

Modelos de difusão são deceptivamente simples no ambiente de prototipagem, onde rodam com sucesso em uma única VM com suporte a GPU. No entanto, o cenário de produção é implacável: ele exige resiliência contra demandas explosivas, orquestração de jobs de longa duração, distribuição eficiente de artefatos de modelos e uma estratégia robusta de observabilidade de hardware e software.
Para empresas que buscam escalar inferência de IA, o Azure Kubernetes Service (AKS) tornou-se a escolha natural. A chave para o sucesso não é apenas implantar um container, mas operar uma plataforma de inferência reprodutível. A estratégia ideal isola o plano de controle, gerencia queues de trabalho de forma inteligente e segrega o consumo de vGPU para evitar contenção de recursos.
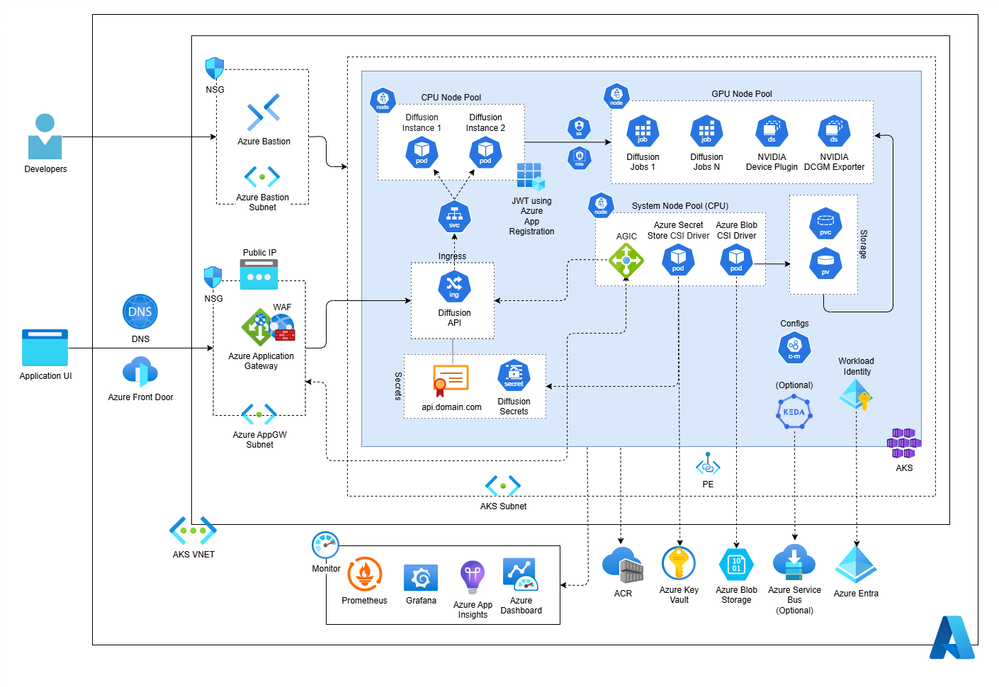
O modelo operacional separa a camada de API (CPU) da camada de execução pesada (GPU). O uso de Application Gateway e WAF no edge é mandatório, enquanto a comunicação com serviços do Azure deve ser feita preferencialmente via Private Link, minimizando a exposição à internet pública e simplificando a governança de rede.
O Padrão de Referência
A arquitetura deve ser dividida em "faixas" de trabalho (lanes):
- Ingress e API Lane: Nodos de CPU que validam identidade, gerenciam requisições e fazem o dispatch das tarefas.
- Dispatch Lane: Pode ser nativo do Kubernetes para cenários previsíveis ou utilizar o Azure Service Bus com KEDA para garantir persistência de fila e escalabilidade orientada a eventos (event-driven).
- GPU Execution Lane: Nodos isolados dedicados à inferência. Aqui, é vital o uso de Persistent Volumes (PV/PVC) para cache de modelos (como via Hugging Face), reduzindo a latência de cold start dos pods.
A grande decisão estratégica aqui é o modelo de dispatch. Se você busca poucas dependências, o controle nativo do K8s é suficiente. Se a sua carga de trabalho sofre picos imprevisíveis, o uso de KEDA acoplado ao Service Bus oferece a visibilidade (backlog depth) necessária para um autoscaling que não sobrecarregue a infraestrutura.
Segurança e Observabilidade: Não são 'Add-ons'
Em plataformas de IA, a segurança deve ser shift-left. Utilize Microsoft Entra Workload ID para remover credenciais de longa duração, integrando diretamente com Azure Key Vault para o gerenciamento de segredos via Secrets Store CSI Driver. A rede deve ser ancorada em Private Endpoints, garantindo que o tráfego entre a aplicação, o ACR e o Storage reste dentro do ambiente privado.
Para a observabilidade, não se limite a logs de aplicação. É imperativo correlacionar telemetria de software (via Application Insights e OpenTelemetry) com métricas de hardware (via NVIDIA DCGM Exporter exportando para Azure Managed Prometheus e Grafana). Somente com essa visão unificada você saberá se uma falha é um bug na aplicação, uma saturação na fila de dispatch ou falta de vGPU disponível.
Considerações Finais
A execução de modelos de IA em produção não é um problema de "hospedagem de modelo", mas sim um desafio de Engenharia de Plataforma. O modelo de IA pode mudar, mas os fundamentos sólidos — isolamento por lanes, CI/CD com rollout seguro e observabilidade completa — são o que garantem que sua plataforma não será apenas um benchmark, mas sim uma operação estável e lucrativa. Alternativas como KAITO podem ser interessantes para experimentação rápida, mas para pipelines de difusão customizados, manter o controle rigoroso da infraestrutura via AKS continua sendo o caminho mais curto para a maturidade operacional.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
