

O recente anúncio da interoperabilidade entre o BigQuery e o ecossistema Apache Iceberg sinaliza uma mudança importante na forma como empresas estão estruturando seus Data Lakehouses. A capacidade de realizar operações de leitura e escrita em tabelas Iceberg — utilizando o catálogo gerenciado pelo Google Cloud — via diferentes engines como Spark, Trino ou Flink, ataca uma das maiores dores da engenharia de dados atual: o trade-off entre ser agnóstico a tecnologias e garantir performance de alta escala.
Para o gestor de TI ou arquiteto no Brasil, a principal provocação não é apenas a funcionalidade técnica, mas o custo operacional. Historicamente, manter um Lakehouse em formato aberto trazia um overhead de gerenciamento e um custo de performance significativos. Ao trazer a inteligência do BigQuery e do BigLake para tabelas Iceberg, o Google Cloud tenta simplificar essa equação, permitindo que a infraestrutura de armazenamento e metadados seja utilizada de forma integrada, reduzindo a necessidade de pipelines de replicação customizados e complexos.
Essa movimentação permite que times de engenharia utilizem o BigQuery como uma camada de aceleração e governança sobre tabelas que permanecem no formato Iceberg. Isso é crítico para cenários onde a interoperabilidade é mandatória, como em empresas que operam em ambiente multi-cloud ou que possuem times de ciência de dados heavy-users de Spark, mas que precisam da agilidade do SQL do BigQuery para BI e analytics avançado.
Ganho de eficiência (price-performance) para engenharia
A desmistificação de que "formatos abertos são lentos" começa com a automação. O fato de o BigLake passar a gerenciar tarefas de background como compaction e garbage collection diretamente em tabelas Iceberg é um divisor de águas. Engenheiros de dados deixam de gastar ciclos de desenvolvimento criando scripts de manutenção de tabela para focar em modelos de dados.
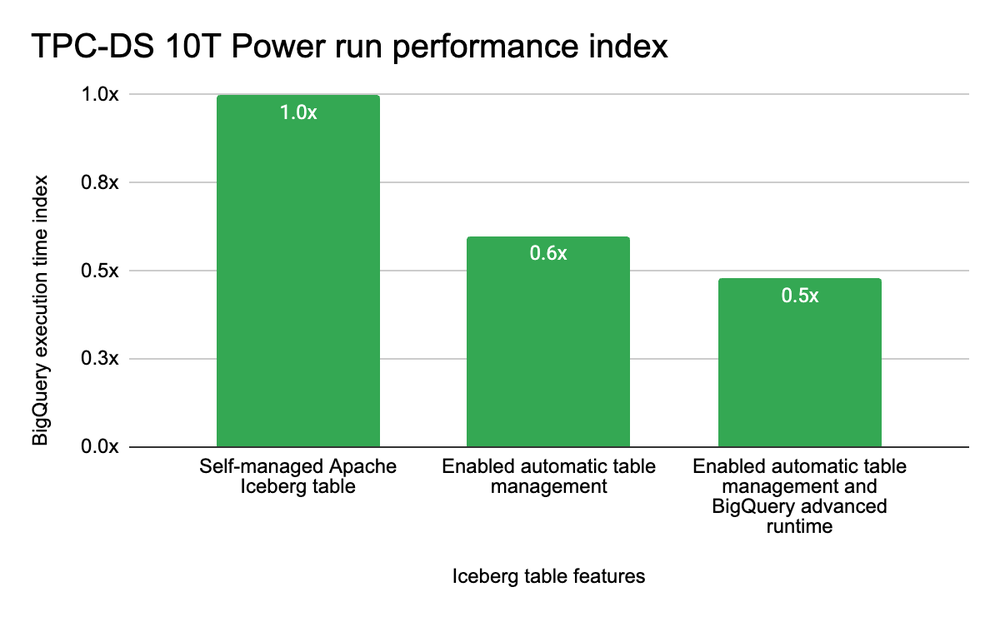
Além disso, o uso do advanced runtime do BigQuery em tabelas Iceberg promete ganhos de performance via vetorização. Para empresas brasileiras que precisam processar grandes volumes de dados (TPC-DS 10T, como referência) e otimizar custos de consumo em instâncias sob demanda ou slots, isso pode representar uma redução direta no OPEX.
Analytics avançado e dados em tempo real
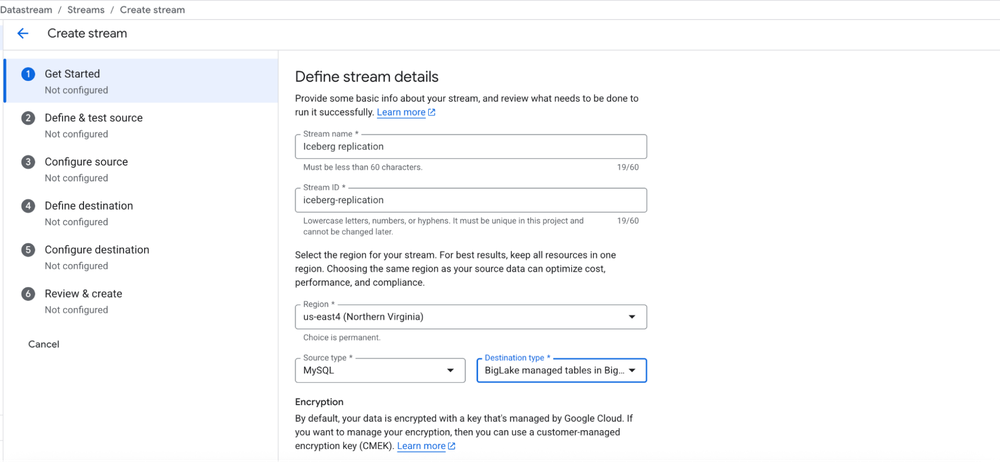
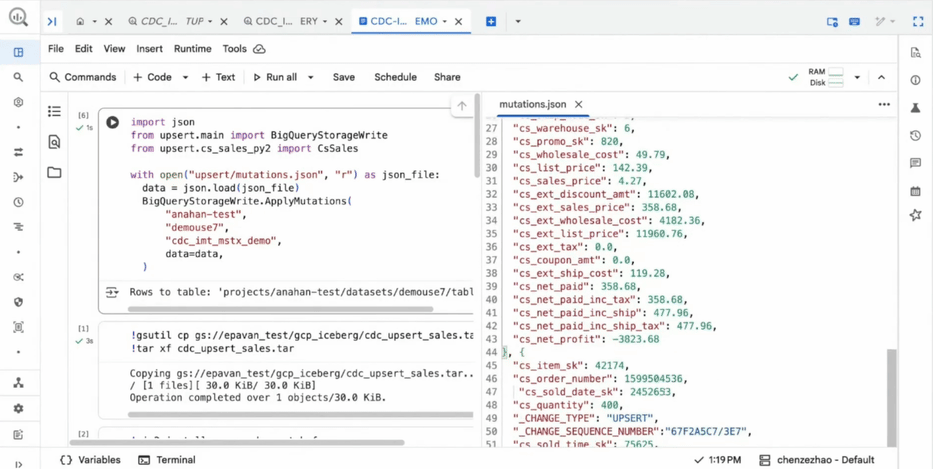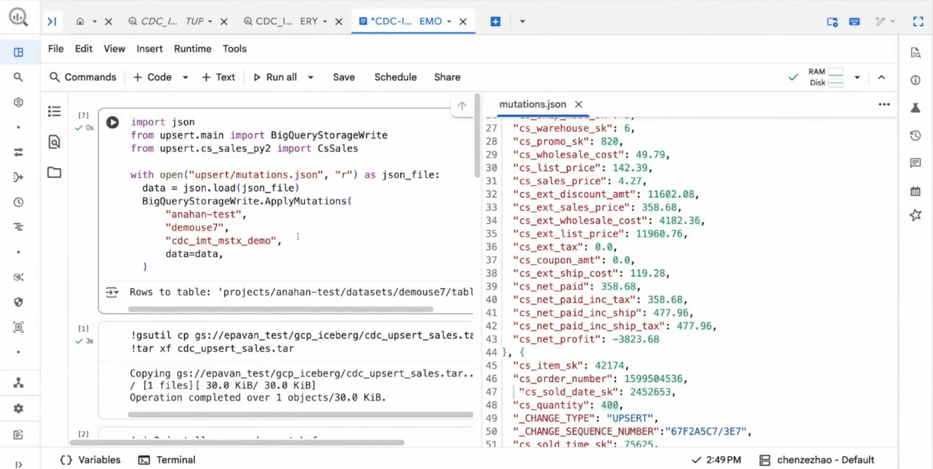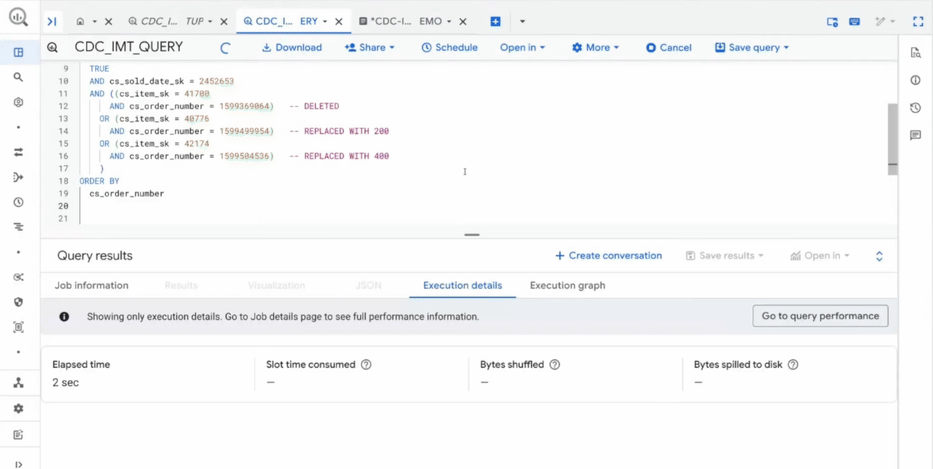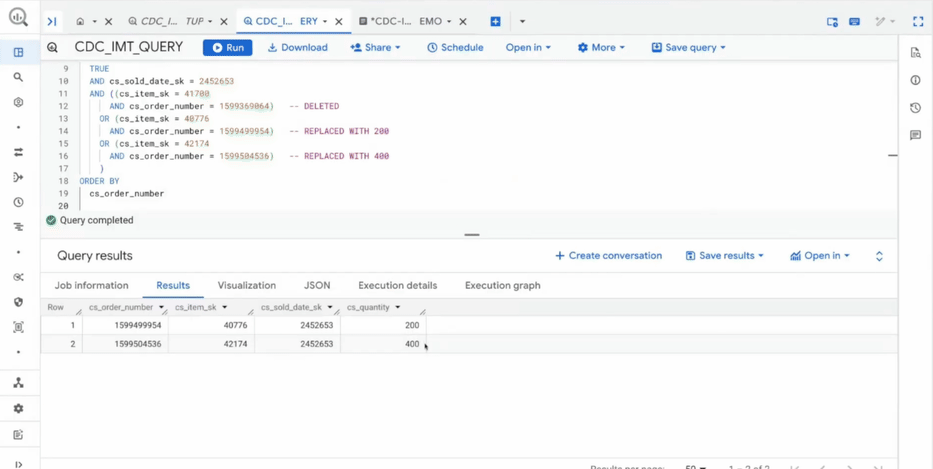
A integração de Change Data Capture (CDC) e o uso da infraestrutura Vortex para streaming trazem o Lakehouse para um patamar de frescor de dados muito superior ao que era possível com processos de batch tradicionais. A capacidade de realizar multi-statement transactions traz a robustez de um RDBMS para o mundo do Data Lake.
Considerações estratégicas
- Governance: O suporte a credential vending através do catálogo REST simplifica o IAM em um cenário multi-engine.
- Vendor Lock-in mitigation: O uso do formato Iceberg mantém a portabilidade dos dados. Você não está preso ao BigQuery para ler seus arquivos, embora ganhe muito em performance ao utilizá-lo como engine principal.
- Alerta de maturidade: Como estas funcionalidades estão entrando em fase de preview, recomendamos testes em cargas de trabalho de desenvolvimento antes de migrar pipelines de alta carga crítica (SLA elevado).
Artigo originalmente publicado por Angela Soares, Senior Product Marketing Manager em Cloud Blog.
