

Introdução: Da recuperação reativa à estratégia de resiliência
À medida que as organizações elevam o Azure Databricks de uma simples engine de analytics para o motor de decisões em tempo real e modelos de IA, a necessidade de estratégias robustas de Disaster Recovery (DR) torna-se uma prioridade estratégica. A resiliência, no contexto atual, não trata apenas de "se algo falhar", mas de garantir a continuidade, o trust e a performance operacional sob qualquer condição.
Uma estratégia de DR moderna deve transcender backups e scripts de failover. Ela precisa estar alinhada às prioridades de negócio, requisitos regulatórios e maturidade operacional da empresa. Adotar padrões de arquitetura para resiliência entre regiões, incluindo a sincronização de objetos do Unity Catalog e o uso de ferramentas como Delta Sharing, torna-se um pilar central para qualquer plataforma de dados que busca estabilidade.
Embora existam soluções nativas como o Managed Disaster Recovery da Databricks, o modelo que detalhamos aqui oferece uma alternativa prática e pronta para produção, permitindo que times de engenharia avancem com resiliência enquanto o ecossistema continua evoluindo.
Por que o Disaster Recovery no Azure Databricks exige uma abordagem diferenciada?
As arquiteturas de Lakehouse apresentam desafios que fogem do escopo do DR de infraestrutura legado. A resiliência aqui precisa endereçar:
- O acoplamento estreito entre data, compute e metatados (Unity Catalog).
- As complexidades dos pipelines distribuídos (batch, streaming e modelos de ML).
- A natureza descentralizada do gerenciamento de workspaces em um ambiente de rápido crescimento.
Isso coloca o DR no Azure Databricks diretamente no campo da engenharia de plataformas.
Figure 1. Main Disaster Recovery Considerations
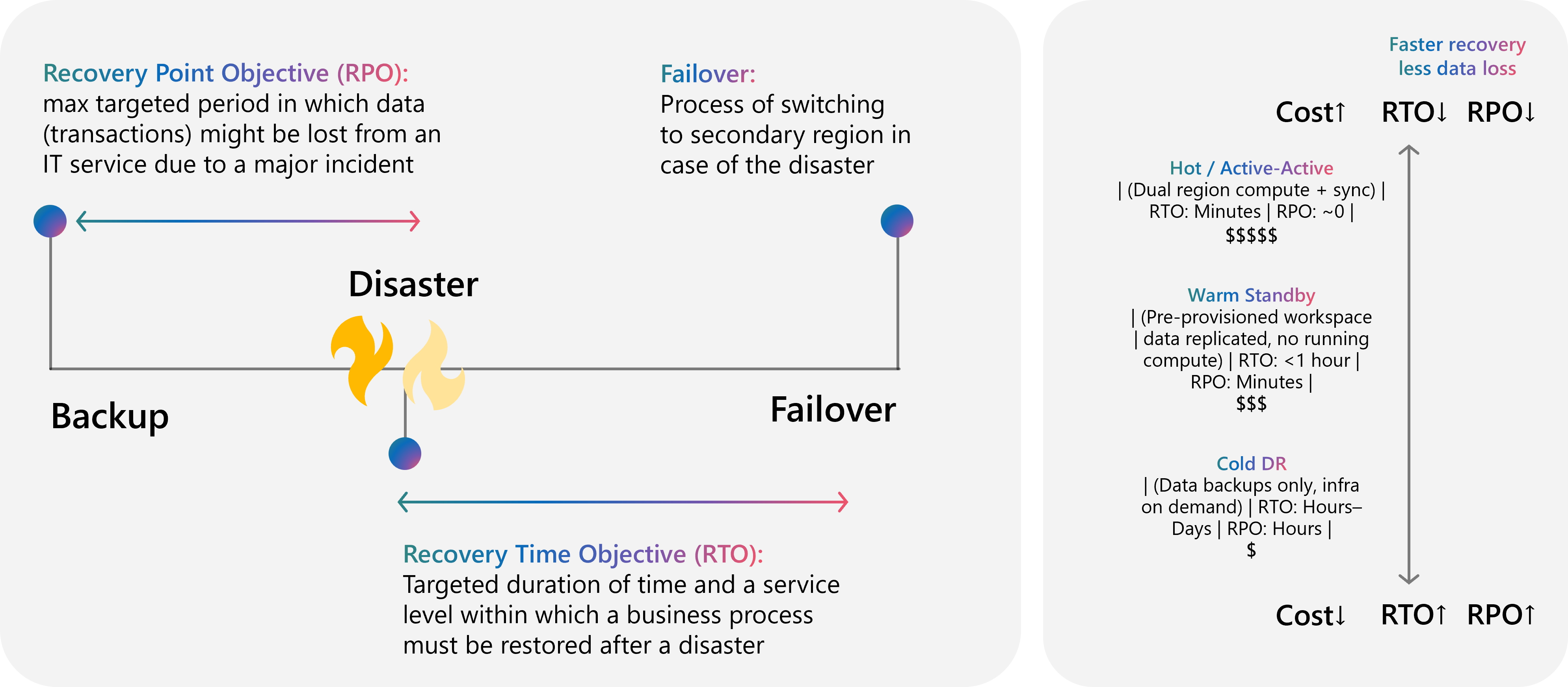
Como RTO, RPO e trade-offs guiam as decisões?
Antes de implementar qualquer solução, é fundamental alinhar os objetivos de negócio com as capacidades de engenharia:
- RTO (Recovery Time Objective): Qual o tempo máximo aceitável para restauração?
- RPO (Recovery Point Objective): Qual o volume máximo de perda de dados tolerável?
Como evidenciado na Figura 1, o design da solução é ditado pelo equilíbrio entre custo e performance:
- Active-Active: Arquitetura hot que minimiza quase integralmente downtime e perda de dados, porém com custo mais elevado.
- Warm Standby: Um meio-termo estratégico que equilibra custos de infraestrutura no modo standby com tempos aceitáveis de failover.
- Cold DR: Opção de menor custo para cenários com RTO elevado, aceitando maior risco de perda de dados.
Como desenhar o plano de resiliência em fases?
Fase 1: Discovery & Assessment
Em ambientes de alta complexidade, o primeiro passo é a visibilidade. É necessário consolidar todos os ativos, dependências e padrões de uso. Sem um inventário real da plataforma, o plano de DR será nativamente falho. A meta nesta fase é criar um baseline autoritativo que viabilize a priorização de workloads.
Figure 2. Different Phases of Azure Databricks Disaster Recovery

Fase 2: Strategy & Design
Aqui, definimos o comportamento da plataforma em falhas. A decisão crítica envolve a separação por workload tiers:
- Tier 1 (Mission-critical): Requer alta disponibilidade com Active-Active e replicação completa.
- Tier 2 (Business-critical): Pode suportar modelos Active-Passive com replicação seletiva (ex: Bronze-only ou Gold-only para reduzir custos de recomputação).
Figure 3. Active - Active Scenario - Continuous Trigger Mode
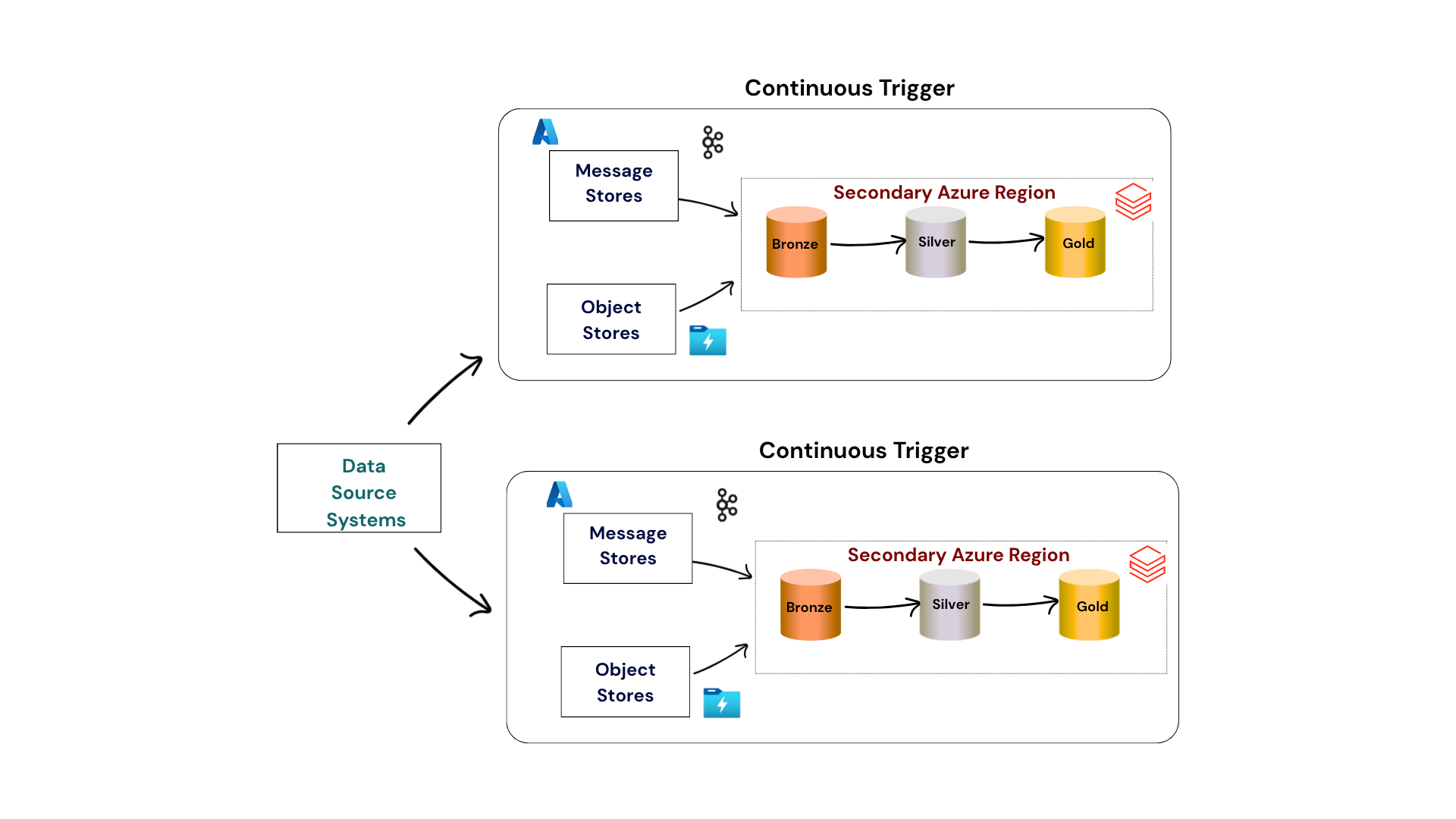
Figure 4. Active - Passive Scenario - Clone All Layers Mode
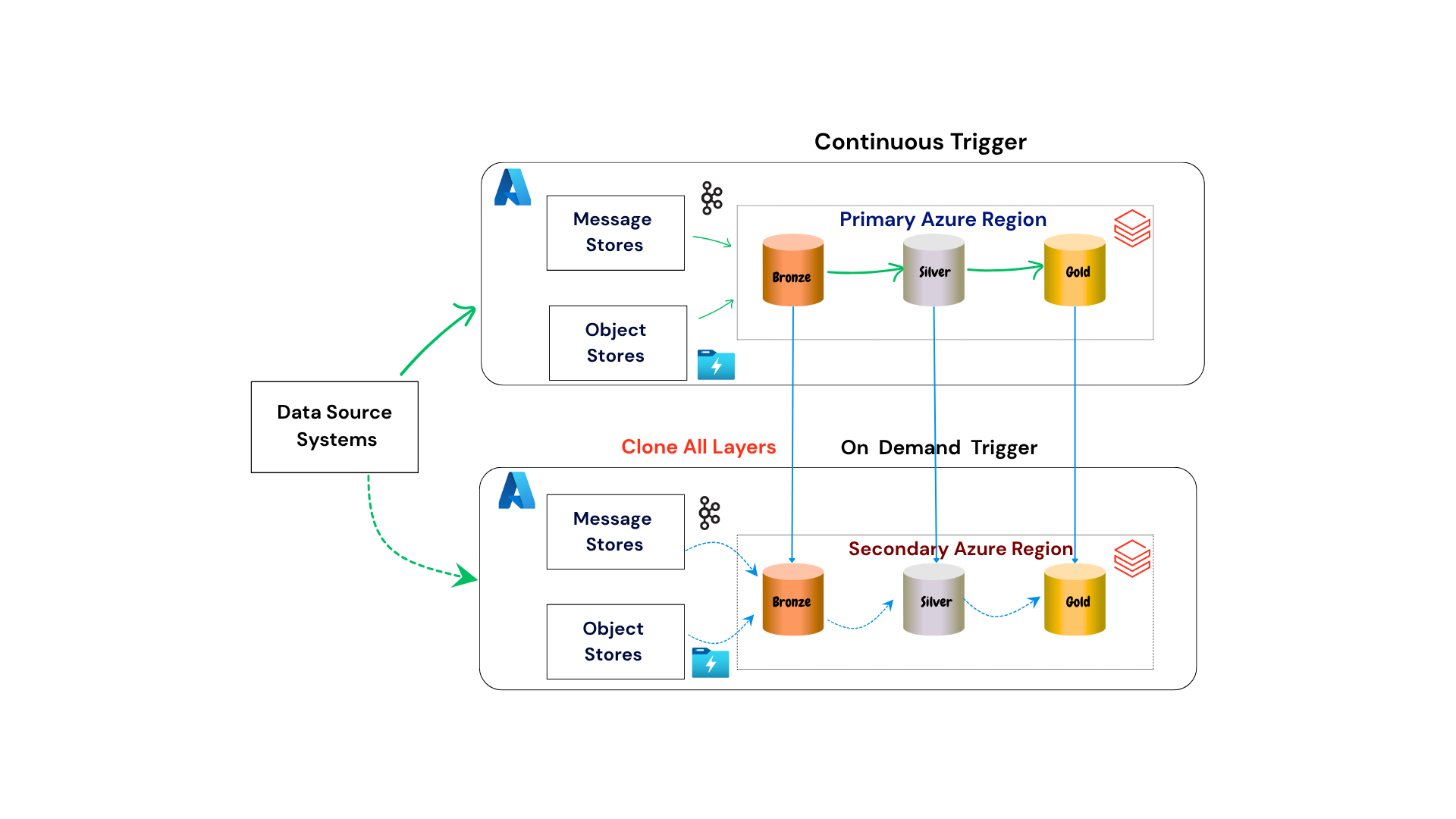
Fase 3: Implementação e Enablement
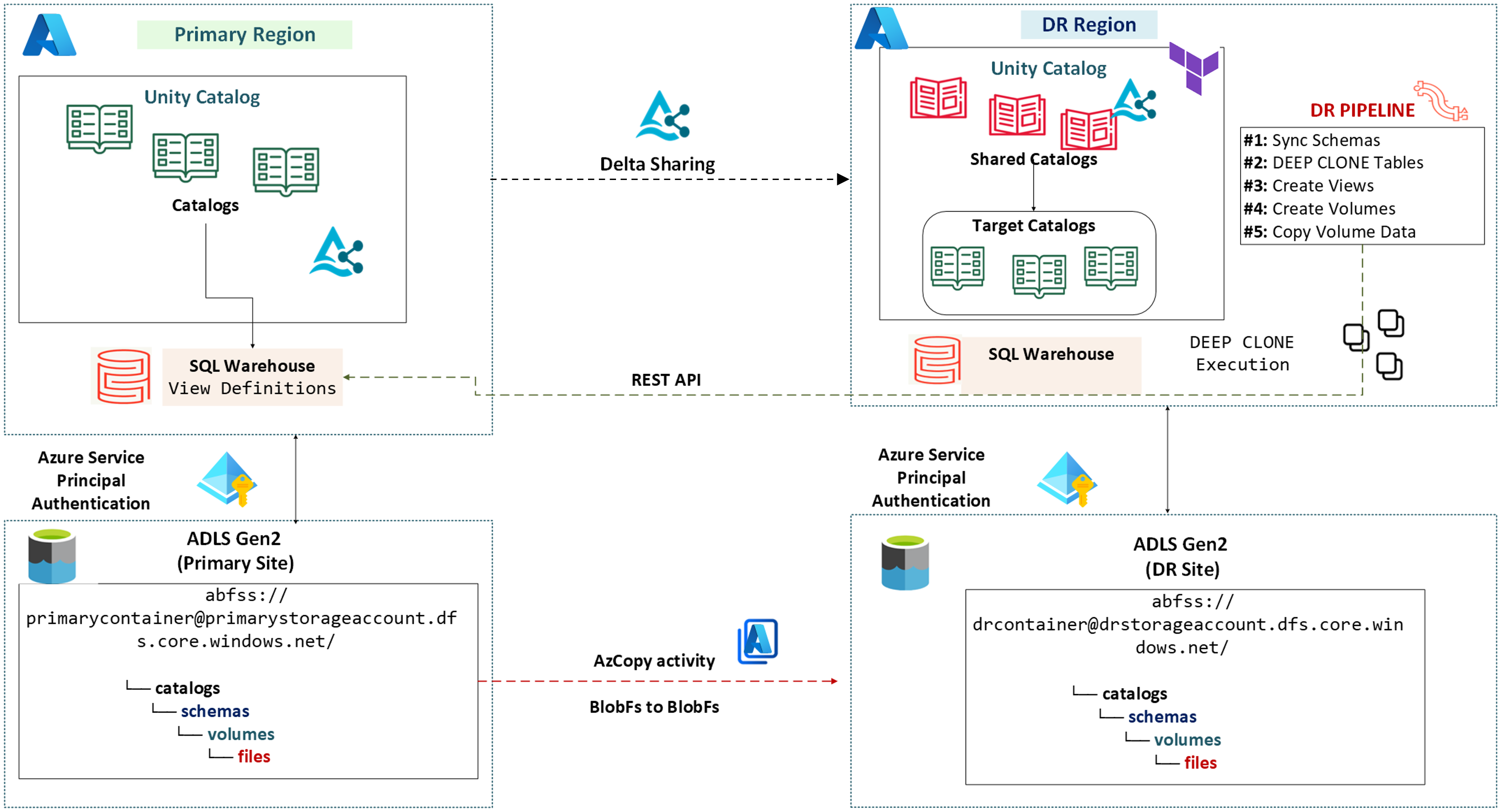
A arquitetura deve ser pensada em camadas, replicando ou recriando componentes através de IaC (Infrastructure as Code) e pipelines de CI/CD. O foco deve ser na portabilidade de workspaces e, principalmente, em estratégias de replicação orientadas pelo Unity Catalog.
Figure 5. Unity Catalog Focused DR Mechanisms
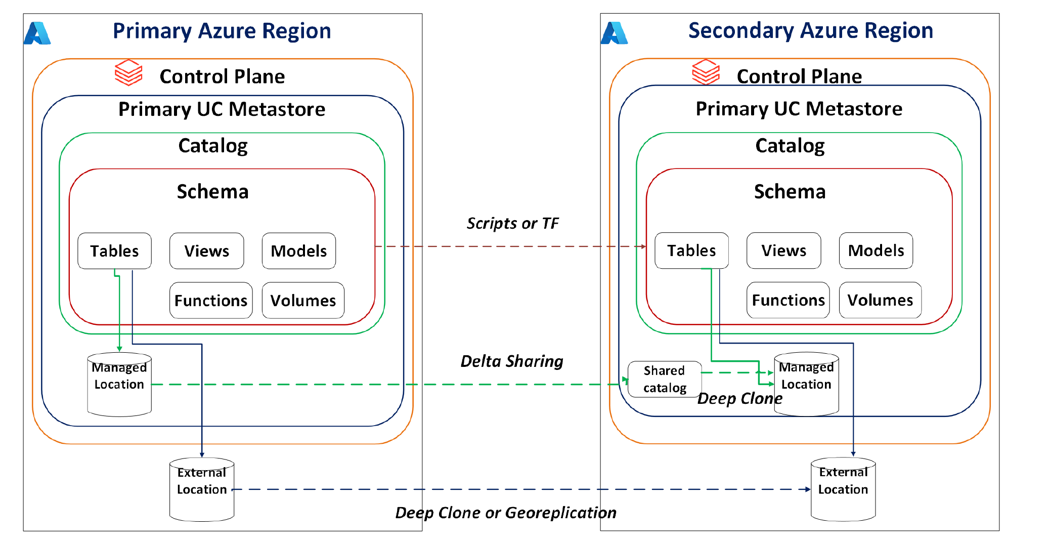
Fase 4: Validação e Melhoria Contínua
Um plano de DR que não é testado não existe. O DR drill deve validar a simplicidade do processo de failover e failback. A operação contínua deve englobar monitoramento, alerting, governança e constante ajuste das faixas de scaling para evitar gargalos.
Figure 6. Azure Databricks DR Replication Workflow
Perguntas Frequentes
- Como o RTO afeta o custo do meu ambiente Databricks?
Um RTO mais rigoroso exige arquiteturas Active-Active ou Warm Standby, que aumentam significativamente os custos de licenciamento e infraestrutura, enquanto opções de Cold DR focam na economia à custa de tempos de restauração mais longos. - Qual o impacto do Unity Catalog na estratégia de resiliência?
O Unity Catalog centraliza a governança; sua replicação entre regiões é a espinha dorsal de um DR bem-sucedido, pois sem os metadados sincronizados, os dados replicados no storage perdem sua utilidade para o compute. - É possível replicar apenas camadas específicas da arquitetura Medallion?
Sim, é uma estratégia recomendada para otimização de custos em Tiers de menor criticidade, onde você pode replicar apenas as camadas Bronze ou Gold, aceitando a necessidade de recomputação em um evento de desastre.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
