

No desenvolvimento de aplicações que exigem processamento de voz em tempo real — como centrais de atendimento, legendagem ao vivo e agentes de voz de baixa latência — a engenharia sempre enfrentou um trade-off clássico: speed versus accuracy.
Historicamente, para obter transcrições altamente precisas, era necessário processar o áudio offline ou aceitar uma latência inaceitável. Para manter a experiência de usuário fluida, muitos sistemas recorriam a modelos mais rápidos, porém com menor capacidade contextual. A Microsoft, com o lançamento em public preview do Post-Stream Refinement no Azure AI Speech (parte da plataforma Azure AI Foundry), propõe uma mudança estrutural nessa equação.
O desafio: Por que a precisão em tempo real é um gargalo?
A natureza do streaming impõe limitações físicas aos modelos de speech-to-text (STT). Em um cenário de baixa latência, o motor de reconhecimento precisa gerar hipóteses sobre a fala praticamente no instante em que o áudio é capturado, sem conhecer todo o contexto da sentença. Isso gera problemas operacionais conhecidos pelos times de engenharia:
- Nomes próprios e vocabulário técnico: Sem o contexto completo da frase, termos específicos de domínio ou marcas são alvo frequente de erros de inferência.
- Code-switching e multilinguismo: A transição fluida entre idiomas durante a fala é um dos desafios mais complexos para modelos otimizados apenas para velocidade.
- Dependências de longo alcance: O significado de uma palavra pode ser alterado por algo dito segundos depois, mas o modelo não pode esperar.
- Pontuação e formatação: A estruturação natural de um texto (capitalização, pontuação) exige uma visão holística da fala, que o processamento stream puro não consegue suprir inicialmente.
Para empresas que dependem de transcrição para compliance, análise de sentimentos ou indexação, a baixa qualidade técnica resultante dessas limitações compromete a eficiência dos downstream workflows.
A Solução: Post-Stream Refinement
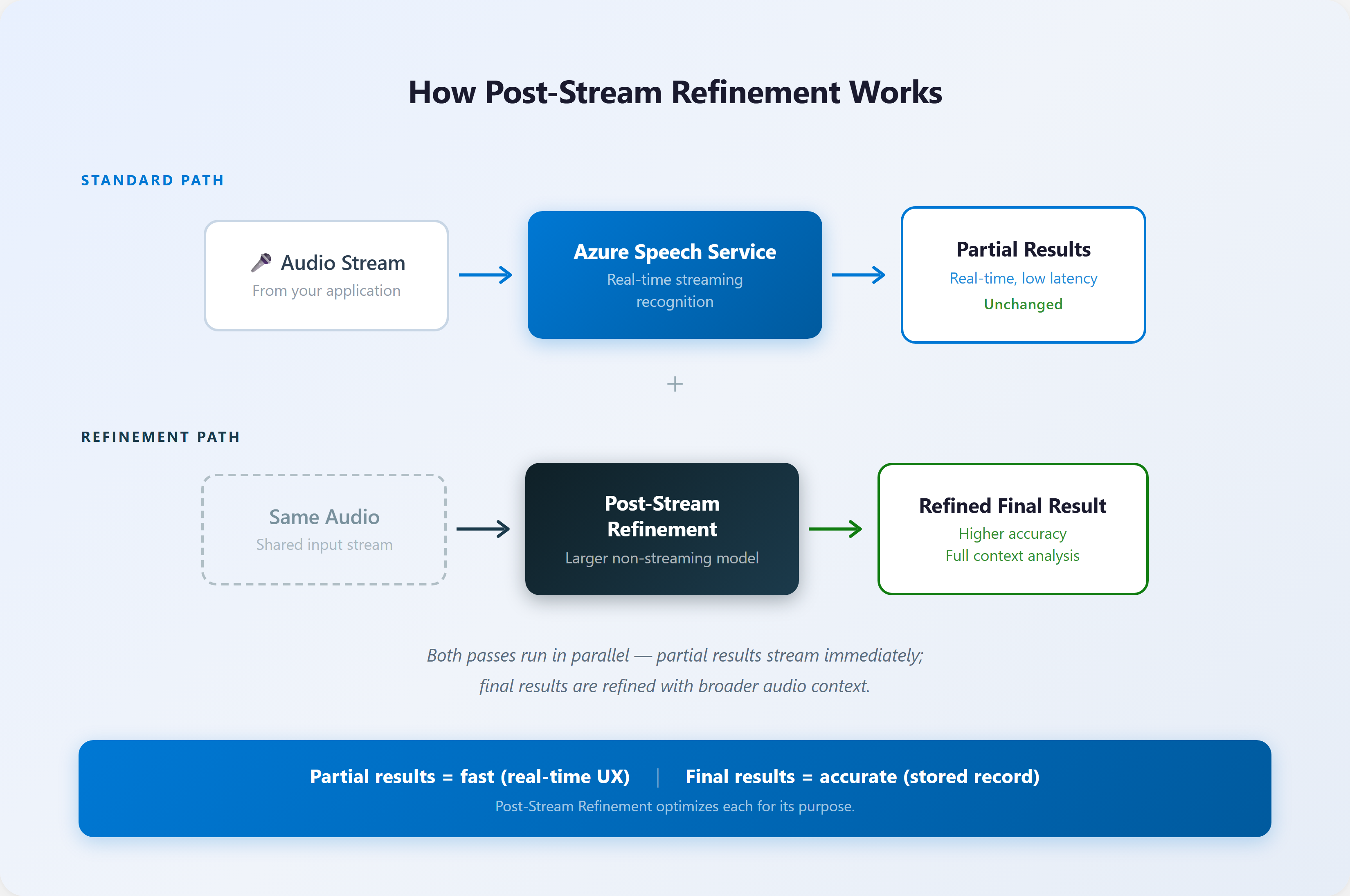
O Post-Stream Refinement não tenta forçar o modelo de tempo real a ser perfeito, mas introduz um segundo pass de processamento executado em paralelo. A arquitetura é elegante em sua simplicidade funcional:
- O pipeline de áudio original segue enviando dados, garantindo que o usuário receba resultados parciais instantâneos (baixa latência de
first-token). - Em paralelo, o Azure AI Speech realiza uma segunda análise, processando o segmento completo com um contexto de áudio mais amplo.
- Ao final da sentença, o resultado inicial é substituído pela versão refinada, corrigindo erros de formatação, pontuação e termos contextuais.
Impacto e Validação
O que torna essa novidade relevante para o mercado brasileiro é o fato de já ser um produto de infraestrutura validado. A tecnologia é a mesma que sustenta o speech-to-text no Microsoft Teams e no Microsoft 365 Copilot, lidando diariamente com milhões de interações em ambientes corporativos críticos.
Os ganhos reportados de redução na taxa de erros (token error rate) apresentam-se na casa dos dígitos duplos, o que, para times de engenharia que lidam com grandes volumes de dados de voz, significa um ganho direto em qualidade de analytics e eficiência de processos automatizados de IA.

Considerações Práticas
Para gestores e tomadores de decisão, a adoção desta tecnologia envolve uma simples alteração de configuração no SDK. No entanto, é importante monitorar como o comportamento de substituição de textos (o refinement ocorrendo sobre o que já foi exibido) impactará a interface da sua aplicação (UI/UX). Em cenários de uso onde a precisão final para bancos de dados ou logs (compliance) é a prioridade, o ganho de qualidade é imediato.
Para mais detalhes técnicos e guias de implementação, consulte a documentação oficial de post-processing da Microsoft e utilize os canais de suporte da Azure para entender como os ganhos de qualidade variam conforme o idioma e as condições acústicas específicas da sua operação.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
