

TL;DR
Este artigo analisa a implementação do 'Ramble' pela Doist, que utiliza a Gemini Enterprise Agent Platform do Google Cloud para converter fala espontânea em listas de tarefas estruturadas. A solução elimina a transcrição intermediária ao enviar áudio PCM bruto diretamente ao modelo, reduzindo a latência e otimizando o tool calling. A principal conclusão é que, em cenários de alta complexidade, o uso de modelos especializados aliando abstração de infraestrutura e testes semânticos é vital para garantir estabilidade operacional e escalabilidade.
Fundada em 2007, a Doist é referência em trabalho remoto e assíncrono. Sua mais recente inovação, o Ramble, busca transformar fluxos de consciência — falas rápidas e não estruturadas — em tarefas organizadas no Todoist, removendo a fricção da digitação manual.
Quais foram os principais desafios de engenharia?
Para viabilizar uma interface baseada em fala que realmente entregasse valor, o time de engenharia da Doist mapeou quatro gargalos técnicos críticos:
- Comunicação em tempo real: Necessidade de latência mínima e capacidades de tool calling autônomo.
- Suporte multilíngue massivo: Tratamento de gírias, acentos e variações regionais além dos idiomas padrão.
- Testes de não-determinismo: A IA, por natureza, não segue saídas fixas, exigindo uma nova abordagem para validação semântica.
- Estabilidade de áudio: Garantir entrega consistente através de diversos ambientes de browser e dispositivos móveis.
Como a solução foi desenhada para alta performance?
A arquitetura baseia-se na Gemini Enterprise Agent Platform. Em vez de seguir o pipeline tradicional de Speech-to-Text seguido por um LLM, o fluxo envia áudio bruto (PCM) diretamente para o modelo. Esse processo reduz drasticamente a latência e permite que o modelo execute funções (addTask, editTask, deleteTask) de forma autônoma enquanto o usuário ainda está falando.
A importância da arquitetura em camadas
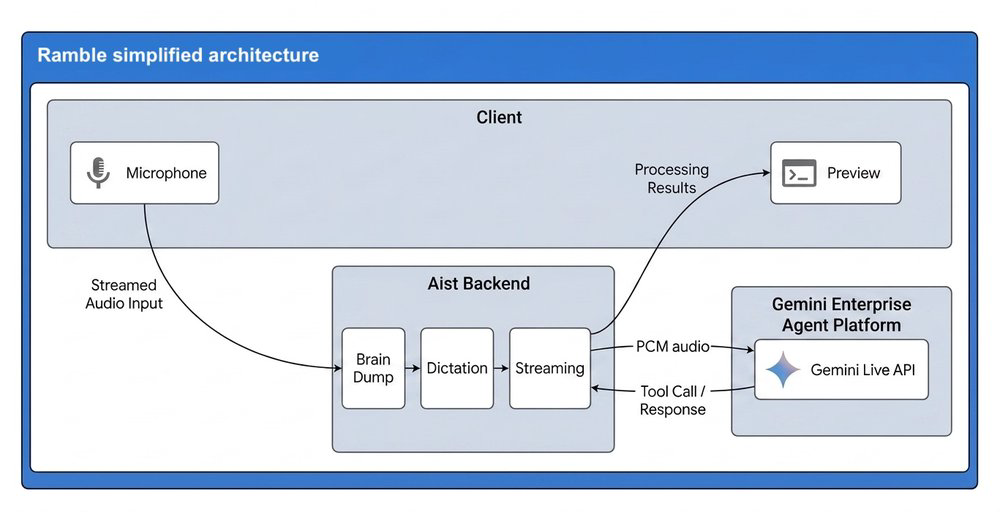
O diagrama acima ilustra a robustez da solução. Ao implementar uma camada de abstração provider-agnostic, a Doist garantiu que o Ramble não ficasse limitado a um único provedor. Se amanhã houver necessidade de rodar modelos locais ou mudar o fornecedor, o impacto no core da aplicação é minimizado. Além disso, o uso de resumption tokens facilitou a persistência de estado, algo que inicialmente parecia exigir uma engenharia de backend complexa.
Como garantir qualidade em ambientes de produção?
O grande desafio não foi apenas a infraestrutura, mas a validação. A estratégia adotada foi a de "LLM-as-a-judge": um segundo modelo avalia se a saída gerada pelo primeiro modelo está alinhada semantemicamente ao que o usuário esperava. Combinando isso com um set de testes contendo mais de 100 variações de áudio, o time consegue monitorar regressões por idioma e decidir se uma nova versão do modelo é apta para o ambiente de produção.
Perguntas Frequentes
-
Como a Doist resolveu o desafio de latência na captura de tarefas?
A empresa optou por enviar o áudio em formato PCM bruto diretamente para o modelo via Gemini Live API. Isso elimina o passo de transcrição prévia, permitindo que o modelo realize o processamento de linguagem e identifique intenções em uma única passagem. -
Como validar modelos de IA não-determinísticos em produção?
A Doist utiliza uma estratégia de 'LLM-as-a-judge', onde um segundo modelo avalia a saída do primeiro comparando-a com resultados semânticos esperados. Isso é combinado com testes estruturais e gravações reais em diferentes idiomas para medir o desempenho de forma sistemática. -
É possível manter a flexibilidade entre diferentes provedores de IA?
Sim, a arquitetura foi desenhada com uma camada de abstração provider-agnostic. Isso permite que a empresa alterne o motor de processamento (LLM) subjacente sem precisar refatorar a lógica de infraestrutura de voz e streaming de áudio.
Artigo originalmente publicado por Gonçalo SilvaChief Technology Officer, Doist em Cloud Blog.
