


O desafio de colocar agentes de IA em produção
No post anterior, discutimos a implementação de uma arquitetura multi-agente para planejamento de viagens no Azure App Service usando o Microsoft Agent Framework (MAF) 1.0 GA. Embora o deploy seja um marco, o verdadeiro desafio operacional começa quando os agentes entram em produção. Times de engenharia enfrentam cenários onde APM tradicional não é suficiente: você precisa entender a fundo o consumo de tokens e a eficácia das chamadas de ferramentas.
Para gestores de TI, a visibilidade sobre quem consome mais recursos e onde o workflow estagna é crucial para o controle de custos e performance, especialmente em sistemas de IA que utilizam modelos com precificação por token.
Otimize sua infraestrutura para IA com visibilidade real
A nova visão: Agents (Preview) no Application Insights
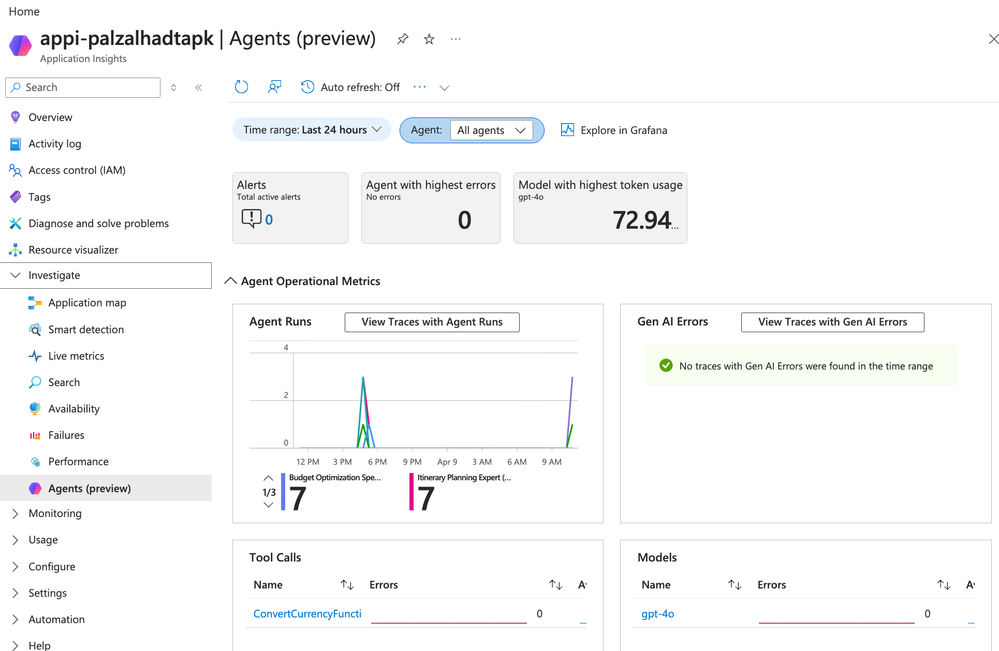
O Azure Application Insights introduziu uma blade dedicada, chamada Agents (Preview), que traz uma camada de inteligência específica para monitorar agentes. A grande vantagem aqui é a conformidade nativa com as convenções semânticas de GenAI do OpenTelemetry. Isso evita que você precise criar dezenas de dashboards customizados do zero para entender o comportamento dos seus LLMs.
- Filtragem intuitiva: Identifique latência e throughput por cada agente (nosso exemplo, o Travel Planning Coordinator).
- Gestão de Custos: Visualize o consumo de tokens input e output para evitar surpresas no billing do seu fornecedor de IA.
- Workflow End-to-End: Debugue falhas complexas vendo exatamente qual tool call ou model call causou um gargalo.
A fundação: OpenTelemetry GenAI Semantic Conventions
Essa visibilidade não é mágica. Ela depende diretamente da implementação das convenções semânticas de GenAI. Ao estruturar seu código para emitir atributos como gen_ai.agent.name, gen_ai.operation.name e tokens de uso, você estabelece um contrato de dados que qualquer backend compatível — não apenas o Azure Monitor — consegue processar.
Instrumentação de dois níveis
Para ter uma observabilidade completa, recomendamos a instrumentação em duas camadas:
- Nível IChatClient (LLM): Focado puramente na performance do modelo. Ao envolver seu client com
.UseOpenTelemetry(), você captura tokens e latência bruta do provider. - Nível Agent (Contexto): Onde o MAF emite spans trazendo a identidade do agente. Isso é vital para a separação de responsabilidades e para entender qual agente está falhando no pipeline.
Manter ambos ativos pode gerar uma leve redundância de logs, mas é o cenário ideal para um troubleshooting eficiente quando o custo de falha da sua aplicação de IA for alto.
Conclusão e Próximos Passos
Integrar essas práticas não apenas melhora a visibilidade, mas empodera o time de engenharia a realizar rollbacks ou ajustes de prompt com dados, não com palpites. A portabilidade do OpenTelemetry, junto com a integração nativa no Azure App Service através apenas de ambiente de configuração ou uma linha de código AddAzureMonitor(), torna a adoção desses padrões um diferencial competitivo para empresas brasileiras que buscam estabilidade e escalabilidade em suas workloads de IA.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
