

Cloud Storage Rapid: O Fim dos Gargalos de I/O em Cargas de AI e Analytics
Este artigo analisa o lançamento do Cloud Storage Rapid, uma solução do Google Cloud desenhada para remover gargalos de I/O em workloads críticos de AI/ML e analytics. Através do Rapid Bucket e do Rapid Cache, a tecnologia oferece alta performance, baixa latência e escalabilidade massiva, permitindo que GPUs e TPUs operem sob demanda sem interrupções por lentidão na leitura ou escrita de dados. A conclusão é que o armazenamento finalmente evoluiu para acompanhar a escala da era Generative AI.
No Google Cloud Next ’26, foi anunciado o Cloud Storage Rapid, uma família de capacidades para o armazenamento de objetos voltada para workloads altamente exigentes em I/O. Esta atualização não é incremental; é uma resposta estratégica à mudança geracional que organizações brasileiras enfrentam ao treinar modelos com trilhões de parâmetros ou atuar com inference em escala global.
Para times de engenharia, o problema é conhecido: a atenção recai sobre GPUs e TPUs, mas o gargalo real costuma residir no storage. Quando o cluster fica ocioso esperando um checkpoint ou a leitura de datasets, o custo de oportunidade é altíssimo. Até então, a escolha era binária: ou a performance extrema de sistemas zonais ou a conveniência e durabilidade do object storage tradicional. O Cloud Storage Rapid tenta romper esse compromisso.

O que muda na prática com o Rapid Bucket?
O Rapid Bucket (GA) utiliza o Colossus — o sistema de armazenamento distribuído que sustenta o Gemini e o YouTube — para oferecer uma performance que lembra sistemas de arquivos paralelos, mas com a semântica de object storage.
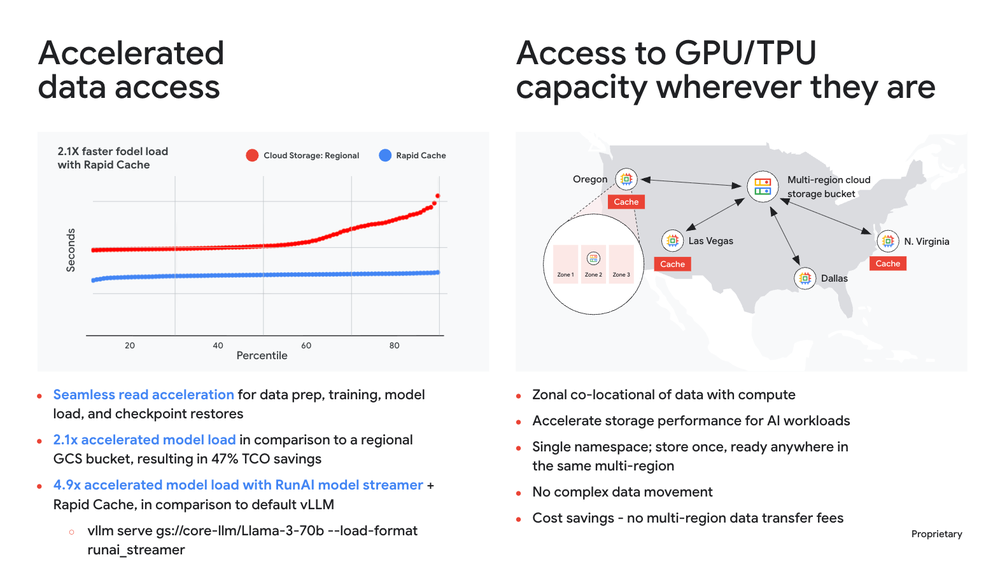
Para o mercado brasileiro, que muitas vezes lida com restrições de latência em operações distribuídas, os números são relevantes: até 20 milhões de QPS e 15+ TB/s de throughput por bucket zonal. Mais importante que o hardware é a semântica: suporte a native appends e leitura simultânea à escrita, o que permite otimizar o checkpointing em até 5x.
Otimização sem refatoração: o papel do Rapid Cache
O Rapid Cache é, provavelmente, a ferramenta mais consultiva desta linha. Ele permite acelerar cargas existentes sem alterações de código. Para equipes de engenharia que não podem se dar ao luxo de reescrever pipelines de dados para cada nova otimização, o cache provê read throughput de 2.5 TB/s.
O novo recurso de ingest on write resolve um problema clássico de cold start. Historicamente, o primeiro acesso a um dado era lento. Agora, ao escrever no bucket, o dado é prontamente enviado ao cache, garantindo que o primeiro acesso (como em restauração de checkpoints) já ocorra em altíssima performance.
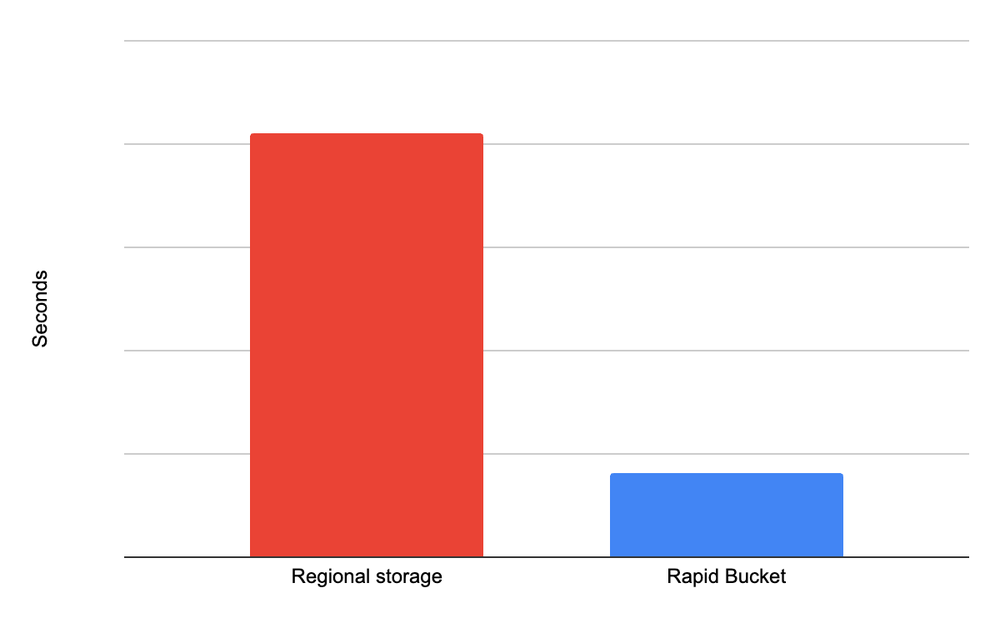
5x mais rápido em restauração de checkpoints com o Rapid Bucket.
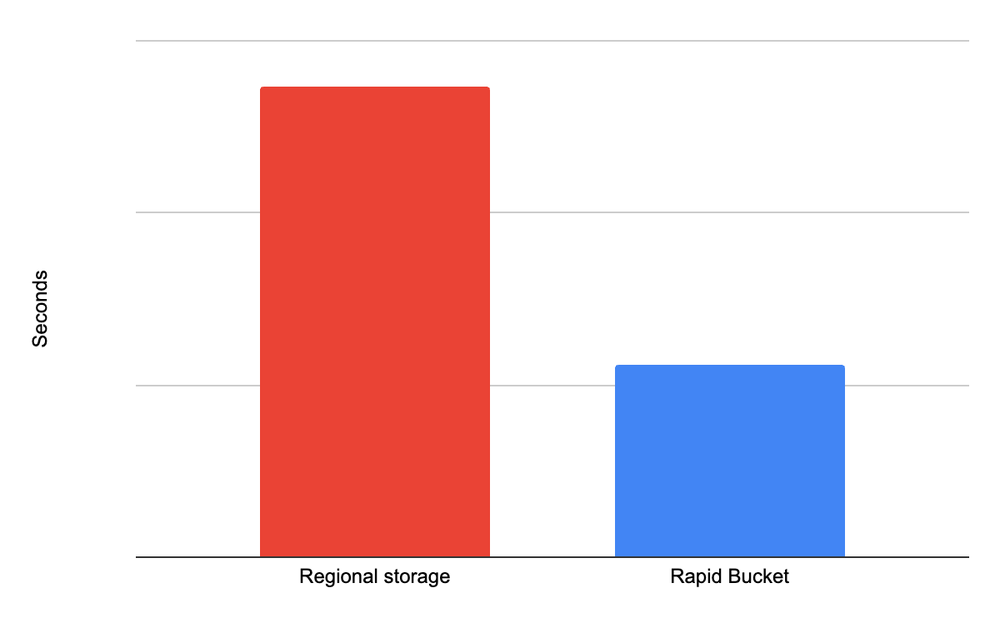
3.2x mais rápido na escrita de checkpoints.
Análise estratégica: O caso da Thinking Machines Lab
O caso da Thinking Machines Lab ilustra um cenário comum em escala: um hub-and-spoke de dados onde a ingestão ocorre em uma zona e a computação em outra. A combinação de multi-region buckets com o Rapid Cache permitiu que a empresa eliminasse o overhead de movimentação manual de dados e, crucialmente, superasse os erros 429 que interrompiam seus ciclos de treinamento Spark.
Para gestores no Brasil, a mensagem aqui é sobre estabilidade operacional. A capacidade de escalar QPS conforme o ambiente aquece, sem que o storage se torne um ponto único de falha, é o que permite passar de um projeto experimental de IA para um ambiente de produção robusto e resiliente.
Escolhendo sua infraestrutura de dados
A decisão entre Rapid Bucket e Rapid Cache deve ser pautada pelo caso de uso:
- Rapid Bucket: Indicado para cenários onde a performance de escrita/leitura é o diferencial competitivo (treinamento intenso, analytics de alta complexidade).
- Rapid Cache: A escolha pragmática para quem já roda no Cloud Storage e precisa de um ganho de performance em leitura imediatos, sem o custo de um refactoring.
Artigo originalmente publicado por Luigi Pontes, Senior Product Manager em Cloud Blog.
