

Visão Geral
O Azure Monitor pipeline ampliou suas capacidades de coleta, indo além da integração básica ao oferecer suporte robusto para ambientes edge e multi-cloud. A grande novidade, agora em public preview, é a capacidade de realizar transformações de telemetria antes da ingestão efetiva no Log Analytics Workspace. Para empresas brasileiras que lidam com volumes massivos de logs e precisam controlar a conta de consumo de nuvem, esta é uma evolução estratégica de FinOps.
Esta funcionalidade suporta a coleta em grande escala (acima de 100k EPS) e garante que, mesmo sob condições de conectividade intermitente, os dados sejam armazenados localmente e sincronizados posteriormente, mantendo a integridade necessária para auditorias e troubleshooting.
Por que as transformações importam
Em um cenário de otimização financeira, o volume de ingestão é o principal driver de custos de observabilidade. As transformações endereçam três pilares críticos:
- Redução de Custos: Ao filtrar e agregar dados na origem ou no pipeline antes da ingestão, você paga apenas pelo que é realmente valioso para o seu negócio.
- Melhoria em Analytics: Schemas padronizados resultam em queries KQL muito mais rápidas e dashboards que não sofrem com inconsistências de dados.
- Future-Proof: A validação de schema integrada no deployment evita que alterações inesperadas nos logs quebrem seus pipelines de dados ou dashboards críticos.
O objetivo é claro: garantir que apenas dados limpos, estruturados e otimizados cheguem ao armazenamento, reduzindo a necessidade de reprocessamento e o custo por TB.
Principais funcionalidades em Public Preview
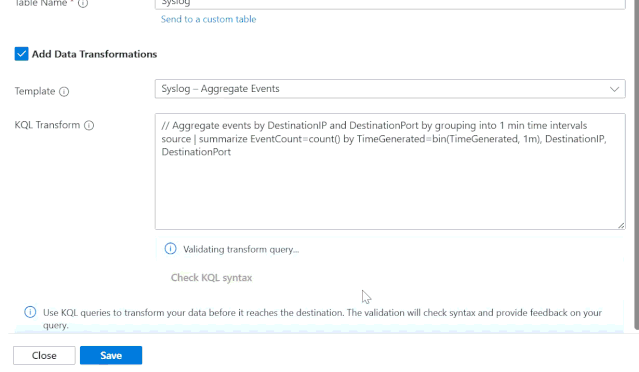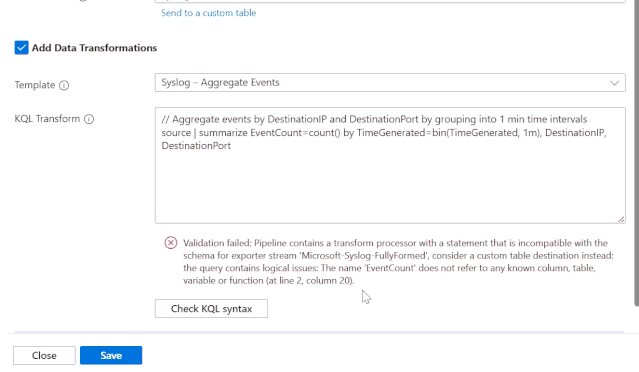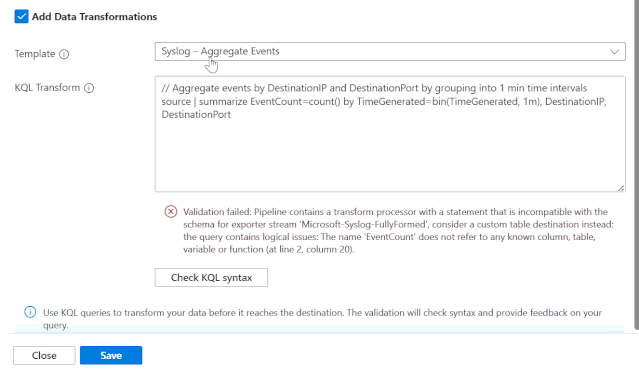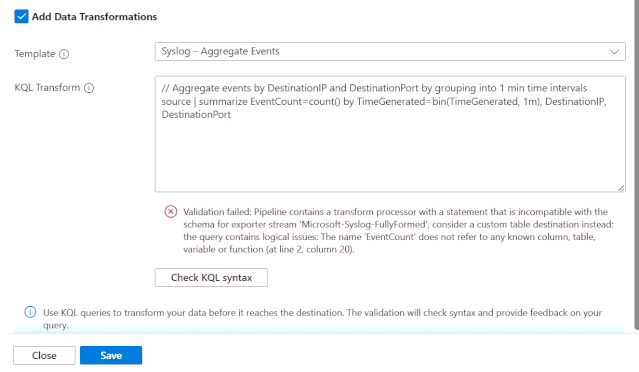
1. Detecção de mudanças no schema
Agora existe validação de schema integrada para syslog e CEF diretamente no Strato UI. Ao usar o botão "Check KQL Syntax", o sistema identifica se a sua transformação criará um conflito com as tabelas padrão. Caso ocorra um erro, você recebe uma orientação clara: remover a transformação ou rotear os dados para uma custom table.
2. Templates KQL e Padronização Automática
Para agilizar, a Microsoft disponibilizou templates de KQL prontos para uso. Além disso, a schematização automática de CEF e syslog simplifica a adaptação de dados brutos sem a necessidade de scripts de conversão complexos.
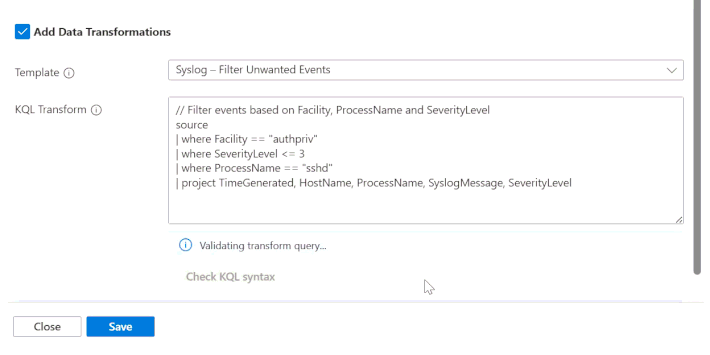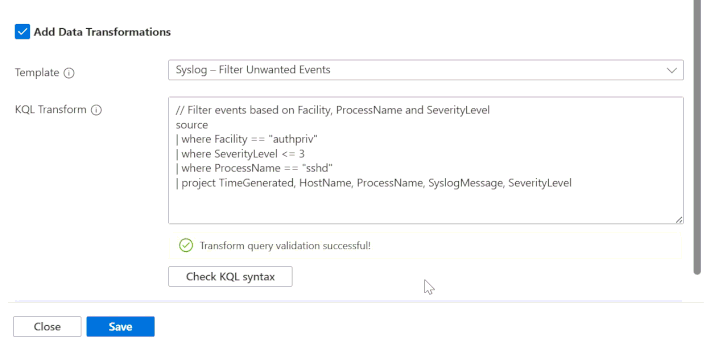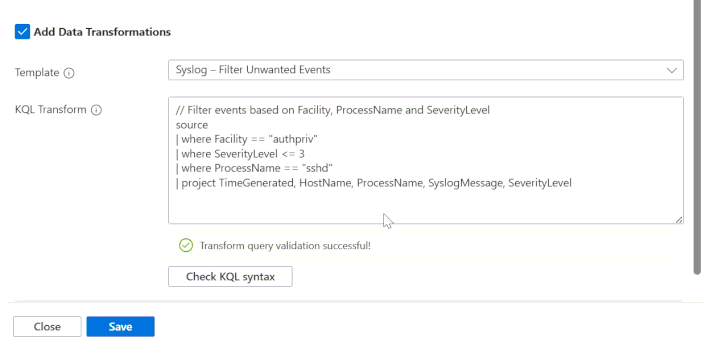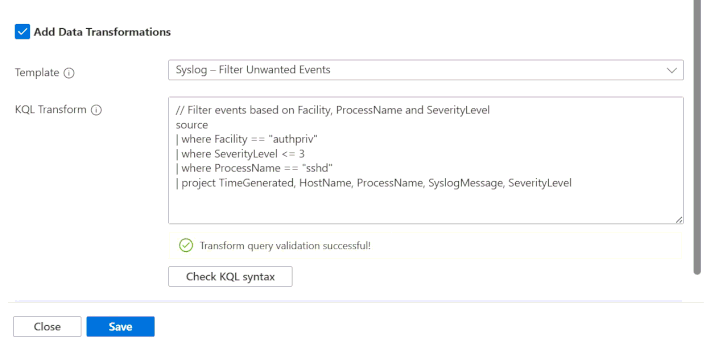
3. Filtragem Avançada e Agregação
Reduza o ruído eliminando eventos desnecessários com base em atributos como SeverityLevel ou ProcessName. Para logs de alto volume, a função summarize permite agregar eventos em intervalos (ex: 1 minuto), transformando logs de alta frequência em insights acionáveis de forma compacta e barata.
Funções KQL Suportadas
O pipeline suporta um subconjunto robusto de funções KQL para processamento:
- Agregação:
summarize(comby),sum,max,min,avg,count,bin. - Filtragem:
where,contains,has,in,and,or, operadores de igualdade e comparação. - Schematização:
extend,project,project-away,project-rename,iif,case,coalesce,parse_json.
Conclusão e Próximos Passos
Para times de Engenharia e SREs focados em cost-efficiency, testar este pipeline é um passo essencial. Recomendamos começar pela análise de seus logs mais volumosos e que geram pouco valor analítico, aplicando filtros diretamente no Azure Portal.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
