

TLD;DR: Escalabilidade em LLMs
Este artigo explora os desafios práticos de escalar a inferência de LLMs no Azure Kubernetes Service (AKS), focando em como evitar o superdimensionamento e reduzir a latência. A conclusão principal é que métricas padrão (como CPU/memória) são insuficientes; o uso do NVIDIA Dynamo combinado com KEDA, orquestrando métricas específicas de LLM (como TTFT), permite um escalonamento inteligente que melhora a experiência do usuário e otimiza custos operacionais em ambientes de alta demanda.
A transição de modelos de linguagem (LLMs) da fase experimental para produção traz desafios técnicos que muitas equipes ainda subestimam. Enquanto o treinamento ganha holofotes, a inferência em escala revela uma complexidade operacional real: como equilibrar performance (SLA), custo e experiência do usuário sob tráfego imprevisível?
Neste artigo, analisamos como o uso do Azure Kubernetes Service (AKS) em conjunto com o NVIDIA Dynamo permite construir uma plataforma de inferência pronta para o mercado, focando em estratégias de autoscaling que vão além do óbvio.
Por que o autoscaling de inferência de LLMs é um desafio complexo?
O oversized (superdimensionamento) em GPUs gera desperdício severo de custos, enquanto o undersizing degrada drasticamente a latência percebida.
1. Métricas não-lineares
O custo de processamento de um request em uma LLM varia drasticamente dependendo de:
- Tamanho e precisão do modelo.
- Comprimento dos tokens de entrada e saída.
- KV cache hit rate.
Monitorar apenas CPU ou memória é um "tiro no escuro". O uso de recursos de GPU não traduz fielmente a pressão real da carga de trabalho.
2. Defasagem na esteira (Pipeline Multi-Fase)
A inferência de LLM é um processo sequencial composto por:
- Prefill (context processing).
- Routing.
- Decode (geração de tokens).
Cada fase possui requisitos de recursos distintos. Tentar escalar tudo como um bloco único é ineficiente.
3. As limitações do autoscaling em GPU
Ao contrário de instâncias tradicionais, GPUs:
- Têm provisioning mais lento.
- São menos elásticas.
- Apresentam restrições de disponibilidade e custos elevados.
Para times de engenharia, a estratégia vencedora foca em packing eficiente e a manutenção de capacidade "quente" de forma orquestrada.
Otimizando a infraestrutura no Azure
O portfólio de VMs otimizadas para IA no Azure exige uma curadoria baseada em requisitos claros: throughput, latência (SLOs) e custos. O AKS provê a base necessária através de node pools com autoscaling nativo, permitindo que a infraestrutura se molde à demanda atual.
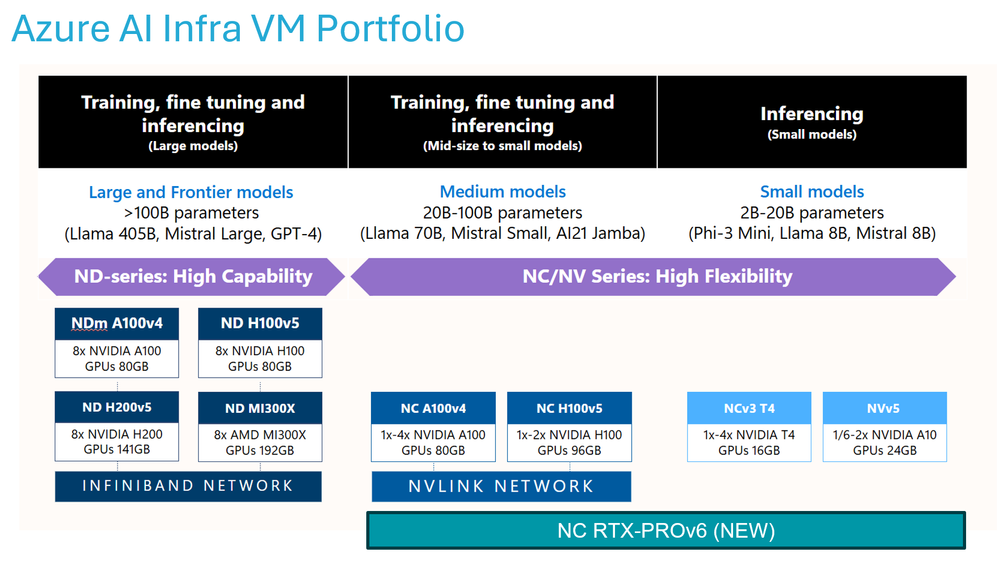
O que compõe o ecossistema NVIDIA Dynamo no AKS?
O NVIDIA Dynamo não é apenas mais uma ferramenta; ele orquestra a inferência como um sistema único:
- Smart Routing: Distribuição inteligente entre workers.
- KV Cache Management: Otimiza a eficiência de memória.
- Low-Latency Communication: Otimização crítica de GPU-to-GPU.
- GPU Planner: Coordenador de decisões de escala.
A "mágica" do autoscaling: Integrando Dynamo e AKS
O diferencial está na integração nativa com o ecossistema Kubernetes. O Dynamo expõe subresources que se comunicam perfeitamente com:
- Kubernetes HPA (Horizontal Pod Autoscaler).
- KEDA (Event-Driven Autoscaling).
- Dynamo Planner.
- Observability: Através do Azure Managed Prometheus e Grafana, obtemos visibilidade em tempo real sobre queue depth, latência de tokens e decisões de scaling baseadas em dados.
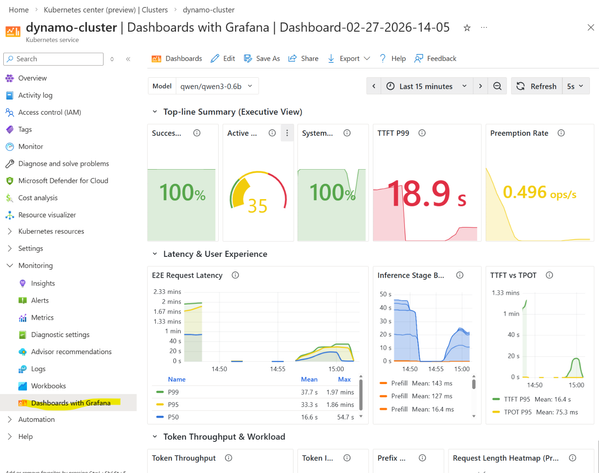
Quatro estratégias para fazer o autoscaling funcionar
- Kubernetes HPA: Ideal para serviços frontend leves.
- KEDA: Perfeito para métricas externas, scale-to-zero e limites fixos.
- Dynamo Planner: O padrão ouro para inferência, permitindo escalonamento desagregado (Prefill vs. Decode) focado em SLAs como TTFT (Time to First Token).
- Custom Controllers: Para lógica de negócio complexa ou necessidades de nicho.
Alinhamento de métricas: O segredo da estabilidade
A lição de casa em produção é garantir que o sinal de scaling reflita o gargalo real:
- Frontend: CPU e Request Rate.
- Prefill Workers: Queue depth e TTFT.
- Decode Workers: KV cache utilization e ITL (Inter-token latency).
Melhores práticas para evitar o retrabalho
- Evite conflitos: Não coloque múltiplos autoscalers brigando pelo mesmo workload.
- Estabilização é vital: Configure janelas de estabilização adequadas para evitar o thrashing (escala-sobe-e-desce contínuo).
- Limites conservadores: Evite min/max replicas arbitrários; entenda seus padrões de tráfego antes de definir os limites.
Análise de caso: TTFT Driven com KEDA
Ao rodar um workload com tráfego constante de 36 RPS, o uso de TTFT p95 como sinal de escala provou ser muito superior a métricas de utilização de hardware.
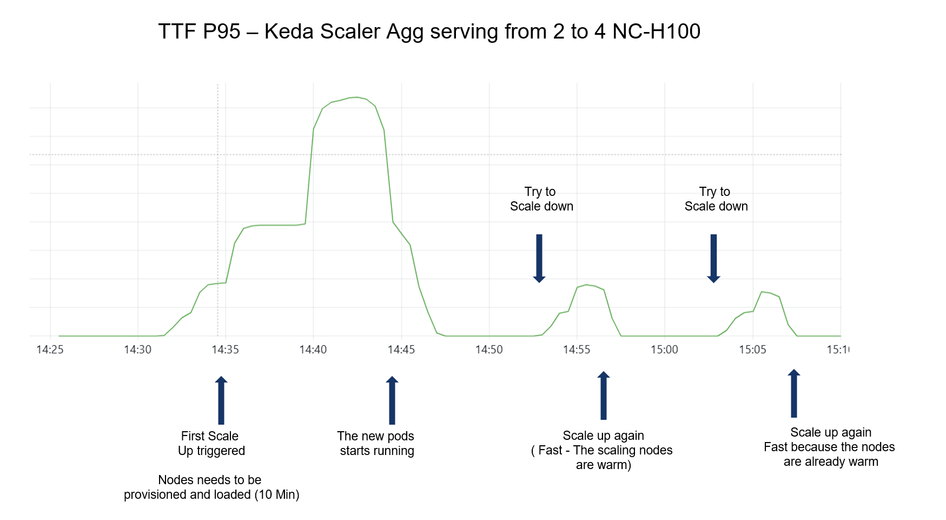
Lições aprendidas na timeline:
- Cold Start: A subida inicial leva cerca de 8 minutos para provisão de nós e carregamento do modelo.
- Warm Scaling: Segundas e terceiras instâncias de scale-up são quase imediatas enquanto os nós permanecem "quentes" (drivers e modelos carregados).
- Cooldown: Definir um tempo de cooldown de 120 segundos foi essencial para evitar que a redução de escala matasse instâncias que continuavam sendo necessárias para manter o SLA sob carga constante.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
