

Do Caos à Clareza: Centralizando a Observabilidade no seu Workspace Databricks
Este artigo discute como a complexidade crescente em ambientes Azure Databricks — exacerbada pela criação descontrolada de clusters, jobs e warehouses — dificulta a governança e o controle de custos. A conclusão principal é que uma visibilidade centralizada (uma single pane of glass) é pré-requisito obrigatório para qualquer estratégia de FinOps, transformando o gerenciamento de ativos baseado em suposições (tribal knowledge) em decisões técnicas fundamentadas e escaláveis.
À medida que os ecossistemas de dados crescem, a pergunta que assombra gestores de TI e times de Data Platform no Brasil é sempre a mesma: “O que realmente temos rodando neste workspace?” Com o passar do tempo, a explosão de clusters, a clonagem de jobs e a proliferação de SQL warehouses criam uma dívida técnica e financeira difícil de auditar. A descentralização das squads, onde cada team opera seu próprio ambiente, agrava a falta de visibilidade central.
Para mitigar esse cenário, a implementação de uma arquitetura de Discovery é o primeiro passo para o controle. A ideia é catalogar todo o inventário de ativos e consolidá-lo em um repositório Delta-based, estruturado e consultável, permitindo que a camada de FinOps e a engenharia de dados atuem com precisão.
Como a fase de Discovery estrutura os dados?
O processo de inventário é baseado em uma arquitetura paralela composta por dez scanners especializados. Eles funcionam de maneira hierárquica:
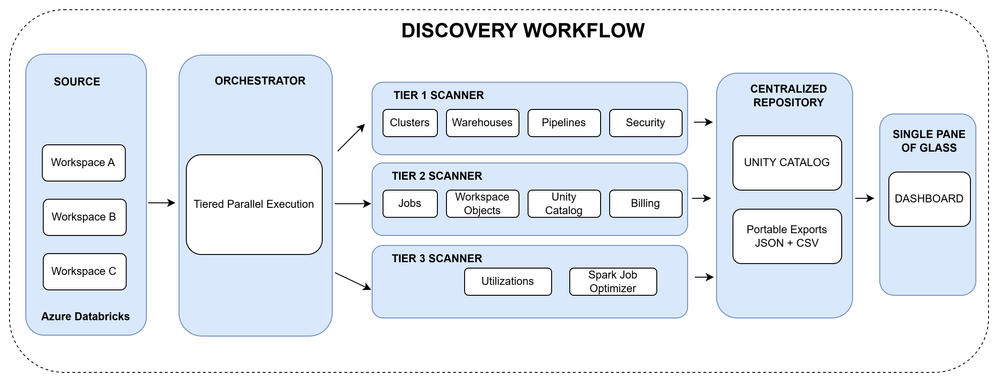
| Scanner | O que é catalogado |
|---|---|
| Clusters | Tipos (Interactive, job, SQL), configs, políticas e pools |
| Jobs | Workflows, agendamentos, tarefas e histórico de runs |
| Warehouses | Endpoints SQL, tamanhos e configurações serverless |
| Pipelines | Estado e definição de Delta Live Tables |
| Unity Catalog | Catalogs, schemas, tabelas e volumes |
| Workspace Objects | Notebooks, repos, experimentos ML e serving endpoints |
| Security | IAM, redes e configurações de proteção de dados |
| Billing | Histórico de 30–180 dias de DBU por SKU |
| Utilization | Métricas reais de CPU, memória e padrões de uso |
| Spark Job Optimizer | Detecção de skew, spill, pequenos arquivos e broadcast hints |
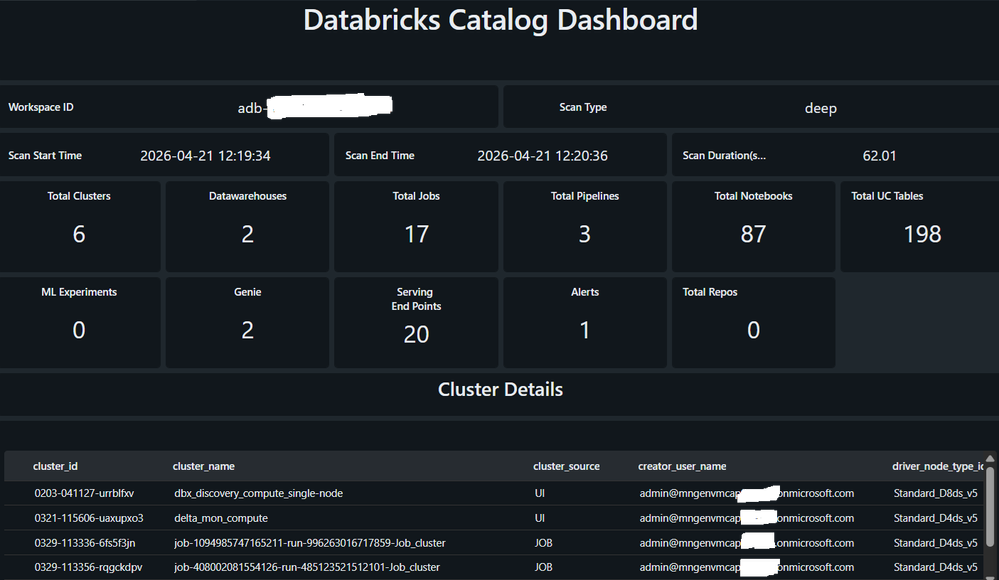
O valor prático do "Single Pane of Glass"
Centralizar esses dados em um banco de dados queryable não é um exercício de burocracia, mas uma alavanca para eficiência operacional. Com um dashboard, é possível:
- Identificar "Ghost Resources": SQL warehouses rodando 24/7 com zero queries, prontos para desligamento.
- Ajuste de Compute: Jobs rodando em instâncias caras sem necessidade técnica, utilizando o histórico para rightsizing.
- Trend Analysis: Acompanhar semanalmente a tendência de sprawl (expansão descontrolada) da plataforma.
Conclusão
O Discovery é o pilar da maturidade em governança. Sem o conhecimento exato do que existe em produção, qualquer tentativa de optimization de custos ou performance é, por definição, incompleta. Ao converter metadados em visão clara, o time de engenharia finalmente retoma o controle sobre a sprawl, preparando o terreno para as etapas de Analysis, onde os riscos são eliminados e a eficiência é maximizada.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
