

Cada prompt enviado a um serviço de IA gerenciado por terceiros atravessa uma fronteira de rede sobre a qual você tem pouca visibilidade. Para empresas brasileiras em setores regulados (fintechs, setor público ou saúde) ou que protegem propriedade intelectual sensível, enviar código e lógica de negócio para APIs externas não é apenas uma preocupação teórica — é um bloqueador de compliance e um risco de segurança.
A oportunidade reside em self-hosting: rodar seu próprio agente de codificação de IA, utilizando sua GPU dedicada dentro do seu próprio tenant do Azure. Isso elimina a exposição de PII (Personally Identifiable Information) e assegura que nenhum dado saia do seu perímetro de controle.

Por que o Serverless GPU no Azure Container Apps (ACA)?
O uso de Serverless GPU no Azure Container Apps remove a carga operacional de gerenciar VMs, clusters complexos de Kubernetes ou drivers específicos de GPU. O modelo é direto: você tem um container, uma GPU alocada sob demanda e um endpoint HTTPS. Os principais impactos estratégicos para times de engenharia no Brasil são:
- Privacidade Total: Seu código e seus prompts nunca saem da sua subscription. É o caminho mais célere para atender a normas como a LGPD, além de políticas internas rigorosas de IP.
- Previsibilidade de FinOps: Esqueça o modelo de "pay-per-token". Você paga pelo tempo de computação da GPU. Para fluxos de trabalho intensivos de refatoração, documentação e análise de código, esse modelo oferece um controle de custos muito mais estável.
- Sem Rate Limiting: A capacidade é sua. Não há throttling externo ou filas de espera, garantindo latência consistente para o seu time de desenvolvimento.
- Agilidade e Flexibilidade: O fluxo permite alternar modelos rapidamente. O Gemma 4 (4B) é ideal para iteração veloz, enquanto o modelo de 26B oferece capacidade aumentada para tarefas de arquitetura mais complexas.
Implementação na prática
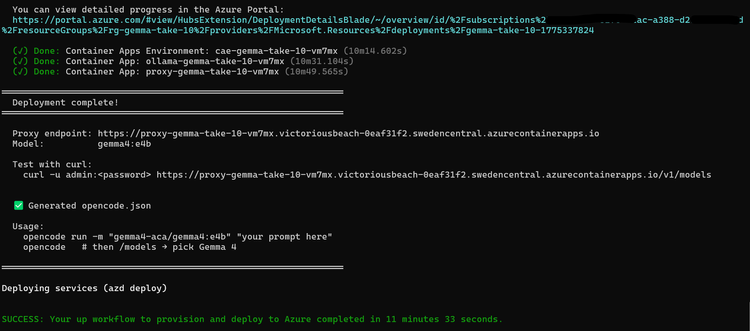
O template proposto (utilizando azd up) orquestra dois containers essenciais:
- Ollama + Gemma 4: Responsável pelo processamento, rodando em uma GPU (NVIDIA T4 ou A100) e expondo uma API compatível com o formato da OpenAI.
- Nginx Auth Proxy: Atua como um reverse proxy leve que impõe autenticação, garantindo que o acesso ao endpoint seja restrito e seguro.
O Ollama realiza o pull do modelo na inicialização, minimizando o tempo de setup. Como o proxy roda em um perfil de consumo gratuito, a otimização de custo é focada estritamente onde a GPU é necessária.
Otimização e Performance
Ao escolher o tamanho do modelo, o balanço entre capacidade de raciocínio e o hardware disponível é crítico. Testes realizados (usando Ollama v0.20, quantização Q4_K_M) mostram que, no Brasil, o uso da região brazilsouth é altamente recomendado para minimizar a latência de rede:
| Modelo | GPU | Tokens/sec | Notas |
|---|---|---|---|
gemma4:e4b |
T4 | ~51 | Melhor custo-benefício para T4 |
gemma4:26b |
A100 | ~113 | Recomendado para raciocínio complexo |
Analisando o caso de uso: Privacy-First
Esta abordagem é vital para:
- Setor Financeiro: Algoritmos de trading que residem em zona segura.
- Saúde (HIPAA/LGPD): Dados de pacientes que não podem ser processados em nuvem pública sem garantias.
- IP Sensível: Startups que desejam a aceleração da IA sem entregar o "código-fonte do negócio" para provedores de modelo.
Com o azd down, a infraestrutura é removida, e a capacidade de scale-to-zero assegura que os custos não se acumulem quando o time não estiver em horário de desenvolvimento.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
