

As métricas do Kubernetes são o termômetro do seu cluster. Mais do que números em um dashboard, elas representam a saúde da sua infraestrutura e o comportamento das aplicações que sustentam o core business da sua empresa. Sem uma estratégia clara de monitoramento, você fica cego diante de gargalos de performance e riscos de indisponibilidade que podem impactar diretamente o seu SLA.
Neste artigo, analisamos quais métricas são fundamentais, como coletá-las e de que forma essa telemetria deve orientar a tomada de decisão técnica em ambientes produtivos.
O que são métricas no Kubernetes?
As métricas no Kubernetes não são meros logs; elas são indicadores de performance do seu ecossistema. Elas fornecem visibilidade sobre o control plane, os nós e as workloads. Identificar padrões de anomalias nessas métricas permite que equipes de engenharia atuem de forma proativa, evitando que problemas de latência ou exaustão de recursos virem incidentes de crise.
Tipos de métricas no Kubernetes
Podemos categorizar as métricas em camadas, cada uma entregando um contexto diferente para o sucesso da operação.
Métricas do Cluster
O cluster é o ambiente global. Analisar estas métricas é um exercício fundamental de capacidade e eficiência.
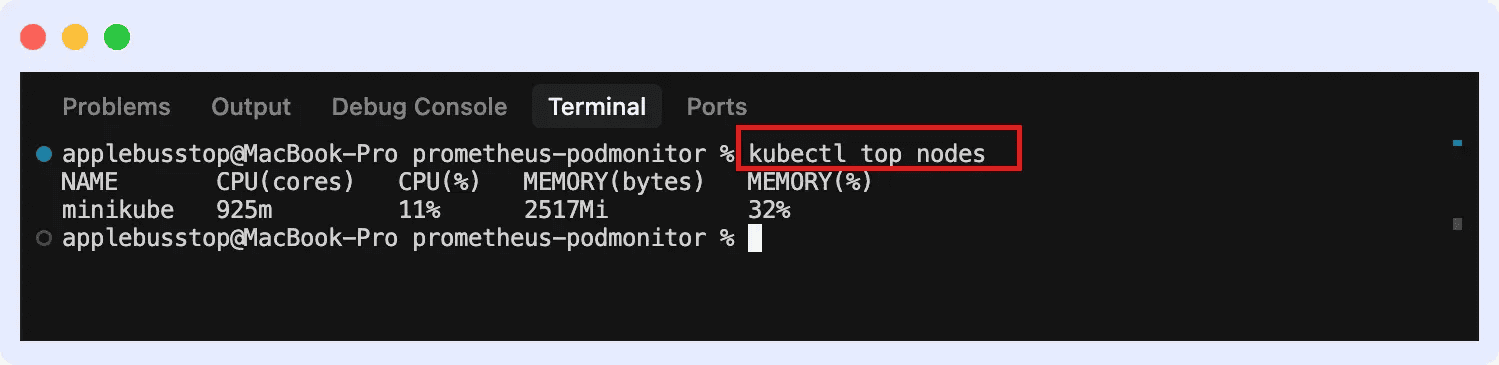
1. Node CPU resource usage
Monitorar a utilização de CPU permite identificar se o seu ambiente está superdimensionado (desperdiçando budget de cloud, o que é um ponto crítico em FinOps) ou sobrecarregado, gerando throttling de containers.
2. Node memory usage
O gerenciamento de memória é sensível. Entender o working set memory e o RSS é vital para evitar o OOMKilled (Out Of Memory Killed) em seus pods. Se o consumo de memória toca o limite da máquina, o Kubernetes iniciará despejos (evictions) agressivos.
3. Node disk usage
O esgotamento de disco em um node é um cenário de falha crítica: o kubelet começará a remover pods para liberar espaço, o que pode derrubar serviços essenciais de forma inesperada.
Métricas de Node
Além dos recursos básicos, o foco deve estar na saúde da infraestrutura de execução.
1. Disk I/O e espaço disponível
O alto I/O pode transformar sua aplicação em uma garrafa de gargalo. Monitorar a latência de disco é essencial para aplicações com carga alta de banco de dados ou processamento de arquivos.
2. Network bandwidth usage
O tráfego de rede é frequentemente negligenciado. Gargalos aqui resultam em latência na comunicação entre pods e serviços, afetando a experiência do usuário final.
Métricas do Control Plane
O control plane é o cérebro do cluster. Se ele falha, o cluster para.
1. API server request latencies
Se a latência das chamadas à API aumenta, o tempo de deployment e a capacidade de autorrecuperação do cluster caem. É um indicador precoce de que o cluster atingiu um limite de densidade.
2. Scheduler queue length
Uma fila grande de pods "Pending" indica desbalanceamento de recursos ou falta de capacidade. Isso afeta diretamente a escabilidade horizontal da sua aplicação.
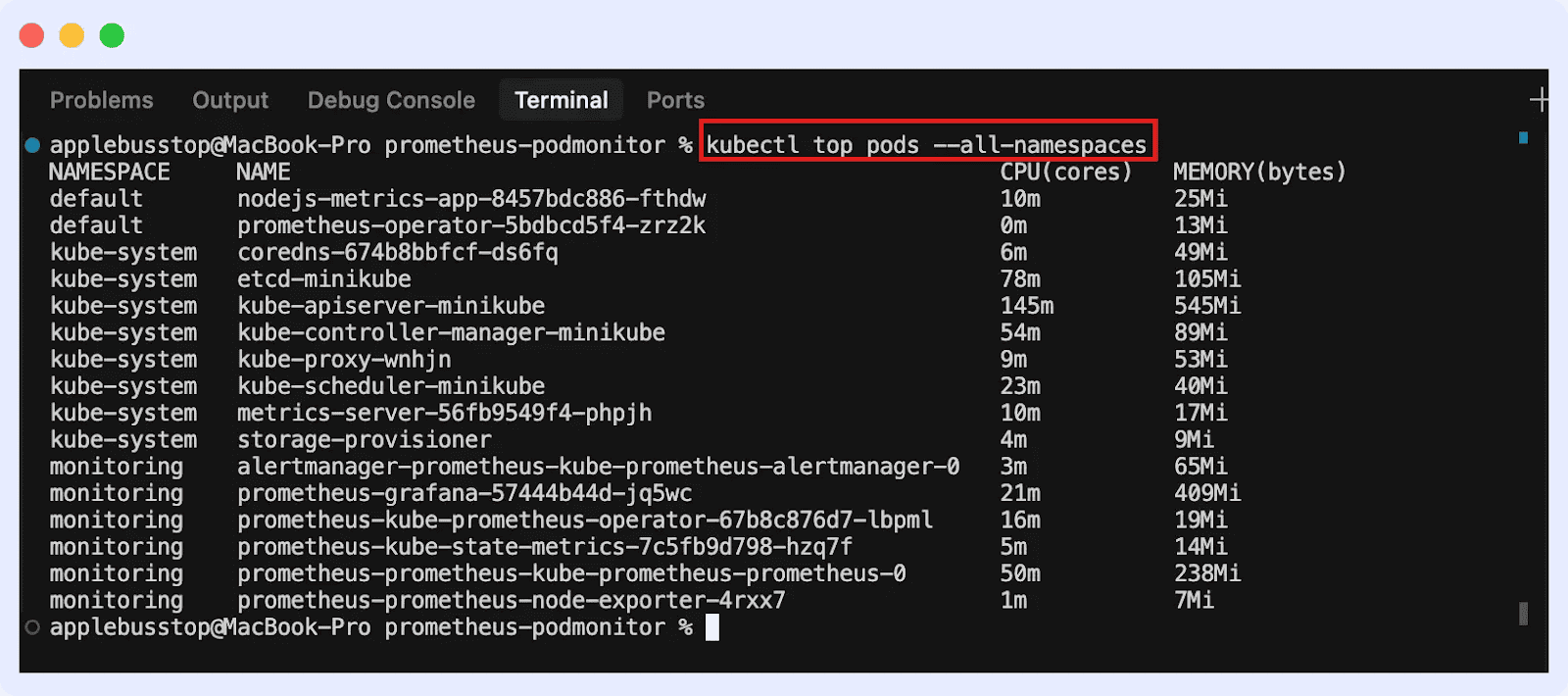
Métricas de Pod
Aqui reside a performance da aplicação propriamente dita. O foco deve ser na resiliência:
1. Pod Restart Count
Aumentos repentinos em restarts indicam problemas de configuração, vazamento de memória ou dependências mal respondidas (ex: falta de conexões com banco de dados).
2. Pending Pod Count
Monitorar pods pendentes é essencial para garantir a agilidade do seu pipeline de CI/CD.
3. Pod Status
Manter um monitoramento constante do status via kubectl get pods é o basilar, mas idealmente deve ser automatizado via alertas de observabilidade.
Como coletar métricas no Kubernetes
O Kubernetes não armazena métricas nativamente com histórico longo. Você precisa de ferramentas robustas.
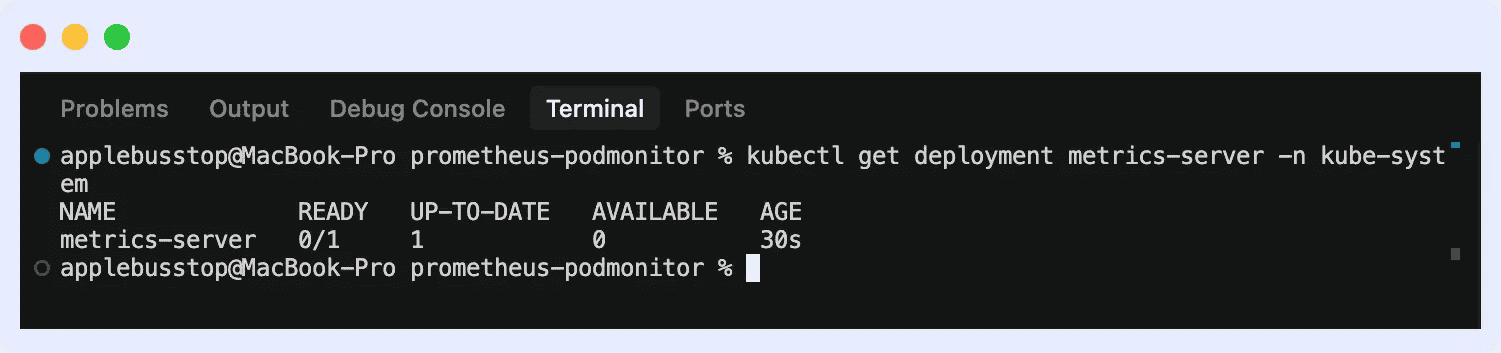
Metrics Server
É o básico para consumo de recursos em tempo real. Essencial para o funcionamento do Horizontal Pod Autoscaler (HPA).
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
cAdvisor
Integrado ao kubelet, ele é a fonte primária de dados de containers que Prometheus costuma consumir.
Kube-State-Metrics
Indispensável. Ele foca no estado dos objetos no cluster (ex: quantos pods deveriam estar rodando versus quantos efetivamente estão). Instalação via Helm é o caminho recomendado para ambientes produtivos:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install kube-state-metrics prometheus-community/kube-state-metrics
Conclusão
Monitorar métricas não é apenas instalar dashboards, é entender o comportamento do seu sistema sob carga. A observabilidade eficiente é o que separa empresas que crescem com sustentabilidade daquelas que convivem com a instabilidade crônica.
Artigo originalmente publicado por Sam Suthar, Middleware em Cloud Native Computing Foundation.
