

O continuous profiling consolidou-se como uma peça essencial em stacks de observabilidade modernas e resilientes. Enquanto métricas indicam o "quando", logs explicam o "o que" e traces mostram o "onde" um gargalo ocorre, apenas o profiling entrega a visibilidade necessária para identificar exatamente qual função ou linha de código está consumindo recursos computacionais em excesso. Com o OpenTelemetry tratando Profiles como um sinal de observabilidade de primeira classe, o anúncio do Pyroscope 2.0 não é apenas uma atualização, mas uma resposta estratégica aos desafios contemporâneos de escalabilidade e custo de infraestrutura.
O caso para o always-on profiling
Para empresas brasileiras operando aplicações críticas em nuvem, o custo de infraestrutura é uma preocupação constante de FinOps. O overprovisioning de instâncias — muitas vezes realizado como uma medida de segurança contra picos de latência ou uso indevido de CPU/memória — acaba se tornando um passivo financeiro. O continuous profiling transforma essa gestão reativa em uma estratégia baseada em dados: ao visualizar o consumo de recursos em tempo real, times de engenharia podem realizar otimizações granulares, reduzindo drasticamente o desperdício sem impactar a estabilidade.
Além da eficiência financeira, o profiling contínuo é o acelerador definitivo no Mean Time to Resolution (MTTR). Em cenários de incident response, ele elimina a necessidade de debugging em staging ou a introdução de logging verboso em produção, permitindo a análise precisa do desvio de performance de uma deployment para outra.
Pyroscope 2.0: Rearchitecture voltada para performance
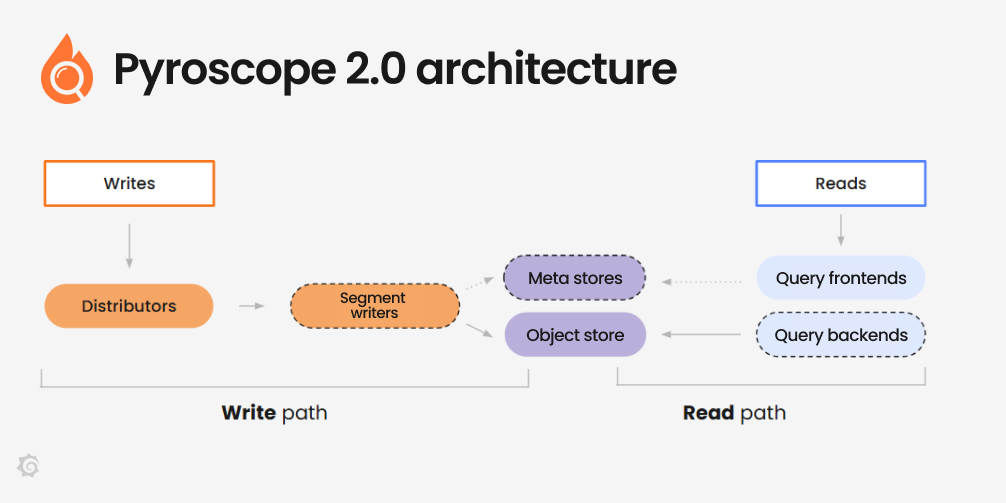
A arquitetura original do Pyroscope, herdada da base de Cortex, possuía limitações que dificultavam a operação em larga escala, especialmente devido ao overhead de replicação. O Pyroscope 2.0 segue as lições aprendidas pelo Mimir e Loki, otimizando caminhos de escrita e leitura para um ambiente cloud-native:
- Eficiência de Armazenamento: A eliminação da replicação no write path e a implementação de uma estratégia mais inteligente de co-localização de dados reduzem o volume armazenado — uma economia vital quando lidamos com stack traces e symbols que representam a maior parte do custo de armazenamento.
- Escalabilidade sem Estado: A transição do read path para uma arquitetura stateless permite que queriers escalem elasticamente de acordo com a demanda. Isso resolve o problema de pagar por capacidade ociosa, permitindo que a infraestrutura suporte picos de carga durante investigações de incidentes ou análises conduzidas por agentes de IA.
Simplicidade Operacional e o Futuro
A redução da complexidade, com a remoção de componentes stateful e o uso de storage baseado em objetos, simplifica deployments e rotinas de manutenção. Internamente, a Grafana Labs validou essa arquitetura processando 19.5PB de dados, evidenciando sua robustez para ambientes de produção massivos.
Para times de engenharia, a nova arquitetura não é apenas uma melhoria na forma de operar, mas uma plataforma que viabiliza novas capacidades analíticas, como heatmap queries para visão de distribuições de performance e a correlação direta de profiles com métricas de negócio. A migração para o 2.0 é recomendada, exigindo atenção à adoção obrigatória de object storage como fonte de verdade para os dados de perfil.
Artigo originalmente publicado por Christian Simon em Grafana Labs blog on Grafana Labs.
