A Microsoft anunciou a disponibilização geral (GA) do recurso de cascading read replicas no Azure Database for PostgreSQL. Para empresas brasileiras que operam com sistemas de alta escala ou que possuem uma presença geográfica dispersa, esta é uma atualização técnica importante na camada de persistência de dados.
Tradicionalmente, a escalabilidade de leitura em bancos gerenciados era limitada à replicação direta do servidor primário. Com o modelo em cascata, é possível criar réplicas a partir de réplicas de leitura existentes, criando uma estrutura de replicação multinível. Na prática, isso permite que as equipes de engenharia desenhem topologias de rede mais granulares, atendendo a requisitos rígidos de latency para usuários em diferentes regiões, sem sobrecarregar a instância primária com o tráfego de replicação.
O que muda na arquitetura de dados
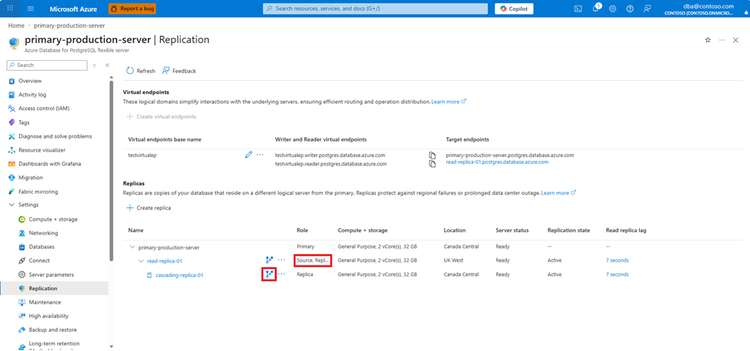
O grande diferencial das cascading read replicas é a capacidade de formar uma estrutura de "árvore" de replicação. O Azure suporta até dois níveis de replicação: o nível 1 engloba as réplicas diretas do primário, enquanto o nível 2 compreende as réplicas em cascata conectadas a essas.

Essa topologia oferece vantagens claras:
- Escalabilidade: É possível sustentar até 30 read replicas no total (5 conectadas ao primário e, cada uma, servindo como origem para mais 5).
- Distribuição Geográfica Eficiente: Reduz o bottleneck de I/O na instância primária e permite que as aplicações sirvam dados locais a usuários distantes com muito mais performance.
- Flexibilidade Operacional: Se for detectado um replication lag em um nó, é possível realizar uma operação de switchover, mantendo a disponibilidade e o SLA da aplicação.
Implementação na prática
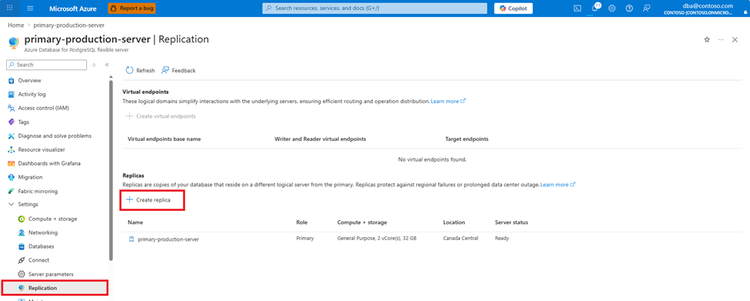
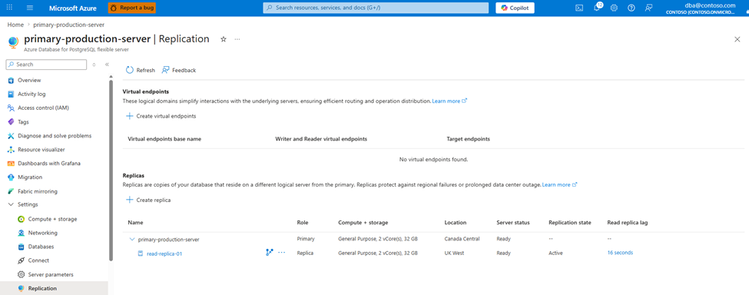
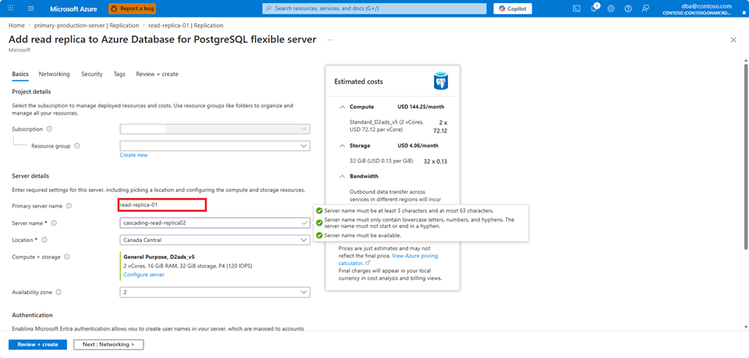
No Azure portal, a criação é simplificada via aba Replication. O processo é intuitivo, mas o valor real está no uso de Infrastructure as Code (IaC).
Para times que utilizam Terraform, a implementação exige referenciar a réplica existente como data source e apontá-la como create_source_server_id na criação do novo server:
data "azurerm_postgresql_flexible_server" "source_replica" {
name = "my-read-replica-1"
resource_group_name = "my-resource-group"
}
resource "azurerm_postgresql_flexible_server" "cascading_replica" {
# ... (configurações da instância)
create_mode = "Replica"
create_source_server_id = data.azurerm_postgresql_flexible_server.source_replica.id
# ...
}
Pontos de atenção
Antes de aplicar essa arquitetura, considere:
- Versionamento: Requer PostgreSQL versão 14 ou superior.
- Limitações operacionais: A operação de promote não é suportada para réplicas intermediárias (aquelas que servem como fonte em cascata). Isso impacta diretamente o seu Disaster Recovery.
- Custo e Complexidade: Multiplicar instâncias aumenta a superfície de monitoramento. Garanta que suas ferramentas de observability cubram a saúde dessa nova topologia.
Artigo originalmente publicado em Azure Updates.