

A grande questão: você sabe o que está rodando?
Rápido: qual a versão exata da sua infraestrutura na assinatura de produção agora? Não aquela que seu último pipeline implantou, nem a que está em uma planilha de controle. O que está, de fato, rodando — neste segundo — e você consegue provar isso?
Se você precisou pausar para pensar, não está sozinho. Muitas empresas brasileiras escalam suas operações em cloud sem garantias claras de consistência, o que acaba gerando o desafio que nos levou a projetar o sistema que descrevemos aqui.
O incidente que mudou tudo
Imagine o cenário: um NSG rule quebrado na produção. Às 3 da manhã, um engenheiro corrige manualmente pelo Azure Portal, salva e volta a dormir. O problema técnico foi resolvido, mas a deriva (ou drift) foi instalada. Até a segunda-feira, ninguém percebeu que o ambiente real divergiu do código no Git. Não houve pipeline, não houve Terraform. Nossa "fonte da verdade" tornou-se obsoleta.
O erro aqui não é apenas o Terraform drift. É a facilidade de alterar a infraestrutura via Portal, CLI, PowerShell ou REST API. Sem um sistema que reconsidere o estado real, você perde o controle operacional.
A complexidade do ambiente em escala
A dificuldade é exponencial: um único ambiente Azure envolve dezenas de recursos (VNets, Key Vaults, storage accounts, Container App Environments, serviços de IA). Cada recurso possui dezenas de propriedades mutáveis. Multiplique isso por ambientes de lab, non-live e live, e por várias regiões de mercado. A divergência é inevitável.
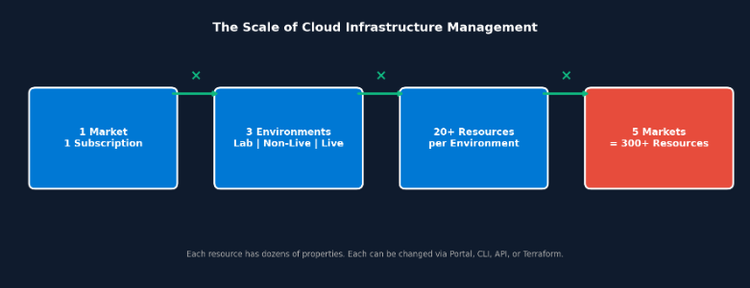
O que chamamos de "mercado"
Definimos "mercado" como uma unidade de negócio geográfica. Cada mercado opera em sua própria região (ex: UK South, Germany West Central), com seu próprio ciclo de vida e chaves de segurança. O segredo para escalabilidade é tratar cada mercado como uma cópia isolada de um mesmo blueprint.
Detecção de drift na prática
O segredo para um sistema "auto-reparável" é entender que o Terraform state não se atualiza sozinho se uma mudança ocorre via Portal. O reconciliation pipeline precisa ser ativado em dois níveis:
- O pipeline de reconciliação diário (ex: às 6 AM): compara versões de
registryestate filepara pegar erros em execuções depipeline. - O
terraform planagendado: este é obrigatório. Ele consulta o Azure e expõe quando os valores reais diferem do código:
~ resource "azurerm_network_security_rule" "example" {
~ access = "Allow" -> "Deny" # alterado manualmente fora do Terraform
}
Na sequência, o terraform apply reverte a alteração, garantindo a consistência.
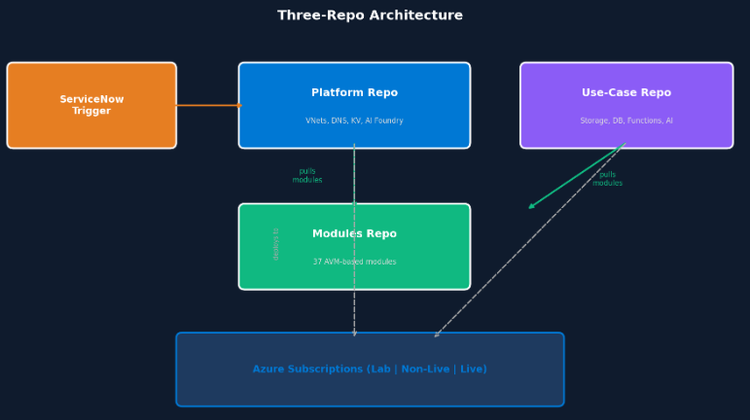
A arquitetura multi-repo
Separamos a operação em três repositórios, focados em governança:
- Platform Repo: O alicerce (redes, DNS, chaves). Acionado por tickets de serviço ou merges.
- Modules Repo: 37
modulesversionados, baseados emAzure Verified Modules. Sem injeção de código não verificado. - Use-Case Repo: Onde as squads implantam aplicações. Os desenvolvedores não escrevem
Terraformdo zero; eles apenas consomem blocos pré-aprovados.
Rastreamento de três camadas
Não confie em um único registro. Usamos três:
- Terraform State File: O registro bruto.
- Version Tracker: Um JSON gerado no
pipelinecom o SHA do commit e IDs de execução. - Subscription Registry: Um blob centralizado que centraliza o estado do que deveria estar rodando.
Quando os três se alinham, sua infrastructure-as-code é confiável. Quando não, o desvio é óbvio.
Lições de segurança e governança
- Sem segredos expostos: Tudo via OIDC (
OpenID Connect). - Endpoints privados: Public access fechado por padrão.
- Gatekeeping rigoroso:
terraform fmt,checkov,tfsececommitlintbloqueiam qualquer PR fora dos padrões.
Resumindo: a infraestrutura deve ser, por definição, auditable e reprodutível. Se o seu pipeline não consegue provar que a produção está igual ao código, você não tem uma infraestrutura gerenciada; você tem um legado em nuvem.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
