

Desde o lançamento da customização do Amazon Nova no Amazon SageMaker AI, o mercado brasileiro de tecnologia tem buscado paridade de recursos entre esses modelos proprietários e os modelos de pesos abertos (open weights). A demanda principal? Controle granular. Empresas que operam em escala precisam de flexibilidade para ajustar tipos de instâncias, políticas de auto-scaling e configurações de concorrência que os workloads de produção exigem.
Hoje, analisamos o anúncio da disponibilidade geral (GA) do suporte a modelos Nova customizados no Amazon SageMaker Inference. Trata-se de um serviço gerenciado de nível de produção, configurável e focado em eficiência de custos para implantar modelos Nova de rank completo.
Na prática, isso significa que times de engenharia no Brasil agora possuem uma jornada end-to-end: é possível treinar modelos Nova Micro, Nova Lite e Nova 2 Lite (com suporte a reasoning) utilizando Amazon SageMaker Training Jobs ou Amazon HyperPod, e implantá-los diretamente na infraestrutura de inferência gerenciada do SageMaker AI.
Eficiência Operacional e FinOps: Além do P5
Um dos pontos mais críticos para empresas brasileiras, dado o custo de infraestrutura em nuvem, é a otimização de recursos. Com o SageMaker Inference para modelos Nova customizados, é possível reduzir o custo de inferência através da utilização otimizada de GPUs em instâncias Amazon EC2 G5 e G6, que costumam oferecer um melhor custo-benefício em comparação às instâncias P5 para diversos casos de uso.
Além disso, o suporte a auto-scaling baseado em padrões de uso de 5 minutos e parâmetros de inferência configuráveis (como context length, concorrência e batch size) permite que arquitetos de soluções equilibrem o trade-off entre latência, custo e precisão de forma específica para cada workload.
Como implantar modelos Nova customizados no SageMaker Inference
Se você já possui um artefato de modelo Nova treinado (via continued pre-training, supervised fine-tuning ou reinforcement fine-tuning), a implantação pode ser feita via SageMaker Studio ou SageMaker AI SDK.
No SageMaker Studio, basta selecionar o modelo treinado no menu Models. O processo de deployment é iniciado através do botão Deploy, selecionando SageMaker AI e Create new endpoint.
Ao configurar o endpoint, você define o nome do serviço, o tipo de instância e opções avançadas como contagem de instâncias e isolamento de rede. Na fase de GA, as instâncias suportadas variam conforme o modelo:
- Nova Micro: Suporta
g5.12xlargeatép5.48xlarge. - Nova Lite: Focado em instâncias
g5.48xlarge,g6.48xlargeep5.48xlarge. - Nova 2 Lite: Requer o poder de processamento das instâncias
p5.48xlarge.
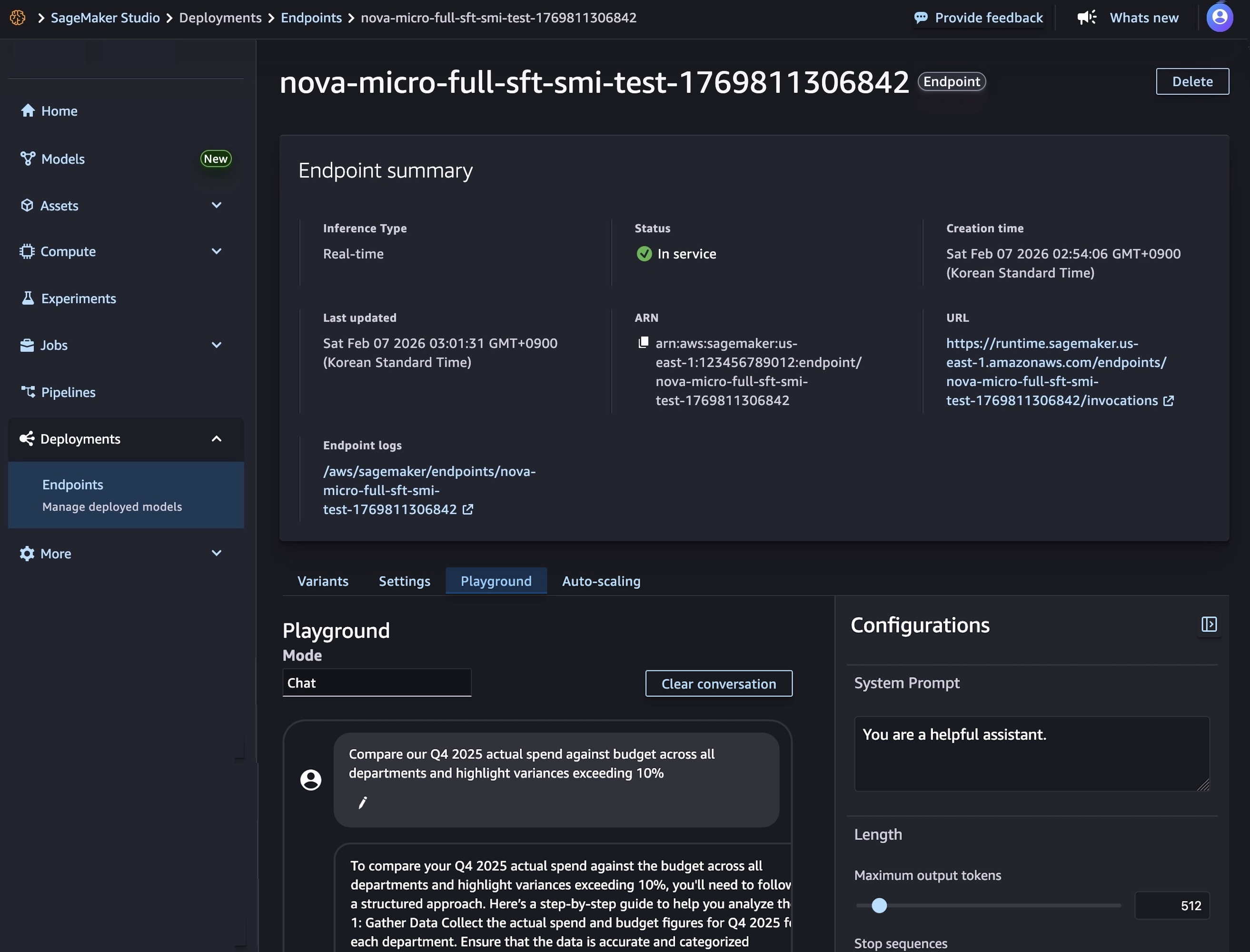
Após o provisionamento da infraestrutura e inicialização do container de inferência, o endpoint muda para o status InService. A partir daí, é possível testar o modelo diretamente no Playground do SageMaker, enviando prompts em modo Chat.
Implementação via SDK: O caminho para automação
Para times de DevOps e engenheiros de Machine Learning que buscam integração com pipelines de GitOps, o uso do SageMaker AI SDK é o caminho recomendado. O código abaixo exemplifica a criação de um modelo referenciando os artefatos no S3 e definindo variáveis de ambiente como CONTEXT_LENGTH e MAX_CONCURRENCY:
# Criando um modelo no SageMaker AI
model_response = sagemaker.create_model(
ModelName= 'Nova-micro-ml-g5-12xlarge',
PrimaryContainer={
'Image': '708977205387.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://seu-bucket/caminho/para/artefatos/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# Parâmetros do Modelo
'Environment': {
'CONTEXT_LENGTH': 8000,
'MAX_CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Modelo criado com sucesso!")
Posteriormente, configura-se o endpoint real-time, que fornecerá uma interface HTTPS segura para as requisições:
# Configuração do Endpoint
production_variant = {
'VariantName': 'primary',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config',
ProductionVariants= production_variant
)
# Deployment do endpoint
endpoint_response = sagemaker.create_endpoint(
EndpointName= 'Nova-micro-ml-g5-12xlarge-endpoint',
EndpointConfigName= 'Nova-micro-ml-g5-12xlarge-Config'
)
O SageMaker AI suporta tanto endpoints síncronos (com modos streaming e non-streaming) quanto endpoints assíncronos para processamento em lote (batch processing).
Disponibilidade e Considerações Estratégicas
Atualmente, a inferência para modelos Nova customizados está disponível nas regiões US East (N. Virginia) e US West (Oregon). Para empresas brasileiras que operam com sensibilidade à latência, é vital considerar o posicionamento geográfico desses modelos em relação à sua base de usuários, embora a robustez do SageMaker compense muitos desafios de rede em aplicações não-críticas em milissegundos.
O modelo de cobrança segue o padrão de instâncias de computação utilizadas por hora, sem compromissos mínimos, o que favorece estratégias de teste e validação de ROI antes de grandes deployments.
Artigo originalmente publicado por Channy Yun (윤석찬) em AWS News Blog.
