

Desenvolver aplicações baseadas em Large Language Models (LLMs) no Vertex AI é uma etapa fundamental na modernização de stacks tecnológicas, mas o erro 429 (Too Many Requests) surge frequentemente como um obstáculo crítico. Ele é, essencialmente, um sinal de backpressure: suas requisições superaram a capacidade alocada para o serviço naquele instante.
Para times de engenharia e lideranças de TI, o desafio não é apenas implementar o modelo, mas garantir que a infraestrutura seja resiliente a picos de demanda. A chave reside na compreensão profunda dos modelos de consumo e na adoção de boas práticas de arquitetura. Vamos analisar como elevar o nível de estabilidade operacional dessas implementações.
Escolhendo o modelo de consumo ideal
A estratégia para minimizar erros 429 começa na escolha correta do modelo de consumo, que deve refletir o padrão real de tráfego da sua aplicação, não apenas o volume esperado.
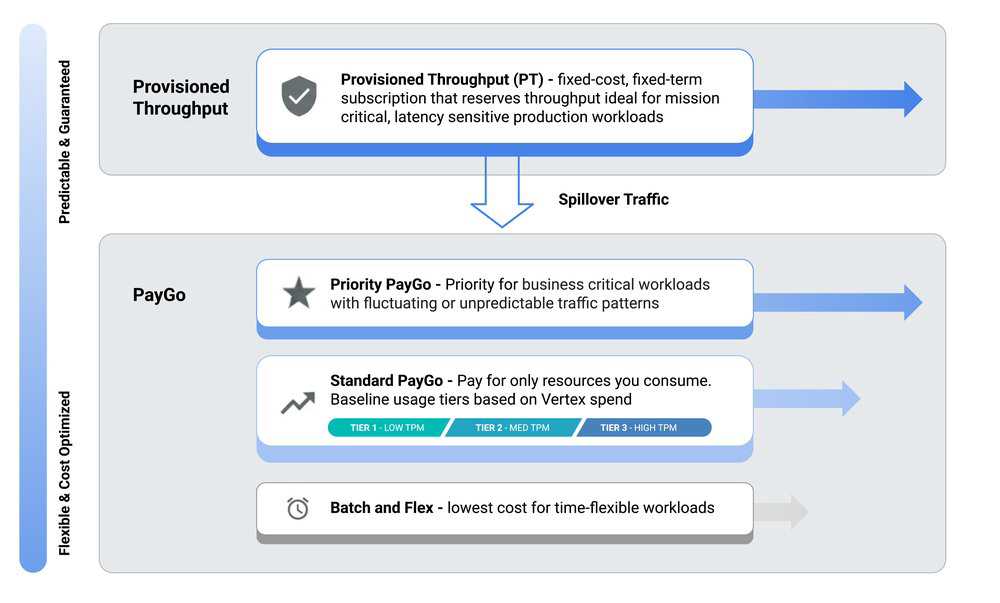
Opções padrão: O Standard Pay-as-you-go (Paygo) é a escolha inicial padrão, utilizando um sistema de Usage Tiers baseado no histórico de consumo da organização. É uma opção dinâmica, mas que compartilha recursos. Para cargas de trabalho críticas e imprevisíveis, o Priority Paygo oferece um mecanismo de priorização via headers, reduzindo a severidade do throttling. Já empresas que operam com alta incidência de tráfego real-time devem considerar o Provisioned Throughput (PT), que isola sua carga do pool compartilhado de Paygo, garantindo uma performance estável e previsível.
Opções voltadas a custo: Para cenários com tolerância maior a latência, o Flex PayGo oferece uma alternativa mais econômica. Já para processamento assíncrono ou análise em batch, o uso do serviço de Batch Prediction é a recomendação técnica correta: ele isola a carga de processamento pesado da sua aplicação principal, gerenciando automaticamente as políticas de retry e escalonamento durante uma janela de 24 horas.
Abordagens híbridas: Aplicações enterprise maduras raramente dependem de um único modelo. O design ideal costuma ser híbrido: PT para fluxos críticos, Paygo para demandas variáveis e Batch para processamento de background.
Cinco estratégias para reduzir erros 429 no Vertex AI
1. Implementação de retries inteligentes: Jamais utilize retries agressivos em erros 429 ou 503. A prática correta é o Exponential Backoff com Jitter. Utilize o SDK do Google Gen AI configurado com HttpResumeOptions ou bibliotecas como Tenacity em Python. Em fluxos agentic, ferramentas como o Reflect and Retry plugin (do ADK) ou padrões de circuit breaking via Apigee são fundamentais para manter a integridade do sistema sob estresse.
2. Roteamento global de modelos: Evitar o travamento em uma única região é vital para a disponibilidade. O uso de endpoints globais do Vertex AI permite que a plataforma distribua requisições entre uma frota de regiões, aproveitando a disponibilidade onde a capacidade está ociosa, diminuindo drasticamente sua exposição aos limites regionais.
3. Otimização de carga via Context Caching: Em aplicações de chat, o volume de tokens repetidos encarece a operação e satura o throughput. O Context Caching permite reutilizar tokens pré-computados, reduzindo o tráfego de rede e a carga no modelo, o que se traduz em menor latência e custo por requisição.
4. Otimização de prompts: Menos tokens, mais performance. Utilize modelos como o Gemini 2.5 Flash-Lite para tarefas de sumarização de histórico antes de enviar o payload principal, aplique o Agent Engine Memory Bank para consolidar fatos e remova redundâncias (JSON schemas desnecessários ou espaços excessivos) das suas chamadas de API.
5. Traffic Shaping: A maior causa de 429s em ambientes produtivos não é o volume médio, mas os picos. Implementar filas de enfileiramento (message queues) ou algoritmos de controle de fluxo na camada de aplicação ajuda a suavizar a carga de entrada, "achatando" os picos antes que eles impactem a API do Vertex AI.
Considerações finais
A estabilidade de aplicações de IA não é apenas um problema de modelo, mas de engenharia de software e infraestrutura. Ao alinhar o modelo de consumo da Google Cloud com padrões resilientes de comunicação, você transforma uma aplicação propensa a erros em um sistema escalável e eficiente.
Artigo originalmente publicado por Pedro MelendezCloud AI Technical Evangelist em Cloud Blog.
