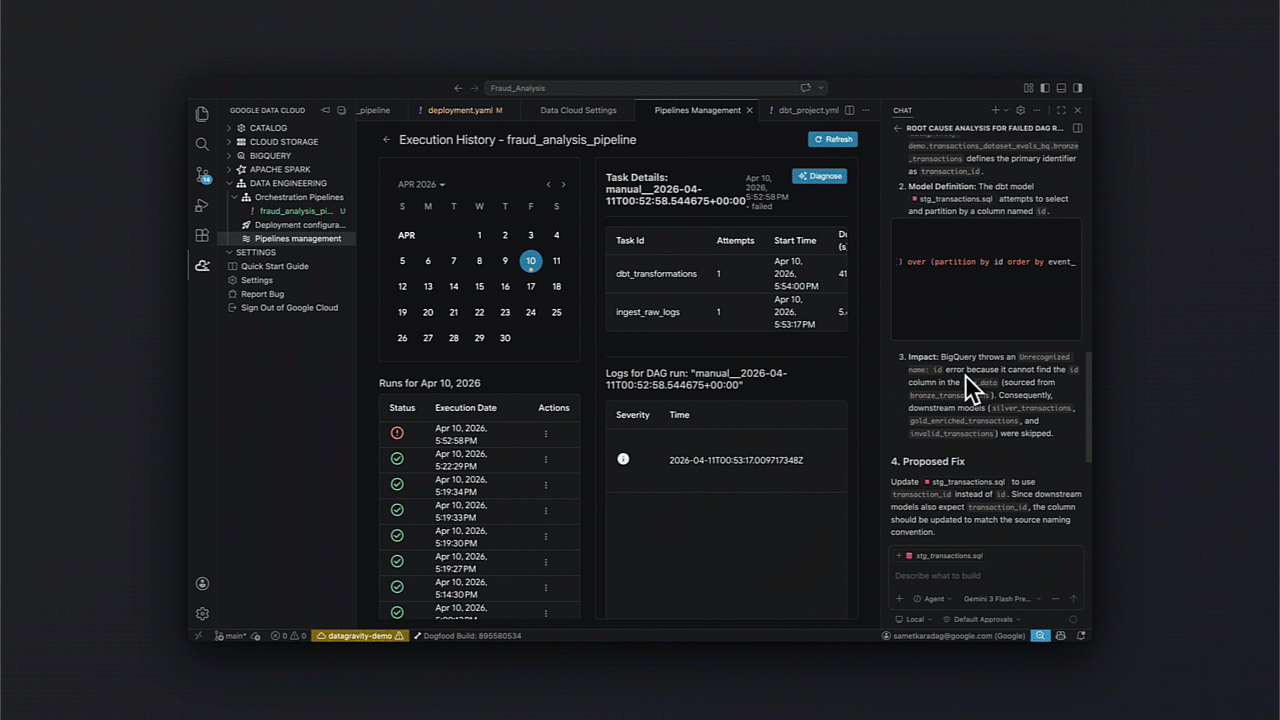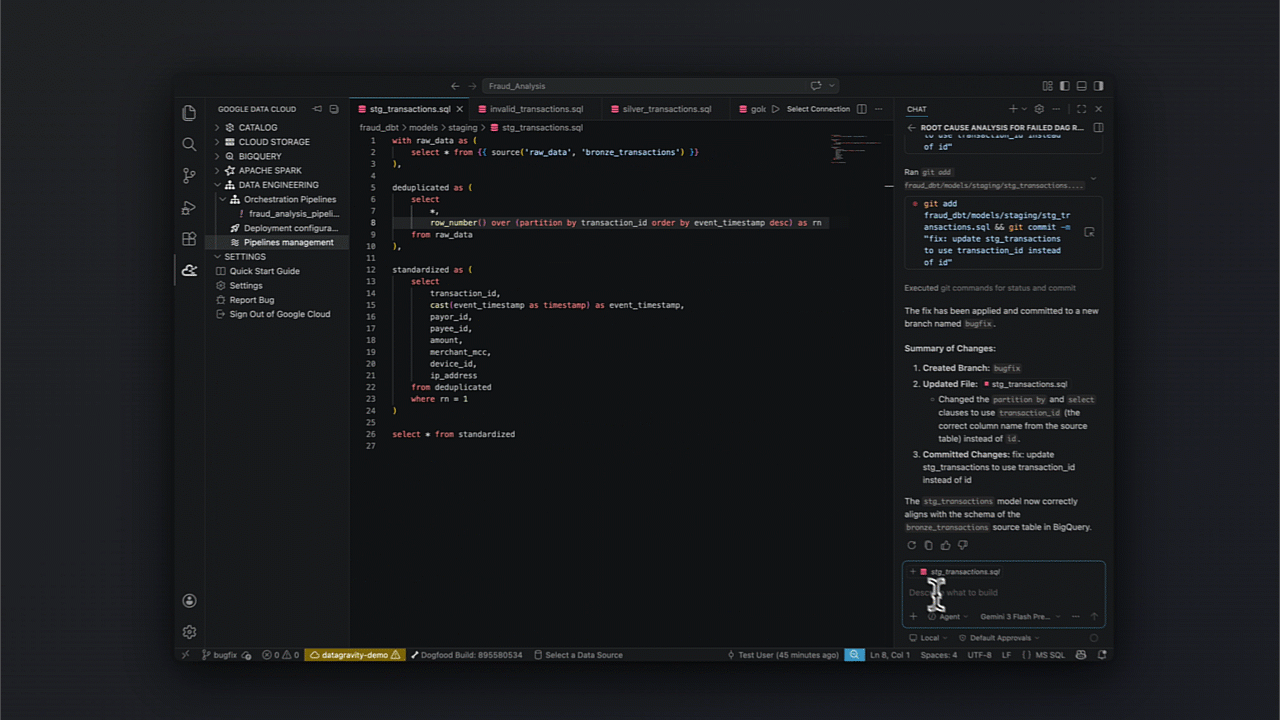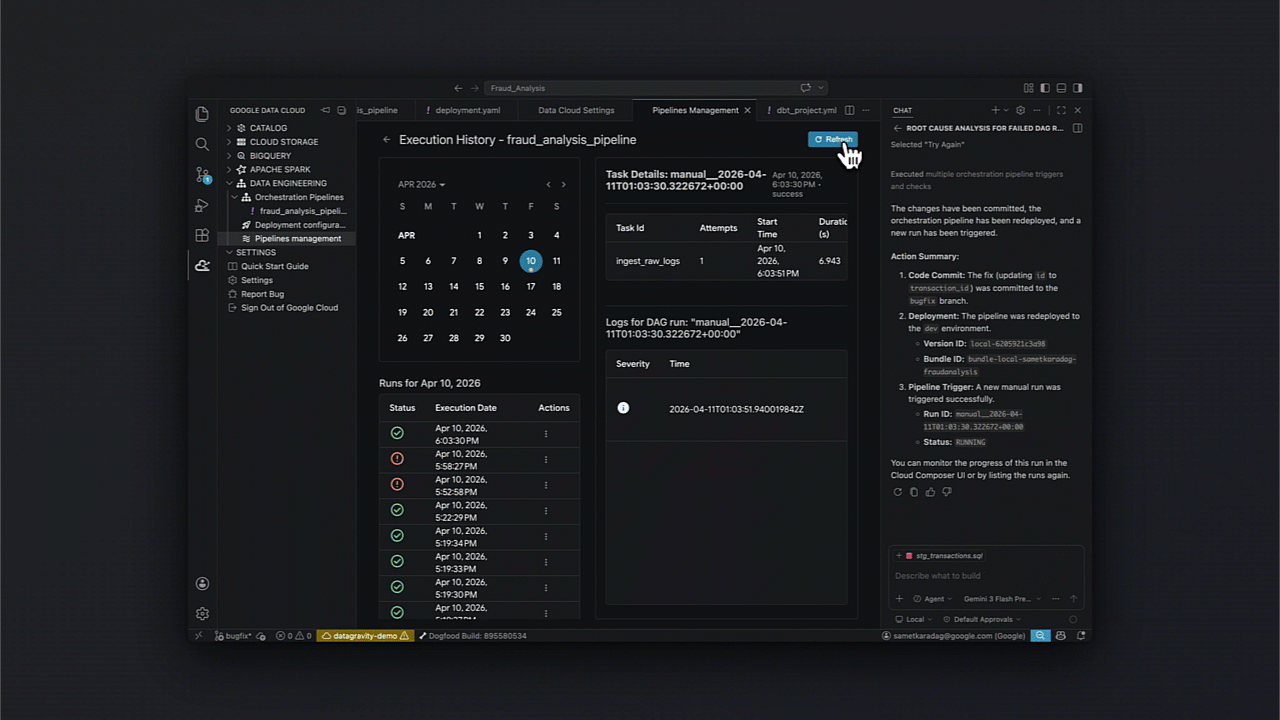
Identificando incertezas: Diagnóstico e recuperação agentica
Um ponto crucial para times de SRE no Brasil é a resiliência. O kit facilita a análise de causa raiz e a automação de fixos em pipelines orquestrados, integrando diagnósticos diretamente no ciclo de CI/CD.
Perguntas Frequentes
- O Data Agent Kit substitui fluxos de orquestração tradicionais?
Não, ele complementa a orquestração. O kit utiliza engenharia baseada em intenção para automatizar a criação e o setup de pipelines, mas a execução final continua integrada às ferramentas de orquestração da sua arquitetura. - Como o Model Context Protocol (MCP) melhora a segurança e eficiência?
O MCP estabelece uma conexão segura entre o ambiente de desenvolvimento e plataformas cloud, eliminando a necessidade de copiar metadados manualmente e reduzindo o consumo de tokens e a latência nas interações com os LLMs. - A ferramenta é restrita ao Google Cloud?
Embora o Data Agent Kit ofereça integração profunda com serviços como BigQuery, AlloyDB e GCS, sua natureza extensível via MCP permite que seja incorporado em fluxos multi-cloud onde o gerenciamento de dados exija padronização e escalabilidade.
Artigo originalmente publicado por Dinesh ChandnaniDirector of Engineering, Data Cloud em Cloud Blog.
