

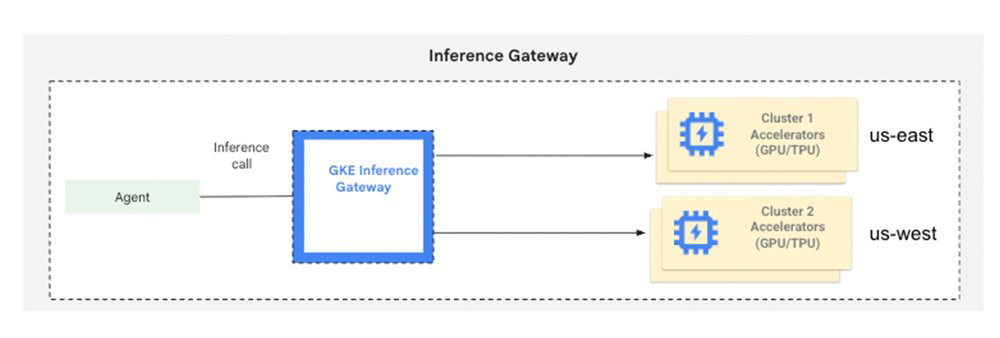
O amadurecimento das aplicações de Inteligência Artificial trouxe um desafio crítico para os times de engenharia: como servir modelos de forma confiável e em escala global? O anúncio do multi-cluster GKE Inference Gateway ataca diretamente o problema da gestão de inferência distribuída em múltiplos clusters do Google Kubernetes Engine (GKE), estendendo a lógica da Gateway API para um cenário de alta complexidade.
Como extensão da GKE Gateway API, este recurso utiliza a infraestrutura de multi-cluster Gateways para criar uma camada de load balancing orientada não apenas por latência, mas pela saúde e capacidade dos modelos de IA.
O desafio do modelo único na IA
A abordagem de rodar workloads de IA em um cluster único tornou-se um gargalo arquitetural à medida que as empresas buscam globalização e resiliência. Os riscos são claros:
- Limitações de disponibilidade: Falhas regionais ou janelas de manutenção impactam diretamente o SLA do serviço.
- Teto de escalabilidade: A escassez de instâncias com GPU/TPU em uma zona específica pode impedir o crescimento do modelo.
- Silos de recursos: A subutilização de hardware em um cluster, enquanto outro sofre com concorrência, é uma ineficiência clássica de FinOps.
- Latência: A distância física entre o usuário e o cluster que hospeda o modelo degrada a experiência do usuário final.
O multi-cluster GKE Inference Gateway resolve isso permitindo que você trate diferentes clusters como um pool unificado de recursos. Além da alta disponibilidade e do bursting entre clusters, o grande diferencial técnico aqui é o roteamento "model-aware". Com o uso de GCPBackendPolicy, é possível realizar o load balancing baseado em métricas customizadas, como o estado da KV cache, algo essencial para manter o throughput e a eficiência em modelos de LLM.
Arquitetura e operação: a separação entre Config e Target clusters
O funcionamento baseia-se em dois recursos customizados (CRDs): InferencePool e InferenceObjective. O InferencePool agrupa pods que compartilham os mesmos requisitos de hardware, enquanto o InferenceObjective define as prioridades de serviço, permitindo a multiplexação de tarefas sensíveis a latência versus tarefas de processamento em batch.
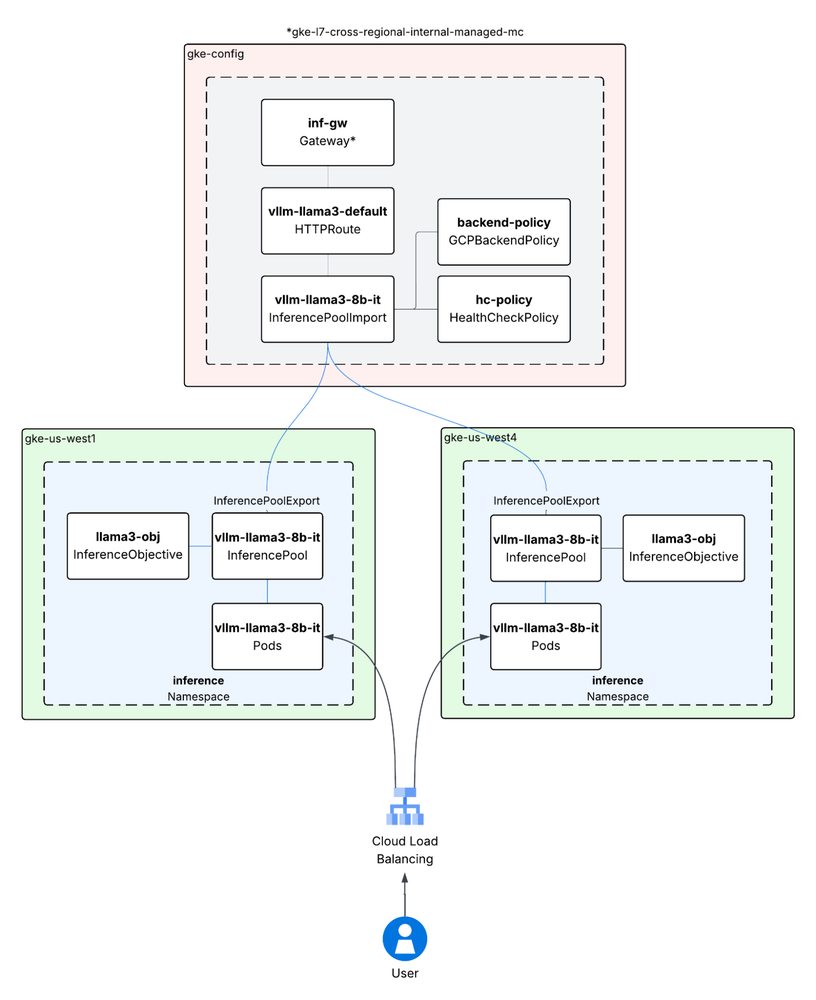
Nessa arquitetura, a operação segue um fluxo interessante: os InferencePools nos clusters de destino (target clusters) exportam backends que se tornam GCPInferencePoolImport no seu cluster de configuração (config cluster). A partir daí, o tráfego é roteado seguindo as diretivas definidas via Gateway e HTTPRoute. A aplicação de CUSTOM_METRICS via GCPBackendPolicy permite uma granularidade inédita, garantindo que o backend que responde ao request seja exatamente o que está mais bem preparado para processá-lo naquele milissegundo. Essa abordagem é um avanço significativo para times que operam em escala global e buscam automação em seus pipelines de deployment e operação de modelos.
Artigo originalmente publicado por Andres GuedezSenior Staff Software Engineer em Cloud Blog.
