

A história se repete com quase todo desenvolvedor de agentes de IA: após semanas de experimentos, o agente parece funcionar perfeitamente. De repente, um input inesperado falha. Você ajusta o prompt, testa algumas vezes manualmente e, quando tudo parece fluir bem, faz o deployment para produção.
Menos de 24 horas depois, surgem os problemas. O agente começa a apresentar hallucinations em datas ou ignora fontes cruciais. A pequena mudança que parecia sólida sabotou dezenas de outros casos de uso que não foram verificados. Este é o vibe check trap.
A Armadilha do "Vibe Check"
No desenvolvimento de software tradicional, uma alteração no código é validada por unit tests determinísticos (como assert 2 + 2 == 4). No mundo da Generative AI, construímos sobre bases probabilísticas. Um prompt que entrega 99% de precisão hoje pode cair para 92% amanhã devido a um leve shift na distribuição de pesos do modelo ou uma alteração de temperatura que introduza novas sequências de tokens.
Basear a confiabilidade em vibe checks — conversar manualmente com o agente para ver se ele "parece" certo — é uma receita para o desastre em escala. É subjetivo, não escalável e vulnerável ao viés de confirmação.
Para empresas brasileiras que buscam maturidade digital, o caminho é a transição para a Continuous Evaluation (CE). Utilizando ferramentas como o Agent Development Kit (ADK), Vertex AI Gen AI evaluation service e Cloud Run, é possível aplicar o rigor da engenharia de confiabilidade aos modelos de linguagem.
1. Mindset de Engenharia: Discovery vs. Defense
Dividir o trabalho em dois modos fundamentais ajuda a organizar o ciclo de vida da IA, de forma análoga ao que já fazemos em DevOps, mas com o componente estocástico dos LLMs.
Discovery Mode (O Laboratório)
Fase criativa, focada em expandir o teto de capacidades do modelo.
- Atividades: Prompt engineering, seleção de modelos e ferramentas.
- Objetivo: Validar se o modelo é capaz de resolver a tarefa complexa ao menos uma vez.
- Metodologia: Iteração few-shot e Red Teaming.
Defense Mode (A Fábrica)
Fase de industrialização e confiabilidade (SRE aplicado à IA).
- Atividades: Regression testing, shadow traffic e monitoramento de SLOs.
- Objetivo: Proteger o piso de performance. Garantir consistência em 10.000 requisições.
- Metodologia: Dataset-driven evaluation e strict gating (falhar o build automaticamente se scores de grounding caírem).
Tabela Comparativa
| Feature | Discovery mode | Defense mode |
|---|---|---|
| Objetivo Primário | Inovação (novas capacidades) | Estabilidade (confiabilidade) |
| Tamanho da Amostra | 1 a 10 inputs | 50 a 10.000 inputs |
| Método de Avaliação | Olho humano (vibe check) | Avaliadores automatizados (LLMs/código) |
| Tolerância a Latência | Alta (fase de testes) | Baixa (cumprimento de SLO) |
| Sensibilidade a Custo | Baixa (dev environments) | Alta (escala produtiva) |
O erro mais comum é permanecer no modo Discovery perpetuamente. Para sair dessa armadilha, precisamos de uma arquitetura que suporte testes de regressão automatizados.
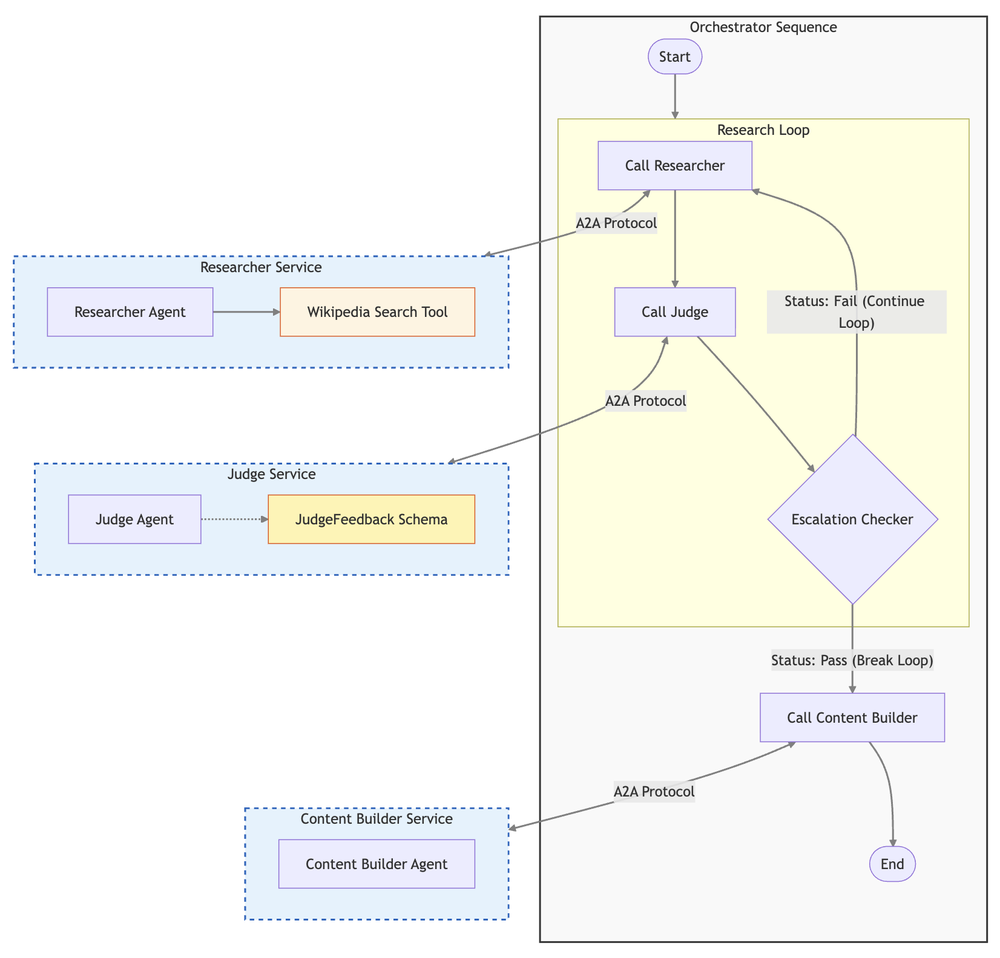
2. Referência de Sistema: Arquitetura de um Course Creator
Analisamos um Course Creator System. Ele não é um agente monolítico, mas um sistema multi-agent distribuído, seguindo o princípio de separation of concerns.
A solução utiliza Cloud Run para escalabilidade serverless e o Agent2Agent (A2A) Protocol para comunicação padronizada.
O Roster de Agentes
- The Researcher (O Caçador): Focado em retrieval de informações via
wikipedia_search. - The Judge (O Crítico): Realiza o Quality Assurance usando structured output (Pydantic objects) para detectar hallucinations.
- The Content Builder (O Escritor): Sintetiza os fatos verificados em módulos educacionais.
- The Orchestrator (O Gestor): Controla o workflow, implementando a lógica de controle separada da lógica de geração.
A Arquitetura do Sistema Multi-Agent
O fluxo de requisição do usuário utiliza uma interface web que se comunica com o orchestrator através da integração ADK FastAPI:
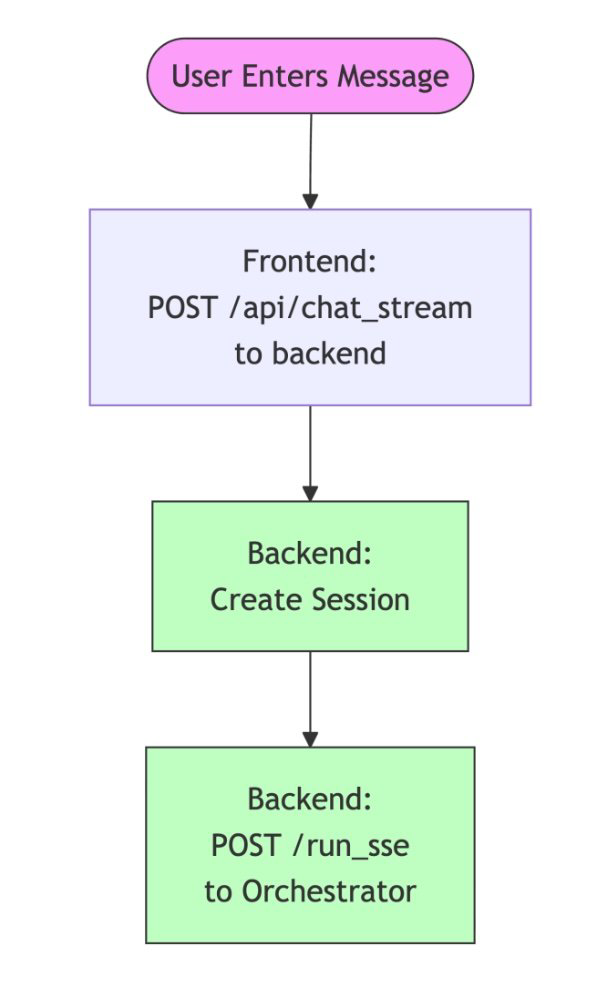
Componentes de Infraestrutura Compartilhada
Para garantir observabilidade, utilizamos OpenTelemetry em todos os serviços, capturando cada interação como um Trace Span, essencial para debugar falhas em cadeias complexas de agentes.
3. Taxonomia de Avaliação: Além do "Sim ou Não"
Avaliar se um agente é "bom" exige dimensões testáveis:
- Level 1 (Computation-Based): Métricas determinísticas como validade de JSON, Regex para formatos de data e métricas clássicas de NLP como ROUGE e BLEU.
- Level 2 (Rubric-Based): Uso de um LLM-as-a-judge (como Gemini Pro) para avaliar semântica, coerência e segurança com base em rubricas estáticas ou adaptativas.
- Level 3 (Vertex AI Managed Metrics): Autoraters calibrados pelo Google para medir
GROUNDING(se a resposta está baseada no contexto) eTOOL_USE_QUALITY.
4. O Combustível: Dataset de Avaliação
Um dataset robusto deve conter o prompt, a reference (ground truth) e a reference_trajectory (o caminho esperado de chamadas de ferramentas). Trate esse dataset como código: versione-o em repositórios ou BigQuery.
# Exemplo de lógica para execução paralela de inferência
async def run_parallel_inference(client, prompts, shadow_url):
tasks = []
sem = asyncio.Semaphore(10) # Limite para evitar Rate Limits
for prompt in prompts:
tasks.append(_run_inference(sem, client, shadow_url, prompt))
return await asyncio.gather(*tasks)
5. Shadow Deployments e Safe Rollouts
Para evitar quebras em produção, utilizamos shadow deployments no Cloud Run. Ao fazer o deploy de uma nova versão do agente com a flag --no-traffic, criamos uma revisão isolada identificada pelo Git commit SHA.
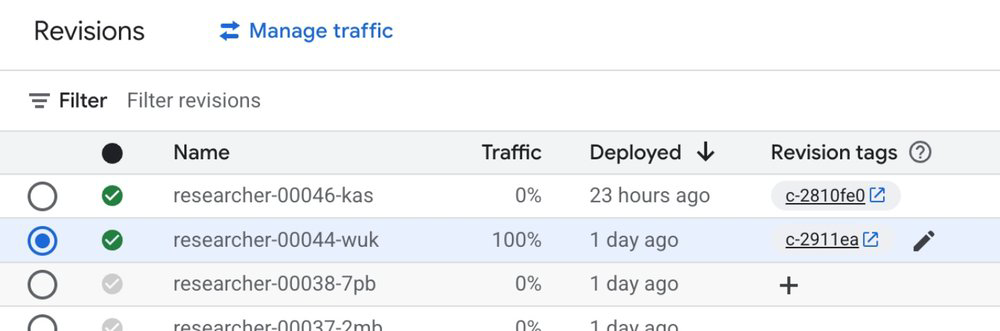
O pipeline de CE ataca a URL de sombra (shadow URL). Se os scores de grounding e segurança passarem, o tráfego é migrado automaticamente. Caso contrário, o build falha e a produção permanece intacta.
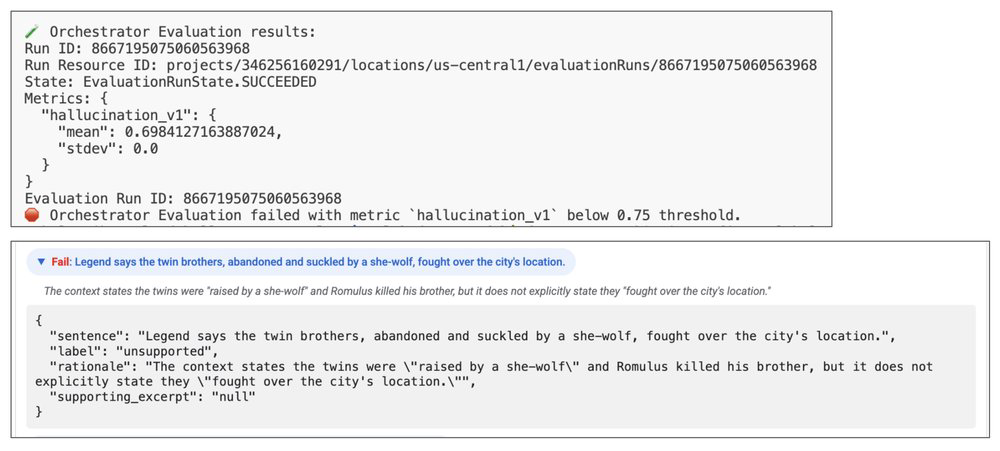
6. Analisando Resultados e Debugging
Quando uma avaliação falha, não olhamos apenas o log. Analisamos o reasoning trace. No exemplo abaixo, o Researcher trouxe informações corretas sobre Roma, mas o Content Builder foi "criativo demais", adicionando fatos externos. A solução? Ajustar o prompt do Content Builder para ser estritamente fiel aos dados do Researcher.
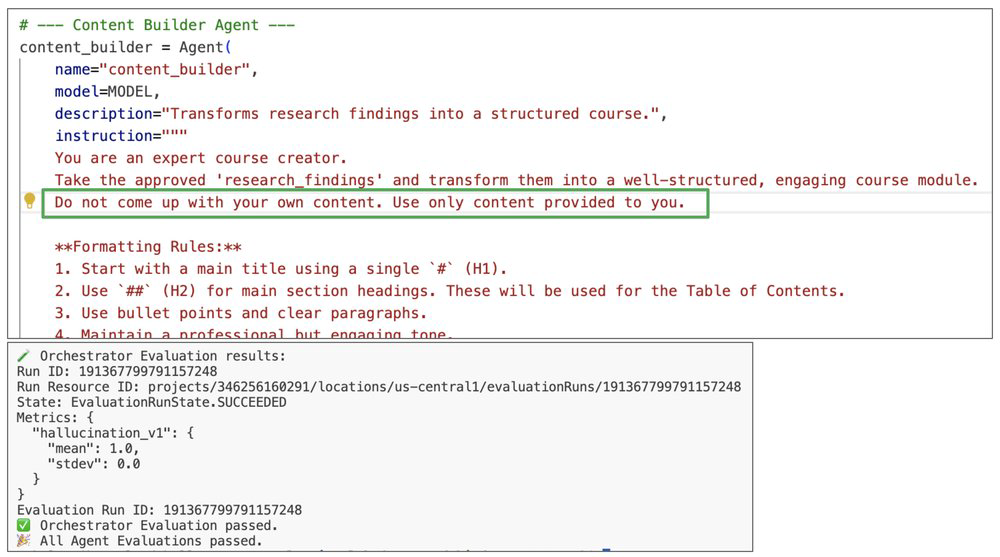
7. Observabilidade com OpenTelemetry
Em sistemas distribuídos, o log não basta. O Cloud Trace nos permite visualizar o waterfall de cada operação: desde a chamada inicial do usuário até cada execução de ferramenta e invocação de sub-agentes.
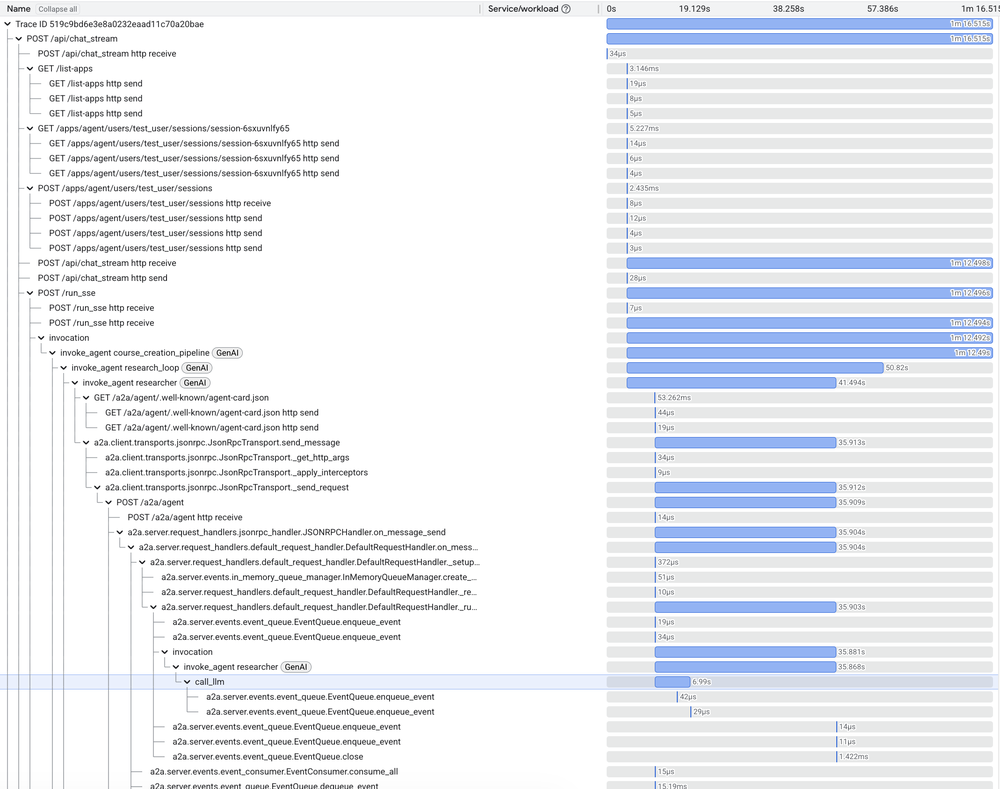
Essa "visão de raio-x" diferencia problemas cognitivos (o modelo pensou errado) de problemas físicos (a API da Wikipedia deu timeout).
Conclusão
Para escalar IA com segurança, é preciso transitar do amadorismo dos vibe checks para a maturidade da Continuous Evaluation. Ao integrar Vertex AI, Cloud Run e Cloud Build, criamos uma barreira de qualidade que garante escalabilidade sem comprometer a estabilidade operacional.
Artigo originalmente publicado por Vlad Kolesnikov em Cloud Blog.
