

TL;DR: Copilotos na Observabilidade
A introdução do Azure Copilot Observability Agent marca um movimento estratégico da Microsoft para automatizar o ciclo de vida de observabilidade em ambientes AKS e VMs. O foco é reduzir o 'toil' humano ao utilizar LLMs para correlacionar volumes massivos de métricas, logs e traces. A conclusão é que o agente não substitui a expertise, mas atua como um copiloto para correlacionar anomalias, acelerando o diagnóstico e permitindo que times de engenharia foquem em correção, não em exploração de dados.
O desafio do volume e a resposta via IA
A observabilidade moderna tornou-se um labirinto de metrics, logs, traces, alerts e sinais de plataforma. Para a maioria das empresas brasileiras que operam infraestruturas complexas, o grande gargalo não é a coleta de dados, mas a capacidade humana de interpretar esses sinais sob pressão, especialmente quando o downtime afeta o negócio diretamente.
A Microsoft está tentando endereçar isso com seu novo Observability Agent. O objetivo é claro: transformar o processo de investigação reativa em uma jornada conduzida por raciocínio assistido por modelos de linguagem (LLMs).
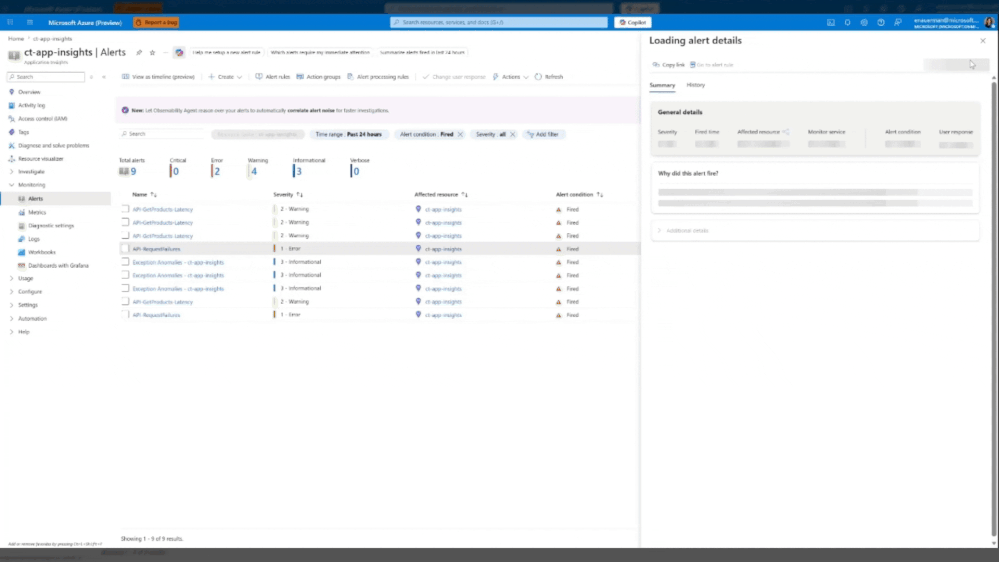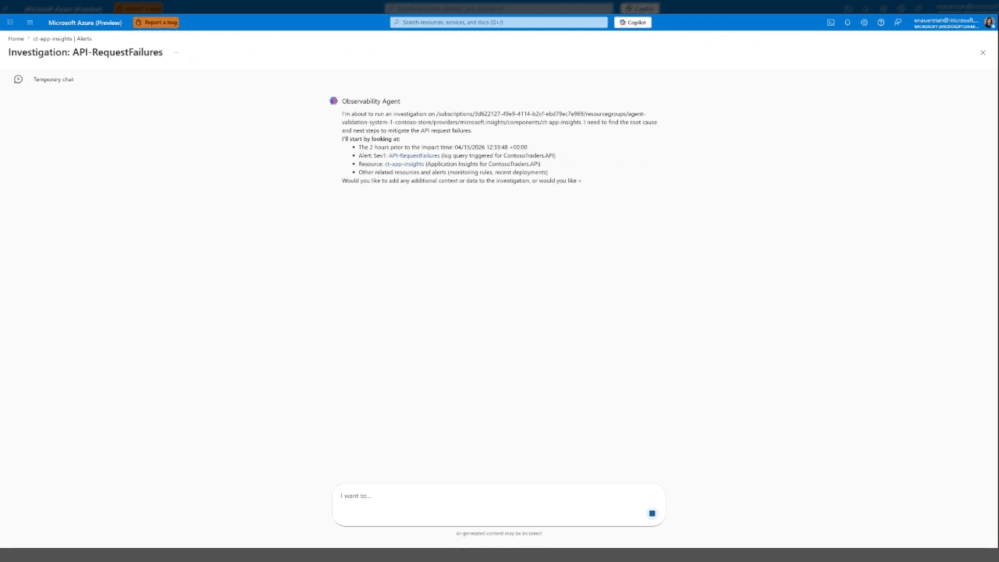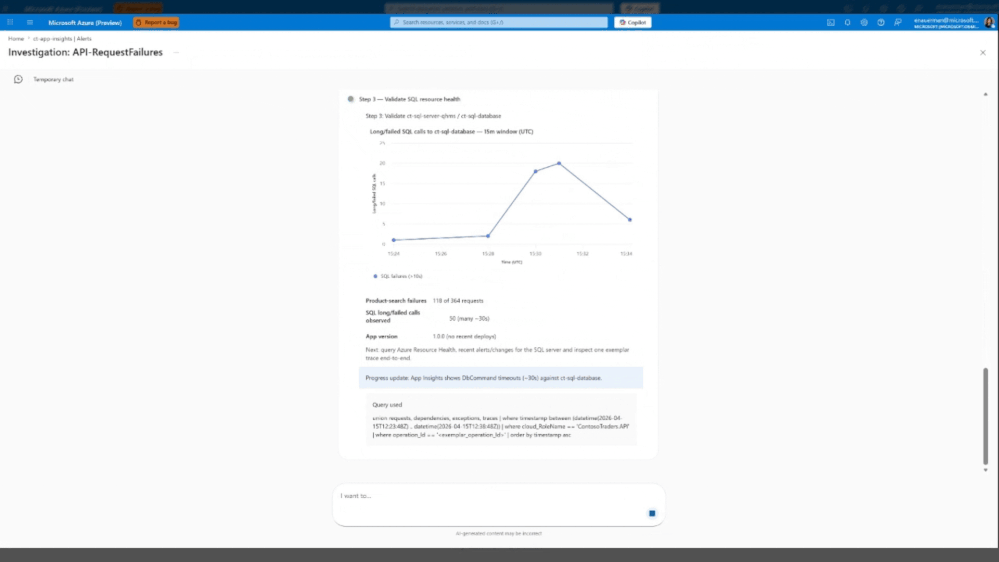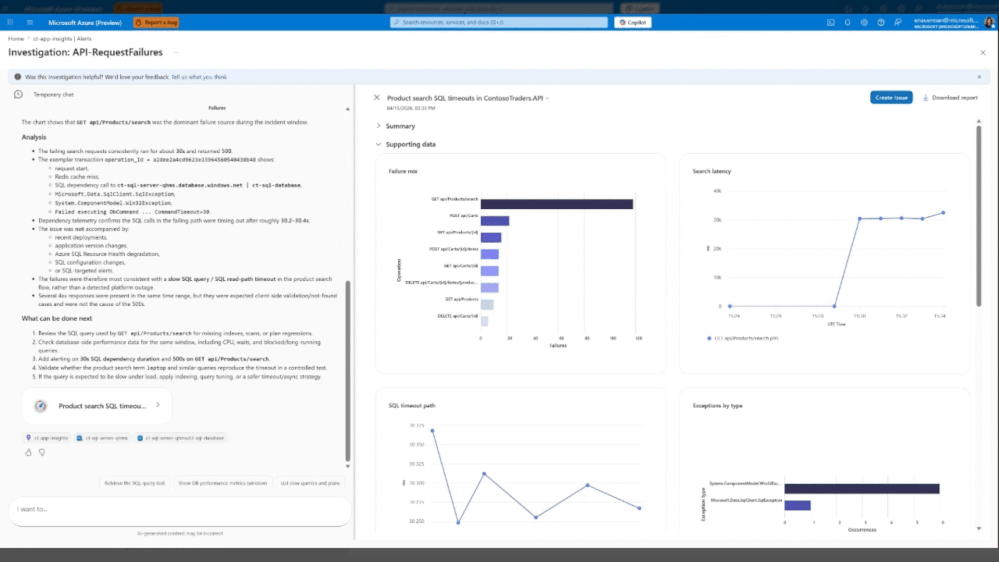
Investigação profunda: O papel do Agente
Quando ocorre um incidente, o tempo é o recurso mais valioso. O agente é projetado para atuar em cenários críticos em distributed systems, como clusters de Azure Kubernetes Service (AKS) e Virtual Machines (VMs). A capacidade de correlacionar anomalias em camadas isoladas (infraestrutura x aplicação) é o que promete reduzir o mean time to repair (MTTR).
Os pontos de atenção que o agente promete cobrir incluem:
- Application issues: Regressão de performance e falhas de dependência.
- Infrastructure issues: Saturação de recursos, disk I/O throttling e falhas de rede.
- Platform incidents: Problemas gerenciados, como exaustão de portas SNAT.
Explorando dados além dos alertas
Além da resposta a incidentes, a ferramenta oferece uma interface de natural language query para o dia a dia. A ideia é permitir que o engenheiro, sem precisar compor queries KQL complexas de imediato, pergunte ao sistema coisas como: "Existe correlação entre erros de dependência e falhas na minha aplicação?" ou "Qual a causa dos picos de latência nos últimos 3 dias?".
Isso é, na prática, uma democratização da análise de dados para perfis que, idealmente, deveriam focar em arquitetura e deployment, não em ser especialistas em linguagens de busca do Azure Monitor.
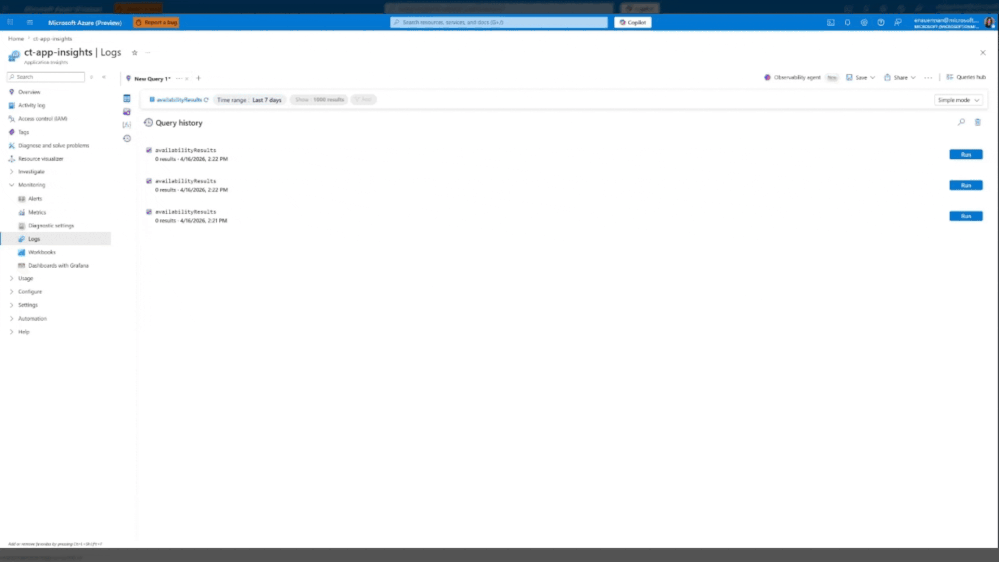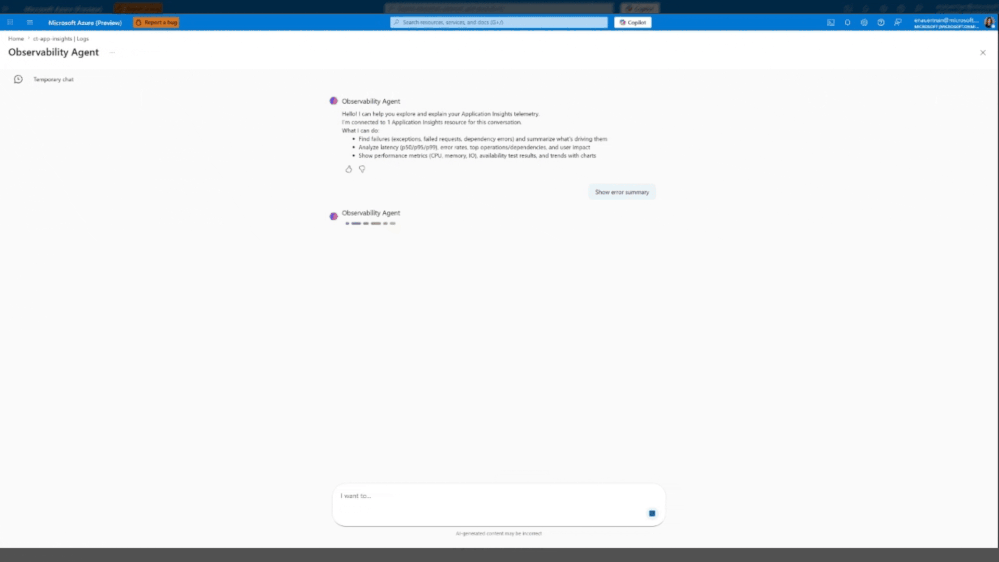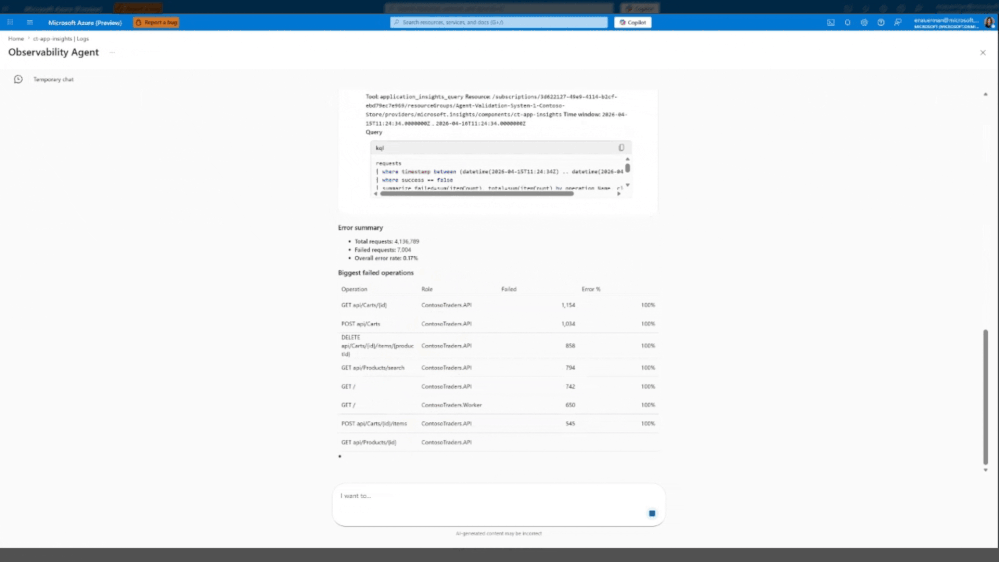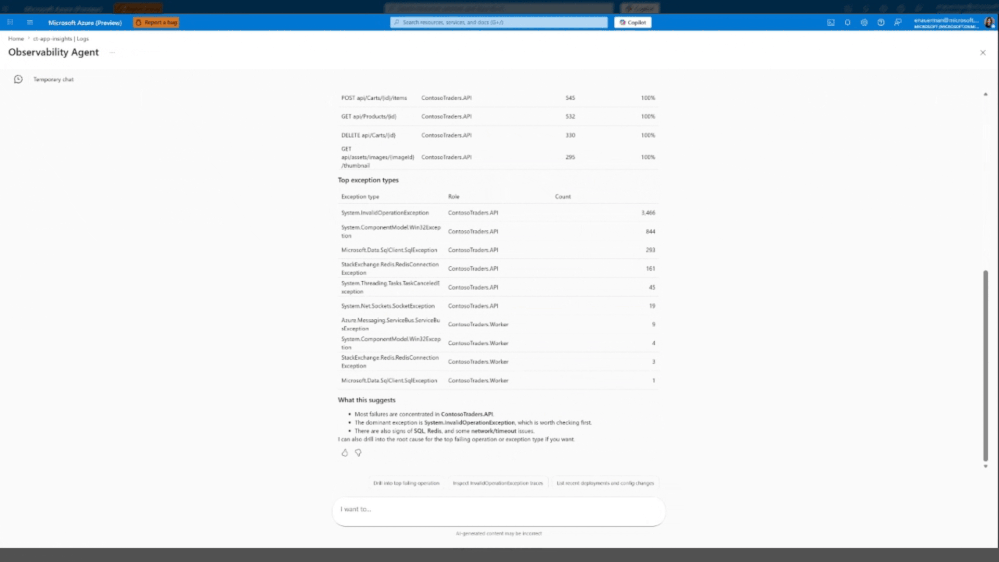
O futuro: O caminho da observabilidade autônoma
O roteiro de evolução aponta para uma redução drástica da intervenção manual: autonomous observability. Significa que, em um futuro próximo, o agente não apenas sugerirá, mas tomará a iniciativa de correr triagens, correlacionar alertas e abrir Azure Monitor Issues automaticamente.
Para o gestor de TI no Brasil, a mensagem é: a maturidade da observabilidade não será mais medida por quantos dashboards você mantém, mas por quão autônoma sua infraestrutura é capaz de se diagnosticar diante de uma falha.
Perguntas Frequentes
-
O Azure Copilot substitui a necessidade de engenheiros na análise de logs?
Não. Ele atua como uma ferramenta para acelerar a correlação e interpretação de grandes volumes de dados (logs, métricas, traces), permitindo que os engenheiros foquem na resolução de problemas complexos em vez de perderem tempo minerando dados manualmente. -
Quais ambientes o agente de observabilidade suporta atualmente?
O agente está otimizado para ambientes full-stack em sistemas distribuídos, com suporte robusto para Azure Kubernetes Service (AKS) e Máquinas Virtuais (VMs). -
Como o agente lida com a correlação de dados em um incidente?
Ele utiliza uma combinação de Machine Learning (ML) e Large Language Models (LLM) para analisar sinais em diversas camadas — infraestrutura, aplicação e plataforma — identificando pontos de correlação entre anomalias e sugerindo possíveis causas raízes.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
