

TL;DR
Este artigo analisa o desempenho de agentes de IA em correções de bugs no Kubernetes, comparando RAG, abordagens híbridas e acesso local. A conclusão principal é que o gargalo não é encontrar o código (retrieval), mas o raciocínio sistêmico. Agentes frequentemente falham em identificar mudanças correlacionadas em múltiplas camadas, optando por correções isoladas e tecnicamente inferiores. Para empresas, isso reforça que a IA ajuda na produtividade, mas exige supervisão rigorosa de arquitetura e qualidade técnica.
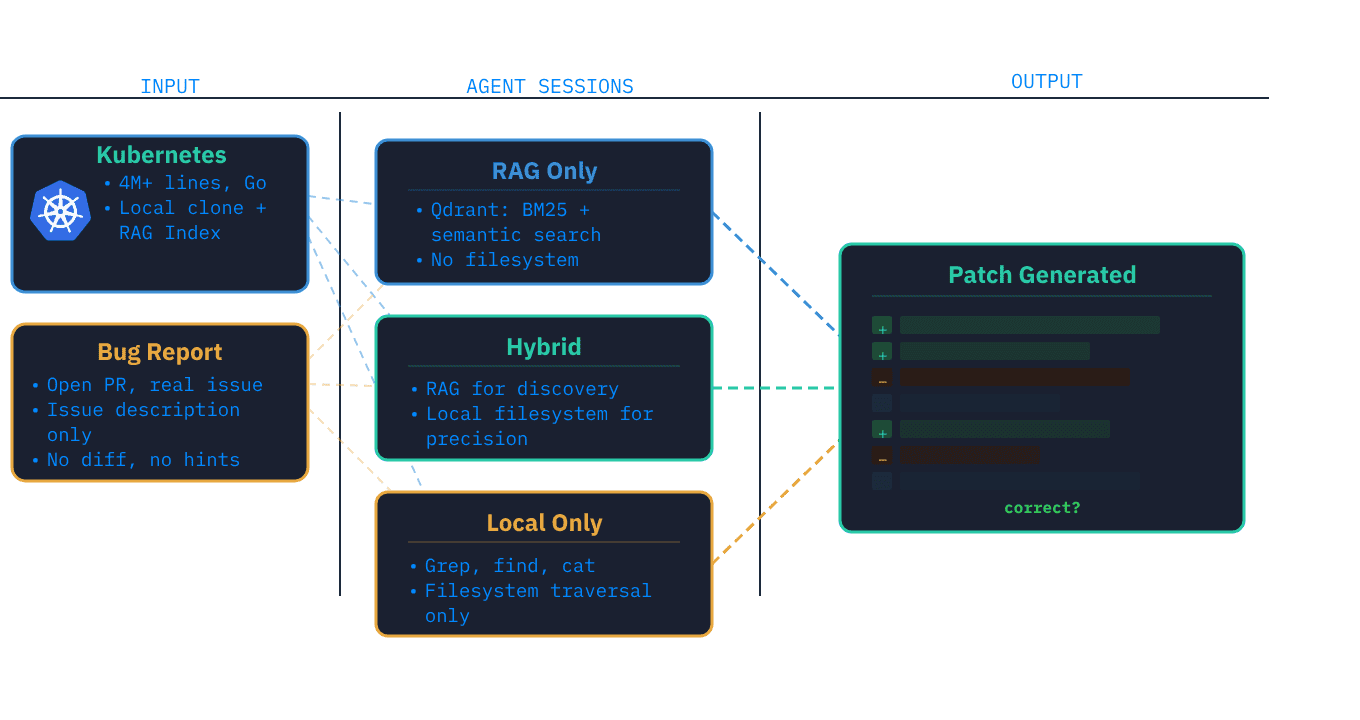
Tenho integrado agentes de codificação por IA ao workflow diário de engenharia e decidi testar a eficácia real dessas ferramentas em bugs reais. O teste consistiu em rodar uma série de experimentos estruturados utilizando reports de bugs críticos do repositório do Kubernetes, avaliando se agentes poderiam entregar correções precisas em uma codebase de milhões de linhas sem orientação humana.
Minha premissa era otimista: o sucesso dependeria puramente da capacidade de recuperação (retrieval). Se um modelo conseguisse encontrar os arquivos certos (via RAG ou busca de sistema de arquivos), ele seria capaz de gerar a correção. Na prática, essa premissa falhou. Mesmo localizando os arquivos certos, os agentes frequentemente não conectavam as mudanças entre eles, falhando em compreender o escopo real do problema ou entregando patches localmente plausíveis, mas globalmente incorretos. O gargalo não é a busca; é o raciocínio sobre o contexto sistêmico.
O Setup do Experimento
Utilizei pull requests ativos do repositório kubernetes no GitHub. Apenas a descrição do issue foi fornecida, simulando um ambiente de trabalho real para três configurações de agentes:
- RAG Only: Busca híbrida via motor de RAG da KAITO (Qdrant), combinando BM25 e busca semântica por embeddings.
- Hybrid (RAG + Local): O mesmo índice de RAG, mas com acesso completo ao clone local do repositório para leitura de precisão.
- Local Only: Acesso total via
grep,findecat, confiando apenas em exploração direta.
Cada agente operou em isolamento, utilizando o modelo Claude Opus 4.6 com um timeout rígido de 5 minutos.
Os casos de teste (Benchmark)
Avaliei correções reais em áreas críticas como kubelet, scheduler, redes e storage. O benchmark mediu os resultados com base em cinco pilares: arquivos alterados, localização da função, preservação de invariantes de sistema, cobertura de testes e completude do patch.
| PR | Bug | SIG | Tamanho |
| #134540 | Race condition em SubPath | sig/storage | XS |
| #138211 | Envenenamento de log de pull de imagem | sig/node | M |
| #138244 | Stall de topologia NUMA | sig/node | L |
| #136013 | OOM score panic em memória zero | sig/node | S |
| #138269 | Missing Pod/Update event | sig/scheduling | S |
| #138158 | Race condition em ServiceCIDR | sig/network | M |
| #135970 | Missing initializer no StatefulSet | sig/apps | M |
| #138000 | Limpeza de endpoint stale no Windows | sig/network | XL |
| #138191 | Status de container (rollback de clock) | sig/node | M |
Latência e Eficiência Operacional
O RAG provou ser consistentemente o mais rápido (média de 1m16s), pois elimina a necessidade de navegação manual. O modelo Híbrido foi o mais lento (média de 2m25s) devido ao overhead de trocar entre o contexto de busca e a leitura de arquivos, o que evidencia que, em operações de engenharia, a orquestração do fluxo de trabalho é tão importante quanto a capacidade do modelo.
O que aprendemos sobre a prática de IA
- Agentes corrigem sintomas, não sistemas: Em muitos casos, o agente "engoliu" um erro de sistema em vez de propagá-lo corretamente, priorizando a estabilidade local da função em vez da integridade da arquitetura.
- A descoberta de escopo é o gargalo: Agentes frequentemente param quando o "primeiro erro" é corrigido, ignorando dependências secundárias. Em um ecossistema complexo como o Kubernetes, isso é fatal para a estabilidade.
- Qualidade do input resolve mais que toolings complexos: Quando a issue descrevia exatamente onde olhar, a performance entre RAG e busca local praticamente convergia. A precisão do input humano ainda é o maior multiplicador de eficiência para a IA.
Conclusão: Raciocínio vs. Recuperação
Os resultados deixam claro: a IA pode ajudar na navegação em codebases, mas a falta de compreensão sistêmica limita sua autonomia operacional. Implementar soluções de IA em infraestrutura exige que seus times mantenham o papel de supervisores arquiteturais. A ferramenta acelera, mas não substitui a necessidade de manter processos robustos de code review e observabilidade.
Perguntas Frequentes
- O RAG é sempre a melhor estratégia para grandes repositórios?
Não necessariamente. Embora o RAG acelere a descoberta inicial do código, ele não garante que o agente entenda as implicações sistêmicas da mudança, frequentemente resultando em correções incompletas em comparação com abordagens que permitem navegação local profunda. - Por que agentes de IA falham frequentemente em correções multiarquivo?
O problema reside na descoberta de escopo. Os agentes tendem a focar na solução imediata descrita no bug, parando assim que o sintoma parece resolvido, sem realizar a propagação necessária de mudanças em arquivos dependentes ou interfaces de integração. - Qual a relação entre o custo de API e a escolha do fluxo de trabalho?
O custo é impulsionado principalmente pelo número de chamadas ao modelo e pelo reprocessamento de contexto (replay). Abordagens que exigem múltiplos ciclos de 'ida e volta' entre busca por RAG e exploração local tendem a ser mais caras e lentas.
Artigo originalmente publicado por epower em Cloud Native Computing Foundation.
