

Confiabilidade em Nível de Cluster: O Novo Paradigma para Modelos de IA em TPUs
O treinamento de modelos de IA de grande escala tornou ineficiente o modelo tradicional de confiabilidade baseado em instâncias individuais. A transição para um modelo de disponibilidade em nível de cluster é essencial para garantir o progresso de jobs de alta performance. Ao focar na saúde agregada de "cubos" de TPUs, as empresas podem otimizar o goodput e prever a estabilidade de treinamento para workloads críticas, tratando o supercomputador como uma entidade única e interconectada.
Modelos de Frontier AI redefiniram o que chamamos de unidade de computação. Quando falamos em trilhões de parâmetros, o treinamento de IA exige milhares de componentes interconectados, orquestrados em deployments de escala industrial para operar como uma única entidade massiva.
Historicamente, a métrica de confiabilidade na nuvem tem focado na instância. Projetado para microservices e escalabilidade horizontal, esse modelo trata a infraestrutura como uma coleção de pequenas unidades independentes. Contudo, essa abordagem é fundamentalmente inadequada para cargas de trabalho de IA de grande escala.
Acreditamos que a confiabilidade precisa migrar de um modelo de instância para um modelo de cluster. Para empresas brasileiras que estão escalando seus centros de excelência em IA, entender essa transição é vital para evitar gargalos de latência e interrupções dispendiosas em pipelines de treinamento.
Confiabilidade para Supercomputadores de IA
Os superpods de TPUs consistem em milhares de chips dispostos em cubos (64 TPUs cada), com links de Inter-Chip Interconnect (ICI) de alta velocidade e uma rede de Optical Circuit Switch (OCS) dinamicamente configurável.
Para o progresso do treinamento, precisamos maximizar o número de cubos totalmente íntegros. Como o desempenho de modelos exige comunicação de alta largura de banda e baixa latência, cada chip e link ICI dentro de um cubo deve estar operacional para que a unidade contribua para o job. A realidade arquitetônica nos força a abandonar a "instância" e adotar a disponibilidade de escala.
Profundidade técnica: A matemática da disponibilidade em escala
Os modelos de confiabilidade tradicionais são frequentemente determinísticos, mas deployments industriais de IA exigem uma abordagem probabilística sobre milhares de componentes. O MTBF (Mean Time Between Failures) de um único chip não reflete a realidade do cluster, onde o MTBF agregado cai drasticamente conforme o número de peças cresce.
Para visualizar como a escala corrói a confiabilidade, podemos aplicar limites simples, como a desigualdade de Markov.
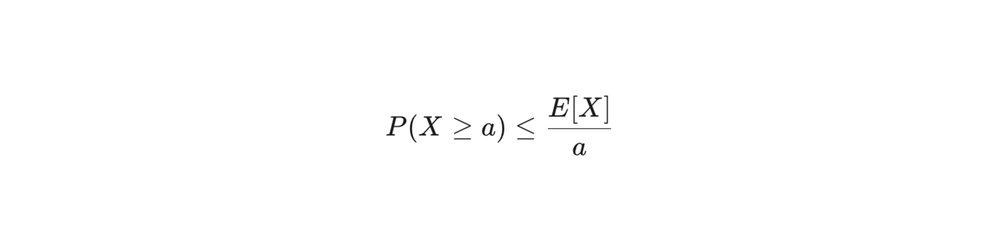
Se definirmos X como o número de cubos com falha, conforme o número esperado de falhas E[X] aumenta, a garantia de um limite estrito de falhas torna-se cada vez mais complexa sem ajustes arquitetônicos sistêmicos.
Modelamos a disponibilidade usando uma distribuição binomial da saúde agregada do cluster. Para um superpod de n cubos, definimos a probabilidade de ter pelo menos k cubos operacionais como a distribuição acumulada de sucesso de n tentativas independentes.
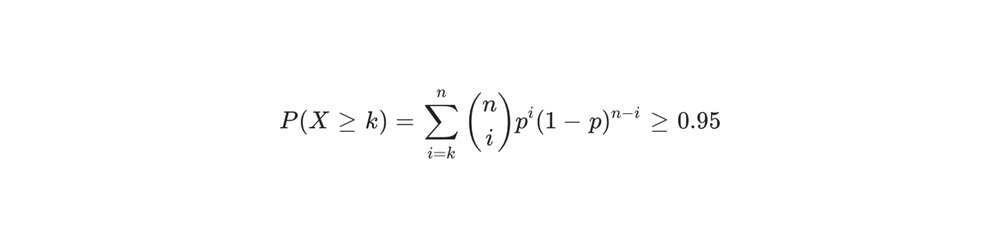
Qual a escala do hardware de IA moderno?
Demonstramos esse modelo com o Ironwood, a sétima geração de TPU do Google, utilizada em modelos como o Gemini. Um superpod Ironwood é um tecido de alta performance que integra 9.216 chips em um domínio de computação único.

Pictured: Part of an Ironwood superpod, directly connecting 9,216 Ironwood TPUs in a single domain.
Usando esse modelo, determinamos que a disponibilidade topológica para um superpod Ironwood é de 130 de 144 cubos disponíveis por 95% do mês. Isso traduz-se em um bloco de computação massivo de 8.320 chips totalmente operacionais, otimizando o que chamamos de "hero jobs" (treinamentos críticos).
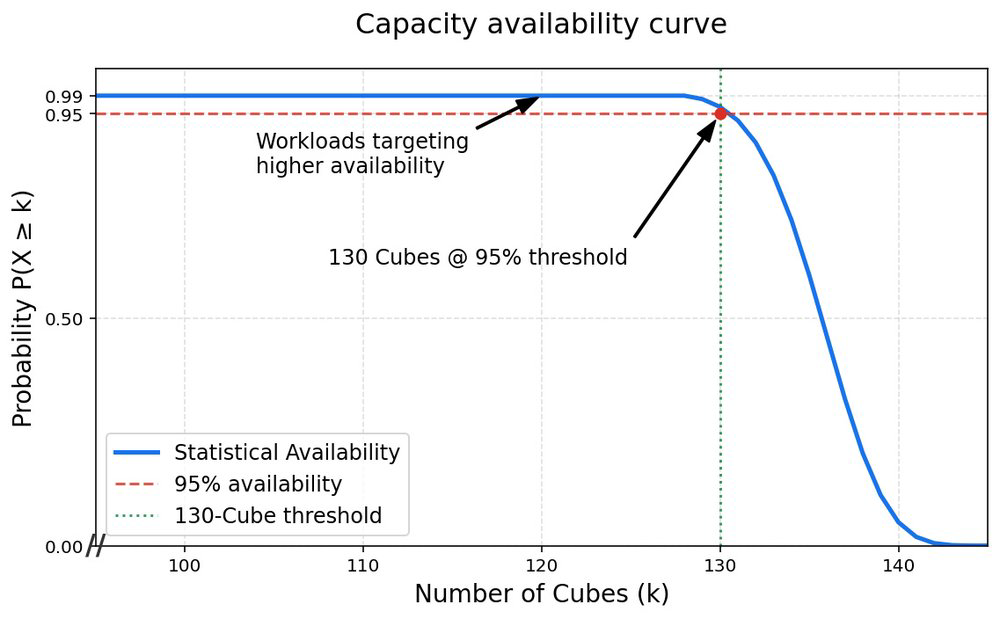
Capacity availability curve for an Ironwood superpod (144 cubes)
Como otimizar a produtividade de ML?
O goodput é a métrica principal de produtividade de ML. Nosso novo padrão de confiabilidade fornece a base determinística para maximizar essa métrica através de três camadas:
- Infraestrutura: Os superpods garantem que a escala necessária esteja fisicamente conectada.
- Frameworks: JAX e Pathways oferecem resiliência, realizando hot-swapping de nós com falha sem reinícios completos.
- Aplicação: Mecanismos como auto-checkpointing e multi-tier checkpointing reduzem a perda de progresso em caso de falhas inevitáveis.
O modelo de confiabilidade em nível de cluster marca uma nova era onde supercomputadores de IA devem ser engines de inovação previsíveis. Para empresas brasileiras, a lição é clara: não basta ter o hardware, é preciso arquitetar a resiliência para o nível de escala onde o seu modelo realmente habita.
Perguntas Frequentes
-
Por que o modelo de confiabilidade por instância é inadequado para IA de larga escala?
Modelos tradicionais tratam infraestrutura como unidades independentes, o que falha ao lidar com a interdependência crítica de milhares de chips em um superpod, onde a performance depende da comunicação de ultra-baixa latência e alta largura de banda entre todos os componentes. -
O que é o conceito de "disponibilidade de escala" proposto?
É uma mudança de perspectiva onde, em vez de garantir uptime para cada chip individual, prioriza-se a disponibilidade de blocos funcionais (cubos) necessários para o treinamento contínuo, utilizando modelos probabilísticos para prever a saúde do cluster. -
Como equilibrar a necessidade de um supercluster estável com o uso de recursos para outros experimentos?
O framework permite segregar fatias do superpod. Enquanto um grupo de cubos garante o treinamento de "hero jobs" com alta confiabilidade estatística, os recursos restantes podem ser alocados para workloads menos críticos, como inferência ou desenvolvimento/testes, maximizando o ROI da infraestrutura.
Artigo originalmente publicado por Mohan Pichika, Group Product Manager em Cloud Blog.
