

A ideia de um carro com o qual você pode conversar é um desejo antigo, partindo de visões da cultura pop até as integrações modernas de smartphones. No entanto, para empresas que operam com tecnologia de ponta, o desafio não é apenas fazer o carro 'falar', mas torná-lo inteligente de forma resiliente e performática.
Uma das formas de alcançar comandos de voz mais naturais é incorporar foundation models de IA aos sistemas do veículo. Diferente dos comandos tradicionais baseados em palavras-chave rígidas, esses modelos conectam perguntas do cotidiano a funções do carro em um diálogo fluido. O benefício prático é claro: o motorista mantém o foco na estrada enquanto interage de forma intuitiva.
Contudo, para o cenário automotivo — e para muitas aplicações de edge computing no mercado brasileiro — os Large Language Models (LLMs) possuem um gargalo crítico: a dependência de conectividade constante. A latência de rede e as zonas de sombra de sinal tornam os LLMs impraticáveis para funções críticas dentro do cockpit.
Para resolver isso, o BMW Group e o Google Cloud desenvolveram uma prova de conceito (PoC) focada em Small Language Models (SLMs). O objetivo foi criar uma solução eficiente e reprodutível para automatizar os workflows de fine-tuning, otimização, avaliação e deployment de modelos especializados para domínios específicos.
Small Language Models: Conceito enxuto, potencial escalável
A IA generativa permite que montadoras processem comandos complexos como: “Encontre um restaurante vegetariano na minha rota que esteja aberto agora e tenha avaliação superior a quatro estrelas”. Um sistema tradicional falharia aqui; a GenAI, com sua capacidade de raciocínio, consegue decompor e executar a solicitação.
O desafio de engenharia surge ao integrar essa inteligência: LLMs na nuvem dependem de estabilidade de rede, enquanto LLMs rodando localmente (onboard) esbarram nas limitações de hardware de processamento dos veículos.
Os SLMs oferecem o equilíbrio ideal. Esses modelos, dimensionados corretamente, podem ser executados diretamente em dispositivos edge. No modelo de arquitetura híbrida adotado, o SLM resolve as funções mais frequentes localmente e escala requisições altamente complexas para um LLM na nuvem apenas quando necessário. Para isso, o SLM precisa ser pequeno o suficiente para o hardware, mas capaz o bastante para ser útil, o que exige um fine-tuning rigoroso.
Desafios de integração: Hardware e Performance
Sistemas de infotainment automotivos possuem restrições severas de armazenamento e compute. Um modelo como o Gemma 3 27B pode consumir mais de 40 GB de memória em precisão de 16-bit, o que é inviável. Versões menores, como o Gemma 3 270M, existem, mas podem perder precisão em tarefas generalistas.
Portanto, a compressão de modelos e o tuning são obrigatórios. O foco aqui é encontrar o maior throughput e menor latência sem sacrificar a acurácia para as tarefas de domínio.
Convertendo LLMs em SLMs: O Arsenal Técnico
Para transformar modelos pesados em SLMs eficientes, a BMW explorou técnicas consolidadas de compressão e refinamento:
Técnicas de Compressão:
- Quantization: Redução do consumo de memória convertendo parâmetros de alta precisão (ex: 32-bit floats) para formatos menores (ex: 8-bit integers ou 4-bit floats), com perda mínima de acurácia.
- Pruning: Identificação e remoção de parâmetros ou conexões menos importantes na rede neural.
- Knowledge Distillation: Treinamento de um modelo "estudante" compacto para replicar o comportamento de um LLM "professor" maior.
Refinamento de Qualidade Pós-Compressão:
- Fine-tuning (e LoRA): O uso de Low-Rank Adaptation (LoRA) permite adaptar o modelo ao domínio automotivo congelando os pesos originais e treinando matrizes menores, o que reduz drasticamente o custo de processamento.
- Reinforcement Learning (RL): Métodos como DPO (Direct Policy Optimization) e GRPO são usados para alinhar as respostas do modelo às preferências humanas, garantindo utilidade e segurança.
Avaliação e a busca pela configuração ótima
A jornada de um LLM generalista para um SLM especializado não é linear. Cada escolha de quantization ou dataset impacta a eficiência final. Além disso, nem toda técnica é compatível com todos os modelos (modelos via API como o Google Gemini possuem métodos de fine-tuning específicos).
Para evitar um processo manual exaustivo, a solução foi construir workflows automatizados através de pipelines executáveis.
A Solução: Workflow Automatizado com Vertex AI Pipelines
A arquitetura utiliza o Vertex AI Pipelines para orquestrar de forma modular cada etapa do ciclo de vida do SLM. Isso permite testar centenas de combinações de modelos base, técnicas de compressão e métodos de tuning de forma sistemática.
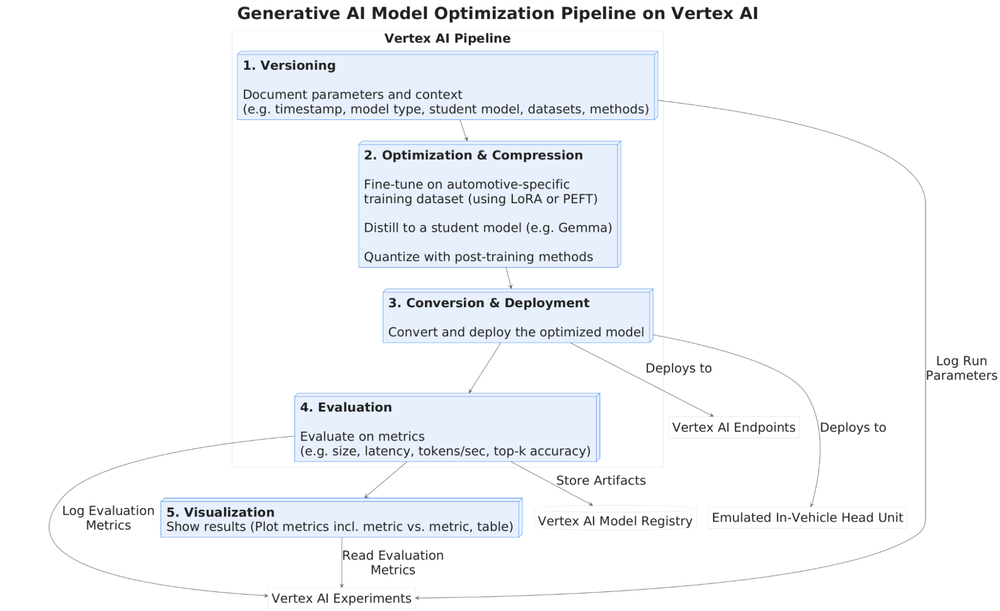
Figura 1: Visão geral de alto nível das etapas do pipeline automatizado e sua interação com data stores e model stores.
Etapas do Pipeline:
- Versioning e Configuração: Tudo é registrado no Vertex AI Experiments para garantir rastreabilidade e reprodutibilidade total.
- Otimização e Compressão: O pipeline gerencia a matriz de compatibilidade entre modelos e métodos (ex: garantindo que o LoRA seja aplicado apenas a arquiteturas suportadas).
- Testes de Deployment: O SLM é implantado em um ambiente que emula o hardware real (como instâncias de compute rodando Android Open Source Project - AOSP).
- Avaliação: Medição de métricas de hardware (consumo de memória e latência) e qualidade de resposta através de Auto-raters (LLM-as-a-judge) e métricas como ROUGE e BLEU.
- Análise: Comparação visual de experimentos via TensorBoard e Looker para identificar o melhor candidato para produção.
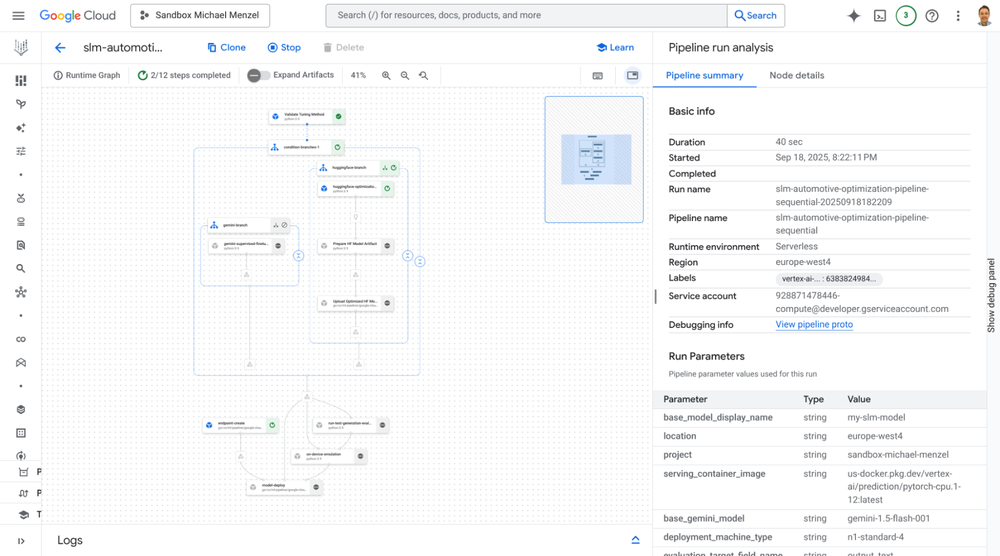
Figura 2: O pipeline automatizado visualizado na interface do Vertex AI Pipeline.
Conclusão e Próximos Passos
A abordagem da BMW demonstra que a eficiência operacional em IA não vem apenas de modelos maiores, mas de pipelines de engenharia robustos. Ao rodar o sistema de infotainment nativamente em instâncias de cloud (conceito de "Head unit in the cloud"), a empresa consegue escalar testes de SLMs sem depender de hardware físico limitado em estágios iniciais.
Para empresas brasileiras, essa estratégia é uma lição valiosa sobre como levar IA para o edge ou para aplicações com conectividade instável, mantendo a escalabilidade e o controle de custos (FinOps).
O BMW Group disponibilizou a solução dessa PoC no GitHub.
Artigo originalmente publicado por Dr. Jens KohlBMW Group em Cloud Blog.
