Na Nuvem Online, acompanhamos diariamente o dilema de empresas brasileiras que escalam suas aplicações de Inteligência Artificial: como manter a performance e a alta disponibilidade exigidas pelo negócio sem inflar o budget com o consumo de tokens?
A resposta para essa questão não reside em escolher o modelo mais barato, mas em desenhar uma orquestração inteligente de serviços que se adeque exatamente aos padrões de carga da sua aplicação. Não estamos falando de simples otimização de infra, mas de uma gestão estratégica onde o custo vira uma variável controlável e previsível.
Entendendo a base: Pay-as-You-Go (PayGo)
Para a grande maioria das cargas de trabalho, o modelo PayGo do Google Cloud é o ponto de partida ideal pela sua flexibilidade. Contudo, é preciso compreender como ele opera sob o capô para evitar surpresas no monitoramento de erros e latência.
1. Dynamic Shared Quota (DSQ)
O DSQ é o mecanismo de equidade do Vertex AI. Ele não impõe limites rígidos e estáticos por cliente, mas distribui a capacidade global de forma inteligente.
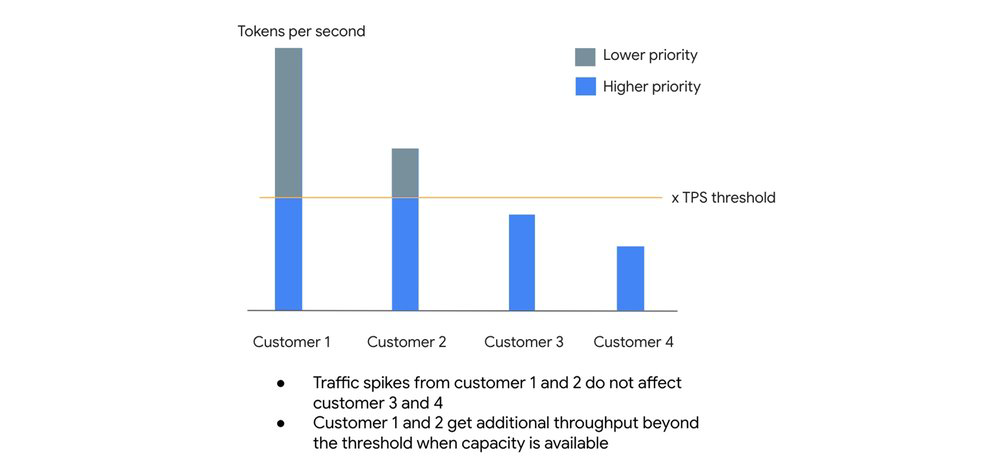
Como funciona na prática:
- High-priority lane: Sua organização possui um threshold de Tokens Per Second (TPS). Dentro desse volume, a prioridade é alta, visando um SLO de 99.5%.
- Best-effort lane: Se você ultrapassar seu threshold, as requisições não são descartadas imediatamente. Elas entram em uma fila de baixa prioridade, aproveitando a capacidade ociosa do sistema. Isso previne que picos de tráfego de um cliente impactem o baseline de outro.
2. Usage Tiers: Escalabilidade progressiva
O Google Cloud ajusta seus limites automaticamente com base nos seus gastos dos últimos 30 dias. É fundamental entender que o seu limite de Tokens Per Minute (TPM) em cada nível é um piso, não um teto.
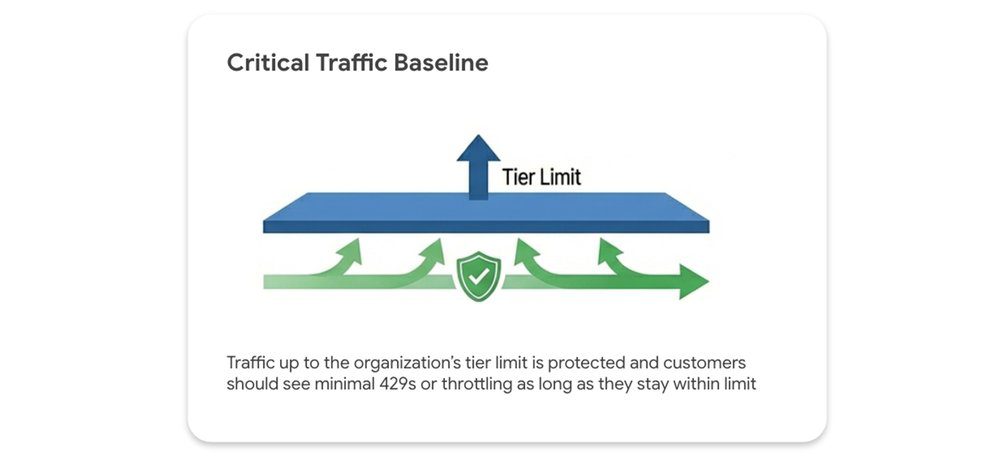
- Critical traffic: Dentro do limite, você raramente encontrará erros 429 (resource exhausted).
- Opportunistic bursting: Acima do limite, você opera em modo best-effort. Se houver capacidade residual, sua aplicação continua entregando normalmente.
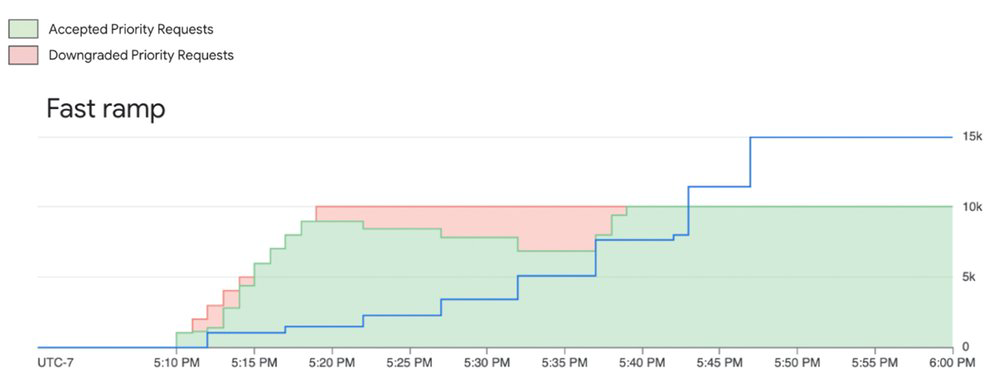
3. Priority PayGo: Mitigando instabilidade
Se sua aplicação possui picos imprevisíveis e você não pode arcar com erros 429, mas ainda não justifica um contrato de capacidade reservada, o Priority PayGo é a solução. Você pode definir prioridade via header nas chamadas de API, garantindo que suas requisições mais sensíveis tenham precedência, mesmo com um custo premium aplicado sob demanda.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Shared-Request-Type: priority" \
https://aiplatform.googleapis.com/...
Provisioned Throughput (PT) para Workloads Críticos
Quando a disponibilidade é inegociável, o Provisioned Throughput (PT) é a escolha correta. Aqui, você reserva capacidade e obtém um SLA formal de disponibilidade. Diferente do PayGo, erros ocasionados por saturação no PT são contabilizados no seu SLA, garantindo maior previsibilidade para sistemas de produção core.
Você também ganha um controle granular, podendo barrar overages com o header dedicated se sua prioridade for um controle orçamentário rígido, ou utilizar o header shared para experimentos que não devem consumir sua reserva de capacidade.
Otimização via Batch API e Flex PayGo
Nem toda carga de IA exige latência de milissegundos. Se sua operação envolve processamento massivo de logs, classificação de tickets ou geração de relatórios diários, as novas opções de Batch e Flex PayGo oferecem descontos de até 50% em relação ao custo do token padrão. A chave é separar o que é real-time do que é assíncrono.
Recomendamos a todos os nossos clientes que realizem uma revisão periódica de métricas no Cloud Monitoring (aiplatform.googleapis.com/PublisherModel). Dados precisos sobre /consumed_token_throughput são o que transformam uma tentativa de economia em uma estratégia de FinOps sustentável.
Artigo originalmente publicado por Federico PreliData and AI Architect, Google Cloud em Cloud Blog.