

A Microsoft anunciou recentemente o Public Preview do Automatic zone balance para Azure Virtual Machine Scale Sets. Para times de infraestrutura e engenharia que operam sistemas críticos na nuvem, essa é uma adição estratégica que toca em um ponto nevrálgico da operação: a deriva causada pela imprevisibilidade da alocação de capacidade em ambientes multi-zona.
O Desafio da Distribuição Zonal
Ao desenhar uma arquitetura resiliente no Azure, a estratégia de distribuir instâncias por múltiplas Availability Zones é mandatória. Teoricamente, o Azure garante a distribuição balanceada, mas, na prática, a realidade é mais complexa. Fatores como restrições globais de capacidade e scaling operations frequentes levam a um desbalanceamento inevitável ao longo do tempo. Uma zona pode acabar com uma densidade maior de instâncias que as demais.
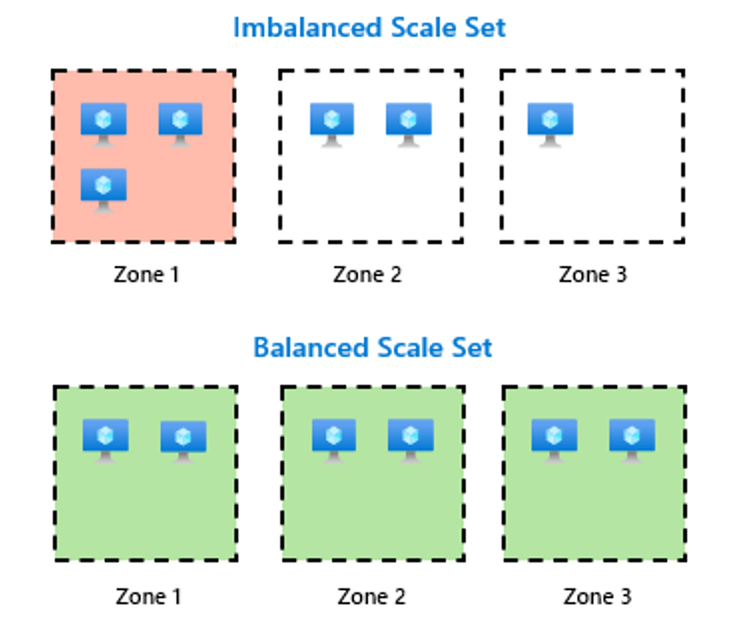
Figura 1: Sem o devido rebalanceamento, o raio de explosão (blast radius) de uma falha zonal torna-se imprevisível, podendo derrubar uma fatia muito maior da sua carga de trabalho do que o esperado em um cenário de distribuição ideal de 1/3 (33%) por zona.
Análise Estratégica: O que muda para sua operação?
O Automatic zone balance altera a forma como lidamos com a resiliência de um scale set. O ponto mais positivo aqui é a adoção de um modelo create-before-delete. O sistema monitora ativamente as zonas com under-provisioning, cria novas VMs e apenas após a verificação de healthy status via Application Health Extension ou Load Balancer Health Probes é que ele remove as instâncias excedentes da zona superpopulada.
Isso elimina o risco de downtime operacional durante o rebalanceamento. Para empresas brasileiras, que muitas vezes operam com cronogramas de manutenção restritos e precisam maximizar a disponibilidade sob estritos SLAs, essa funcionalidade reduz significativamente a necessidade de intervenção humana e scripts personalizados para conformidade, que antes eram necessários para mitigar o zonal drift.
Pontos de Atenção para Engenharia
Embora promissor, este recurso não deve ser ativado sem governança. Alguns pontos que seu time deve considerar:
- Safety Guardrails: O recurso respeita políticas de proteção de instâncias e pausa durante processos ativos de scale. Isso é positivo para evitar thrash e instabilidade, mas deve ser monitorado via observability para garantir que a taxa de rotatividade das instâncias não impacte custos com instâncias spot ou ciclos de início de aplicação (cold start).
- Pré-requisitos: O scale set precisa estar em modo best-effort zone balancing. Certifique-se de que sua infraestrutura atual segue esse padrão. A ativação é simples via feature flag (o
AutomaticZoneRebalancing), mas exige uma validação rigorosa de health checks. - Integração com Instance Repairs: Ao habilitar o balanceamento, você ganha automaticamente o automatic instance repairs. Isso é uma excelente combinação para fechar o ciclo de automação de saúde, mas exige que sua aplicação seja capaz de lidar com a substituição de instâncias sem perdas de estado crítico (ex: persistência de dados em volumes gerenciados ou delegação de estado para camadas de storage externas).
Para times que buscam maturidade operacional, a transição para este modelo é um passo direto rumo à redução do operational overhead e ao aumento da resiliência em nível de infraestrutura de nuvem, alinhando a arquitetura técnica com as exigências de disponibilidade do negócio.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
