

O Google Cloud anunciou no Next '26 uma atualização significativa para o Firestore, focada em ecossistemas de agentes de IA, buscas textuais nativas e compatibilidade aprimorada com MongoDB. Para empresas brasileiras, isso representa uma oportunidade de reduzir o débito operacional ao eliminar infraestruturas segregadas de busca e simplificar migrações via MongoDB. A conclusão é que o banco de dados está evoluindo de uma solução serverless para uma plataforma robusta de suporte a aplicações inteligentes de larga escala.
Na era dos agentes de IA, a lacuna entre a concepção de uma ideia e um deployment funcional encurtou drasticamente. O desafio para engenheiros e gestores de TI no Brasil não é apenas a velocidade de codificação, mas garantir que a infraestrutura de dados suporte picos de carga (scalability) e operações complexas sem comprometer o custo (FinOps). O Firestore posiciona-se como uma resposta direta a essas necessidades.
O que torna o Firestore uma escolha estratégica?
Para empresas que dependem de tecnologia para escalar — seja um founder validando um MVP ou uma grande organização modernizando legados — a escolha do banco de dados reflete diretamente na eficiência operacional. Os três pilares de preocupação atuais são:
- Scalability: Capacidade de absorver picos de tráfego sem intervenção manual.
- Budget Efficiency: Arquitetura serverless que escala para zero em períodos de inatividade.
- Iteration Speed: Eliminação de migrações de schema custosas durante o desenvolvimento acelerado.
O Firestore mantém seu SLA de 99.999% e transações ACID, garantindo que a agilidade não resulte em falhas de governança.
1. Aceleração via integrações de agentes de IA
O Firestore agora opera como uma peça central na "programação via prompt". Através do AI Studio, desenvolvedores podem provisionar full-stack apps com database e auth em um único comando.
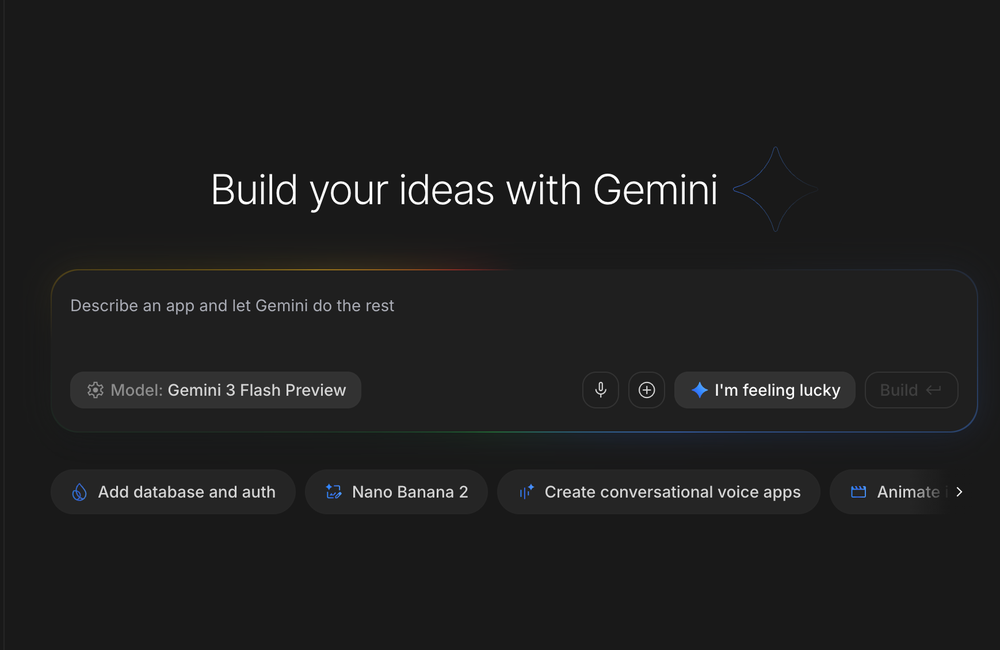
Além disso, o suporte a Firestore Skills e o uso de Gemini Code Assist permitem que queries complexas, incluindo compatibilidade com MongoDB, sejam geradas por linguagem natural dentro do console.
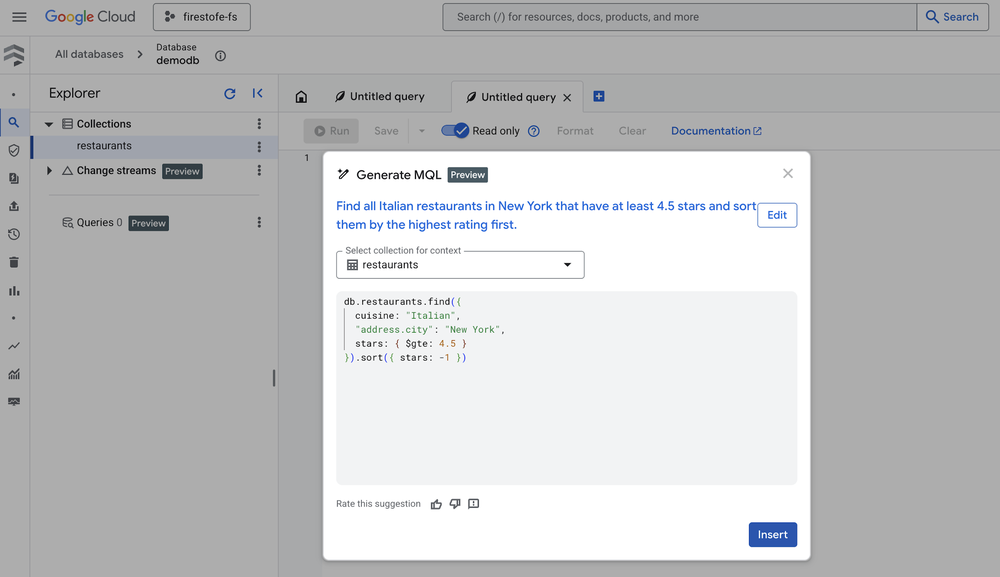
2. Full-text search e novos recursos de query engine
A introdução de full-text search nativa é um divisor de águas. Diferente de arquiteturas que recorrem a sidecars com eventual consistency (o que gera resultados de busca desatualizados em relação ao estado real do banco), o Firestore garante que os índices de busca sejam transacionalmente consistentes com os dados armazenados.
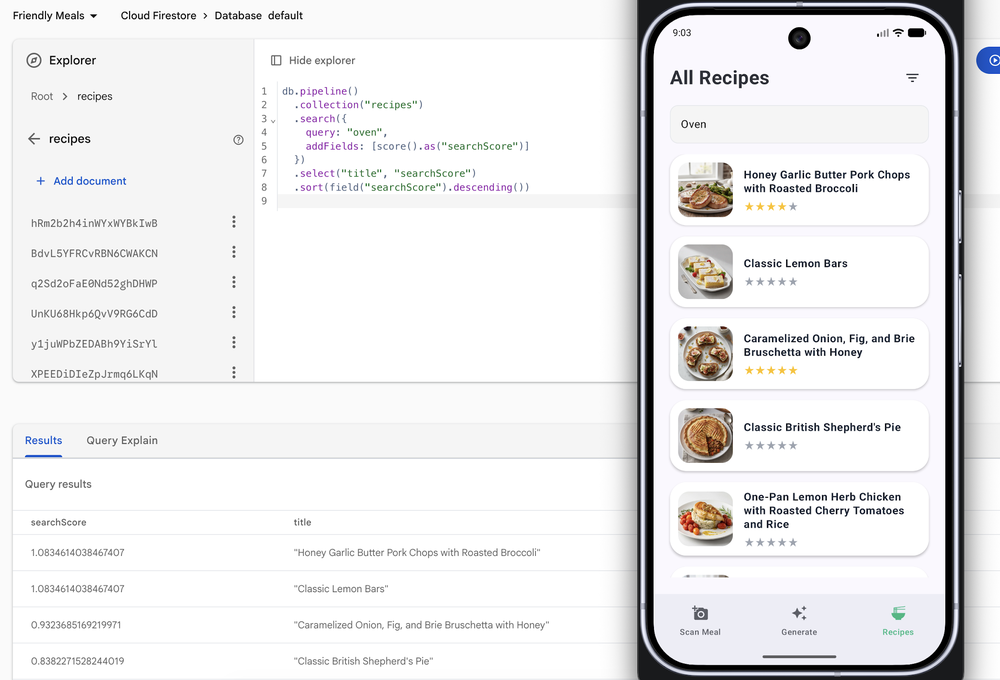
Além disso, a implementação de JOINs via subqueries e operações de pipeline (incluindo normalização bulk e geolocalização) trazem uma expressividade que antes exigia o uso de múltiplos serviços ou soluções externas.
3. Migração simplificada de workloads MongoDB
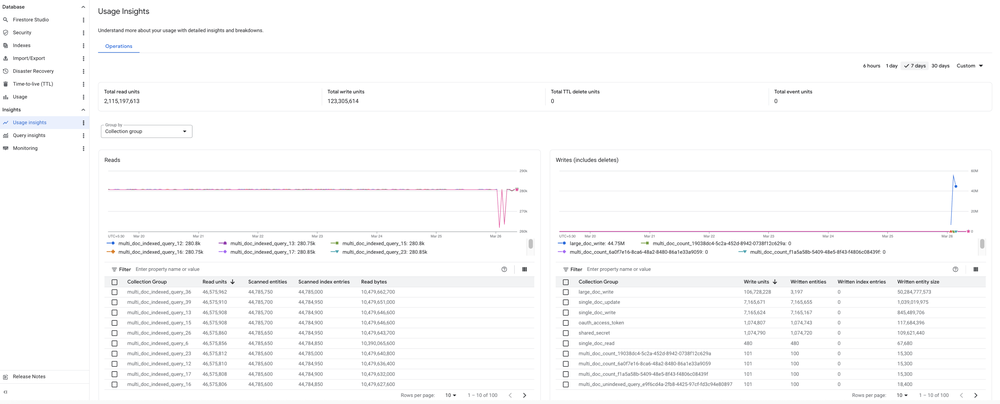
O foco em reduzir o lock-in e facilitar migrações atingiu uma nova fase. Com suporte a documentos de até 16MiB e o uso de change streams escaláveis para o BigQuery, o Firestore se torna um destino muito mais viável para empresas que utilizam MongoDB.
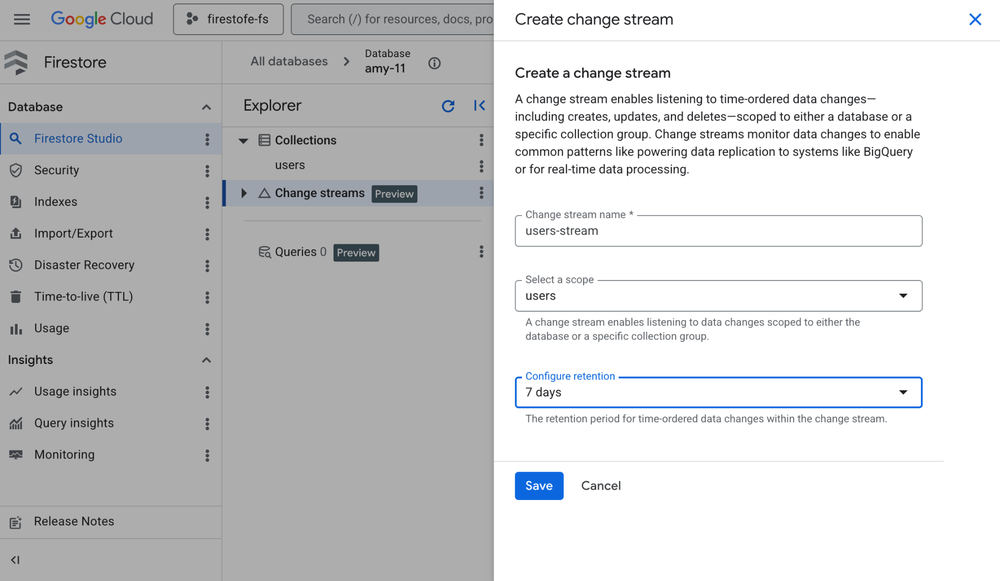
Essas melhorias visam garantir que, ao migrar para a edição Enterprise, o time de engenharia não apenas mantenha o throughput esperado, mas ganhe em observabilidade e governança de dados.
Perguntas Frequentes
-
Como as novas integrações de IA facilitam a vida de quem desenvolve com agentes?
O Firestore agora possui integração nativa com o AI Studio e suporte a MCP (Model Context Protocol), permitindo que LLMs interajam diretamente com os dados via linguagem natural, o que reduz drasticamente o ciclo de feedback no desenvolvimento de aplicações agenticas. -
A funcionalidade de full-text search do Firestore substitui soluções externas como o Elasticsearch?
Em muitos cenários, sim. Por ser nativamente integrada e oferecer consistência forte com os dados transacionais — ao contrário de soluções híbridas com eventual consistency — ela elimina o overhead operacional de manter infraestrutura de índices separada. -
O suporte a MongoDB no Firestore é apenas cosmético?
Não, o suporte amadureceu significativamente, oferecendo compatibilidade com documentos maiores (até 16MiB), change streams para BigQuery em tempo real e comandos administrativos padronizados, facilitando migrações sem a necessidade de reescrever inteiramente a camada de acesso a dados da sua aplicação.
Artigo originalmente publicado por Patrick CostelloEngineering Manager, Google Cloud em Cloud Blog.
