

Construir um agente de IA que funciona uma vez em um ambiente de desenvolvimento é trivial. Fazer com que ele opere de forma resiliente em produção, integrado a uma stack moderna como React ou Node.js, é um desafio de engenharia de software de outro nível.
(TL;DR: Para ir direto ao código, confira a Course Creator Agent Architecture no GitHub.)
É comum vermos times tentando encapsular fluxos complexos — como pesquisa, geração de conteúdo e validação — em um único script Python massivo ou em prompts que crescem descontroladamente. O resultado é sempre o mesmo: funciona localmente, mas ao integrar com o frontend, surgem picos de latência, pesadelos de debug e a impossibilidade de escalar partes específicas do sistema sem duplicar o monólito inteiro.
E se você não precisasse reescrever sua aplicação para acomodar a IA? A resposta está no orchestrator pattern. Ao invés de um agente omnipotente, desenhamos times de microserviços especializados e distribuídos. Essa abordagem permite integrar capacidades avançadas de IA diretamente na sua aplicação, mantendo a saúde do sistema.
Para isso, utilizamos o Agent Development Kit (ADK) da Google, conectamos os componentes via protocolo Agent-to-Agent (A2A) e realizamos o deployment desses serviços no Cloud Run, garantindo escalabilidade granular.
Por que Agentes Distribuídos? (E por que seu time de Frontend vai agradecer)
Imagine uma aplicação Next.js que precisa implementar uma funcionalidade de "Criador de Cursos". Em um modelo monolítico, o frontend fica bloqueado aguardando um processo de longa duração. Se a etapa de pesquisa falha ou demora, todo o request expira. Além disso, a escalabilidade é ineficiente: se você precisar de mais poder de processamento apenas para o avaliador (judge), você acaba sendo obrigado a escalar todo o serviço.
Com o padrão de orquestração distribuída temos ganhos claros:
- Integração fluida: O frontend interage com um único ponto (o orquestrador), ocultando a complexidade do backend.
- Escalabilidade independente: Precisa de mais poder no judge? Aloque recursos apenas para esse serviço. O serviço de pesquisa permanece leve.
- Modularidade: Você pode implementar o networking de alta performance em Go e a lógica de data science em Python. Eles se comunicam via HTTP, abstraindo a implementação.
O Blueprint: Sistema de Criação de Cursos
Dividimos o sistema em três especialistas:
- The researcher: Especialista em coleta de dados.
- The judge: Especialista em QA e conformidade.
- The orchestrator: O maestro que coordena a execução e interfaceia com o frontend.
Passo 1: O Pesquisador
Criamos um agente com o ADK focado apenas em utilizar ferramentas de busca.
# researcher/app/agent.py
from google.adk.agents import Agent
from google.adk.tools import google_search
researcher = Agent(
name="researcher",
model="gemini-2.5-flash",
description="Gathers information on a topic using Google Search.",
instruction="""
You are an expert researcher. Your goal is to find comprehensive information.
Use the `google_search` tool to find relevant information.
Summarize your findings clearly.
""",
tools=[google_search],
)
Passo 2: O Juiz (Structured Output)
Para garantir consistência, evitamos que o modelo "divague". Usamos Pydantic para forçar um formato de saída estrito.
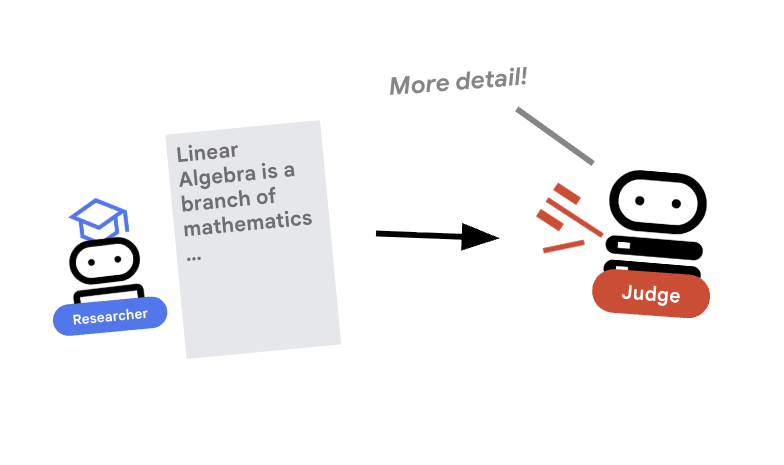
# judge/app/agent.py
from pydantic import BaseModel, Field
from typing import Literal
class JudgeFeedback(BaseModel):
status: Literal["pass", "fail"] = Field(
description="Whether the research is sufficient ('pass') or needs more work ('fail')."
)
feedback: str = Field(
description="Detailed feedback on what is missing."
)
judge = Agent(
name="judge",
model="gemini-2.5-flash",
description="Evaluates research findings.",
instruction="""
You are a strict editor. Evaluate the findings.
If they are missing key info, output status='fail' and provide feedback.
""",
output_schema=JudgeFeedback, # Enforce the contract!
)
Passo 3: Linguagem Universal (Protocolo A2A)
Encapsulamos esses agentes usando o Protocolo A2A. Ele permite que agentes descrevam suas capacidades via agent.json e comuniquem-se por HTTP.
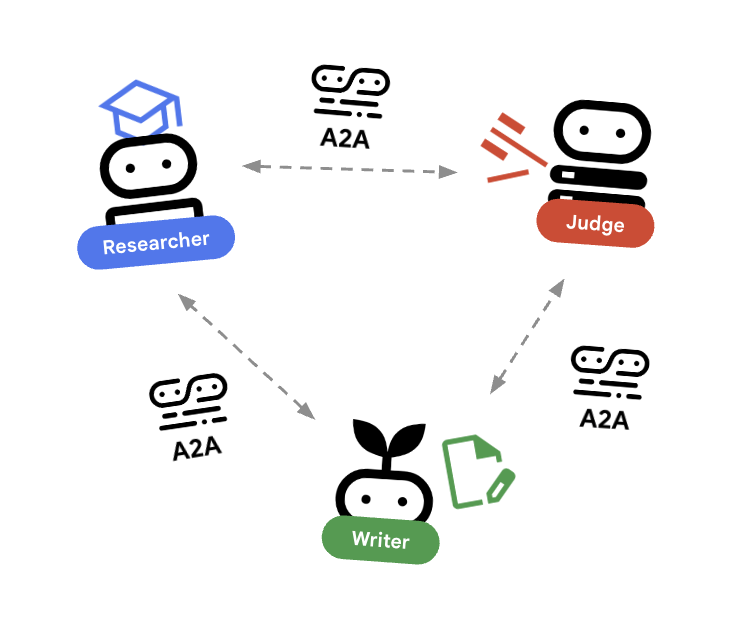
Passo 4: O Padrão de Orquestração
O orquestrador é o responsável por delegar tarefas. É a única interface que seu frontend conhece.
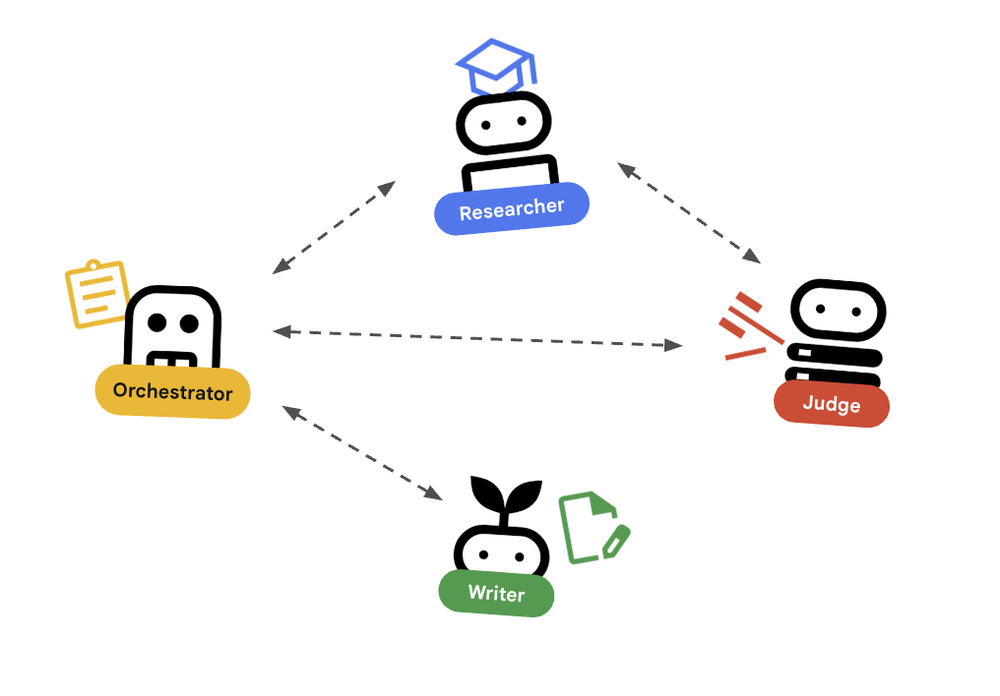
Considerações de Segurança e Operação
Ao colocar isso em produção, não ignore as boas práticas de infraestrutura:
- Autenticação: O tráfego inter-agentes deve ser protegido com mTLS ou OIDC.
- Latência: Cada salto de rede adiciona overhead. Avalie se a tarefa exige essa granularidade.
- Error Handling: Em arquiteturas distribuídas, o fail-safe é obrigatório. Implemente políticas de retentativa e timeouts agressivos no seu orquestrador.
Artigo originalmente publicado por Amit MarajAI Developer Relations Engineer em Cloud Blog.
