

A equipe de SRE da STCLab opera clusters Amazon EKS de alta criticidade e, como muitas operações brasileiras que escalam rápido, enfrentava o gargalo da observabilidade: muito dado, mas pouco tempo para a curadoria. Embora estivessem usando uma stack madura — OpenTelemetry com Mimir, Loki e Tempo —, a triagem ainda exigia 15 a 20 minutos de correlação manual por incidente.
O desafio não era a falta de telemetria, mas o ciclo repetitivo: verificar pods, consultar o Prometheus, minerar logs no Loki e analisar traces distribuídos. A solução foi automatizar essa primeira camada usando o HolmesGPT (CNCF Sandbox).
Por que construímos isso
Nossa infraestrutura lida com tráfego global, e a fragmentação dos ambientes era um problema real. Alguns namespaces possuem visibilidade total, enquanto outros, em ambientes multi-tenant, dependem estritamente de kubectl e Prometheus. O objetivo era padronizar o primeiro passo da investigação automatizada diretamente na thread do Slack.
HolmesGPT: Deixando a LLM decidir o caminho da investigação
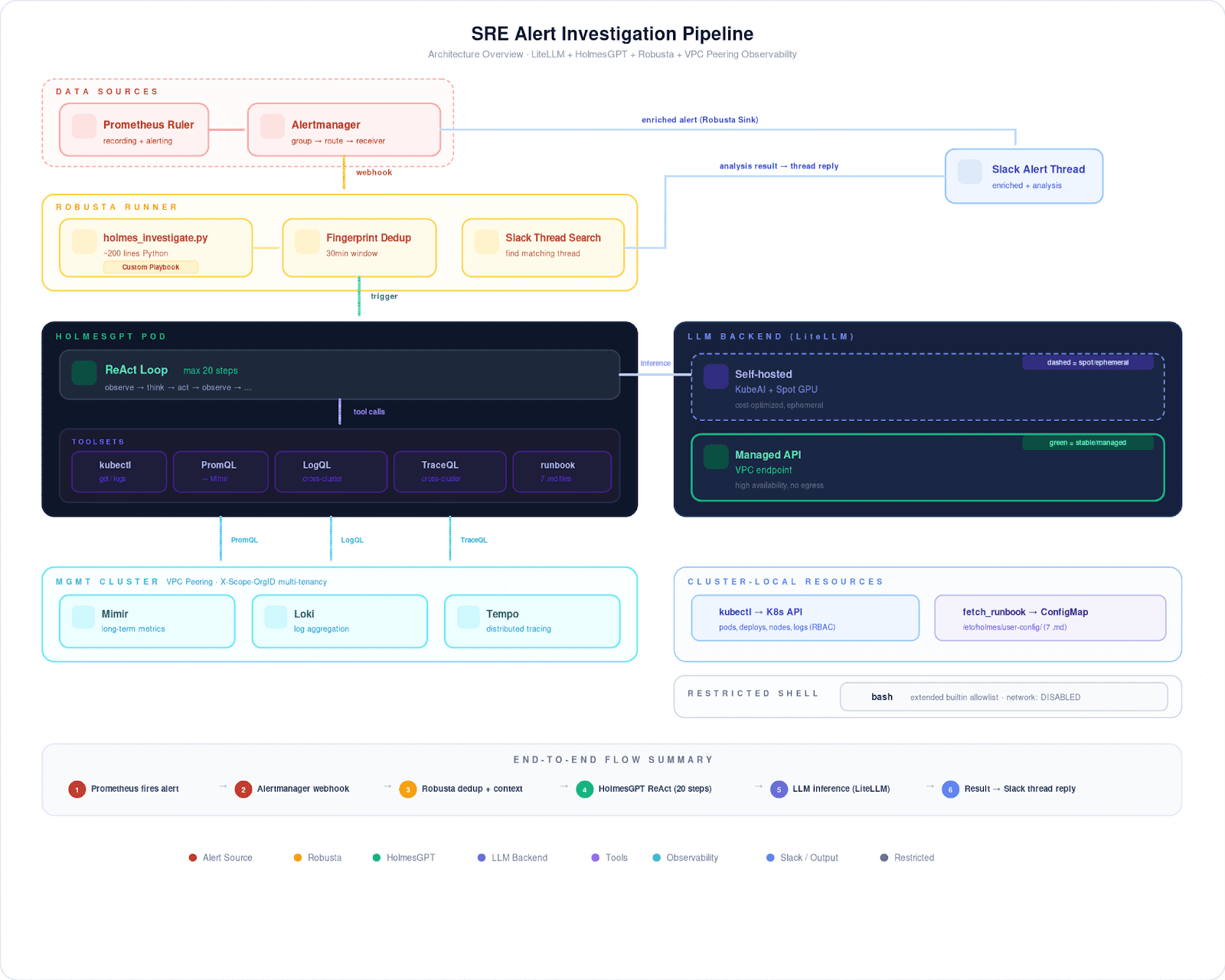
O uso do HolmesGPT baseia-se no padrão ReAct. Diferente de scripts estáticos, a IA lê o alerta, seleciona a ferramenta adequada (ex: checar código de saída, buscar logs via VPC peering, ou analisar pressão de CPU) e decide o próximo passo de forma dinâmica. O segredo da eficiência não foi a LLM, mas a estruturação dos dados via runbooks com metadados:
## Meta
scope: namespace=<target> only
tools: kubectl, prometheus, loki, tempo
caution: some containers excluded from log collection → use kubectl logs
Isso permite que o agente entenda, antes mesmo de começar, quais ferramentas estão disponíveis, evitando chamadas inúteis em ambientes restritos.
O valor dos Runbooks sobre o Modelo
Nosso erro inicial foi focar excessivamente na escolha da LLM. Comparamos o comportamento da IA com e sem runbooks guiados: sem eles, o modelo "alucina" hipóteses, tentando extrair métricas de Istio em namespaces sem sidecars ou consultando logs inexistentes no Loki. Com o uso de regras de exclusão nos runbooks, as chamadas desperdiçadas de ferramentas caíram de 16 para apenas 2 por investigação.
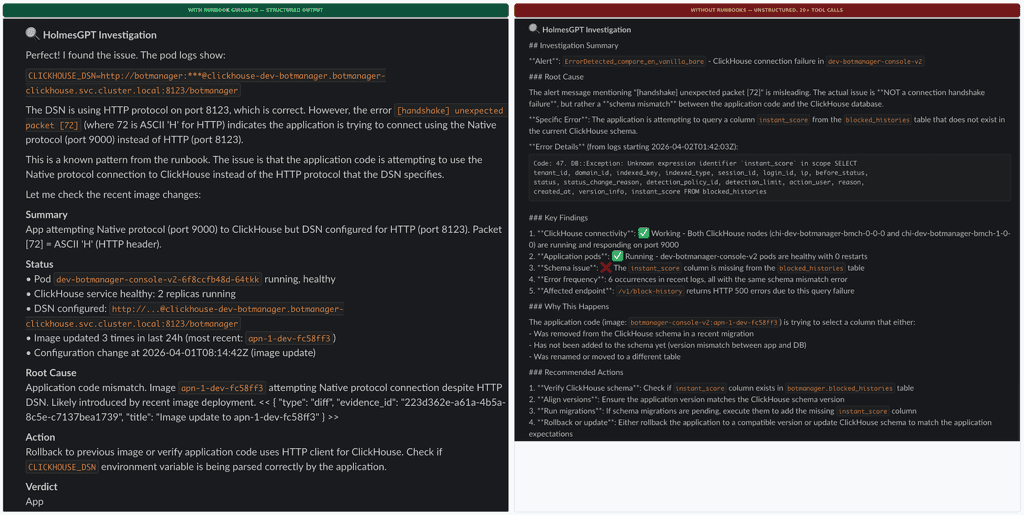
O resultado foi um salto de precisão. O mesmo alerta, processado pelo mesmo modelo, teve um desempenho radicalmente superior com a orientação de um runbook, reduzindo o custo computacional e o tempo de resolução.
A Jornada do Modelo: Hybrid Setup
Testamos desde modelos self-hosted (via KubeAI) até APIs gerenciadas. A conclusão prática é a necessidade de um design agnóstico: o código de "cola" (a playbook que trata deduplicação, roteamento para o Slack e thread matching) deve ser o core estável, enquanto o backend da LLM deve ser substituível conforme a necessidade de custo ou latência (atualmente usamos self-hosted em staging e APIs gerenciadas em produção).
Conclusões para Times de Engenharia
- Runbooks > Modelos: Regras de negócio e escopo definidos em texto estruturado superam ganhos de performance de qualquer modelo de linguagem.
- Glue Code é vital: O trabalho de um SRE não é apenas configurar a IA, mas criar a lógica de orquestração (tempo, roteamento, contexto) que torna o diagnóstico viável.
- Arquitetura Portável: Evite o lock-in. Separe sua lógica operacional do modelo de inferência.
Estamos expandindo o pipeline para consumir métricas de eBPF via Inspektor Gadget, provando que, uma vez consolidada a arquitetura, adicionar novas fontes de dados é um processo incremental e não disruptivo.
Artigo originalmente publicado por Grace Park and Ihyeok Song, DevOps Engineer, STCLab SRE Team em Cloud Native Computing Foundation.
