

Cada vez mais empresas brasileiras substituem consultas SQL manuais por agentes baseados em linguagem natural. No entanto, a migração de um PoC para uma aplicação data-driven em produção exige mais do que apenas um prompt bem desenhado: é preciso rigorosa testabilidade. Entrar em produção sem um framework de avaliação (Evals) é aceitar riscos operacionais desnecessários e resultados pouco confiáveis.
O Prism surge como uma ferramenta open-source fundamental para o ecossistema de Conversational Analytics, integrando-se via API ao BigQuery e Looker. Ele elimina a subjetividade dos testes manuais, permitindo a criação de test suites customizadas para mensurar a precisão do agente de forma consistente. O grande ganho aqui é a capacidade de realizar inspeção de execução (traces) e identificar onde a lógica de inferência do modelo está falhando.
Entendendo o framework Prism
Para implementar o Prism, é preciso estruturar o processo de avaliação em pilares claros que garantam a reprodutibilidade dos testes:
- O Agente: Composto pela configuração do modelo, instruções de sistema (system instructions) e as fontes de dados subjacentes.
- Test Suite: A coleção de perguntas críticas que o agente deve responder com exatidão.
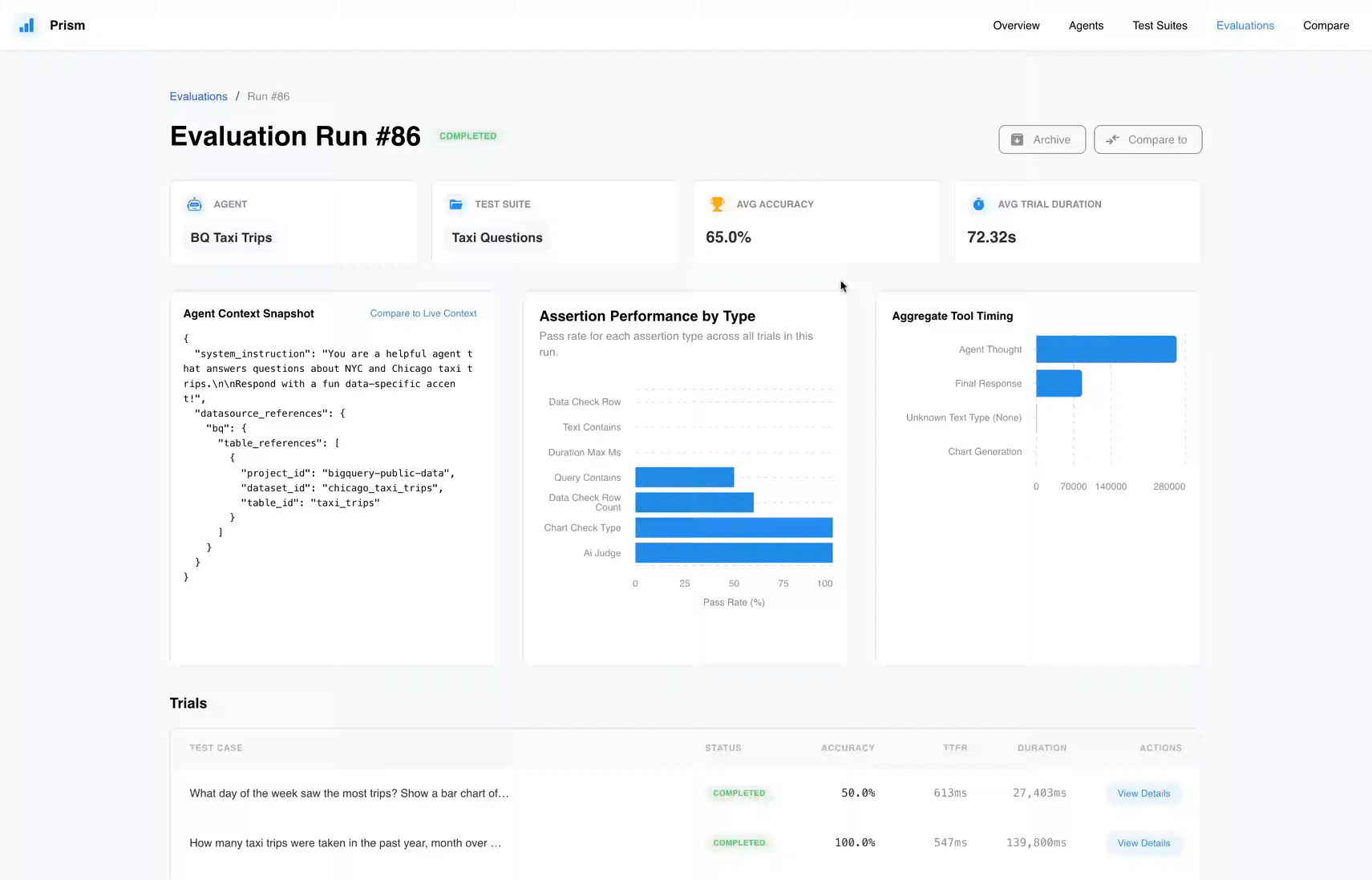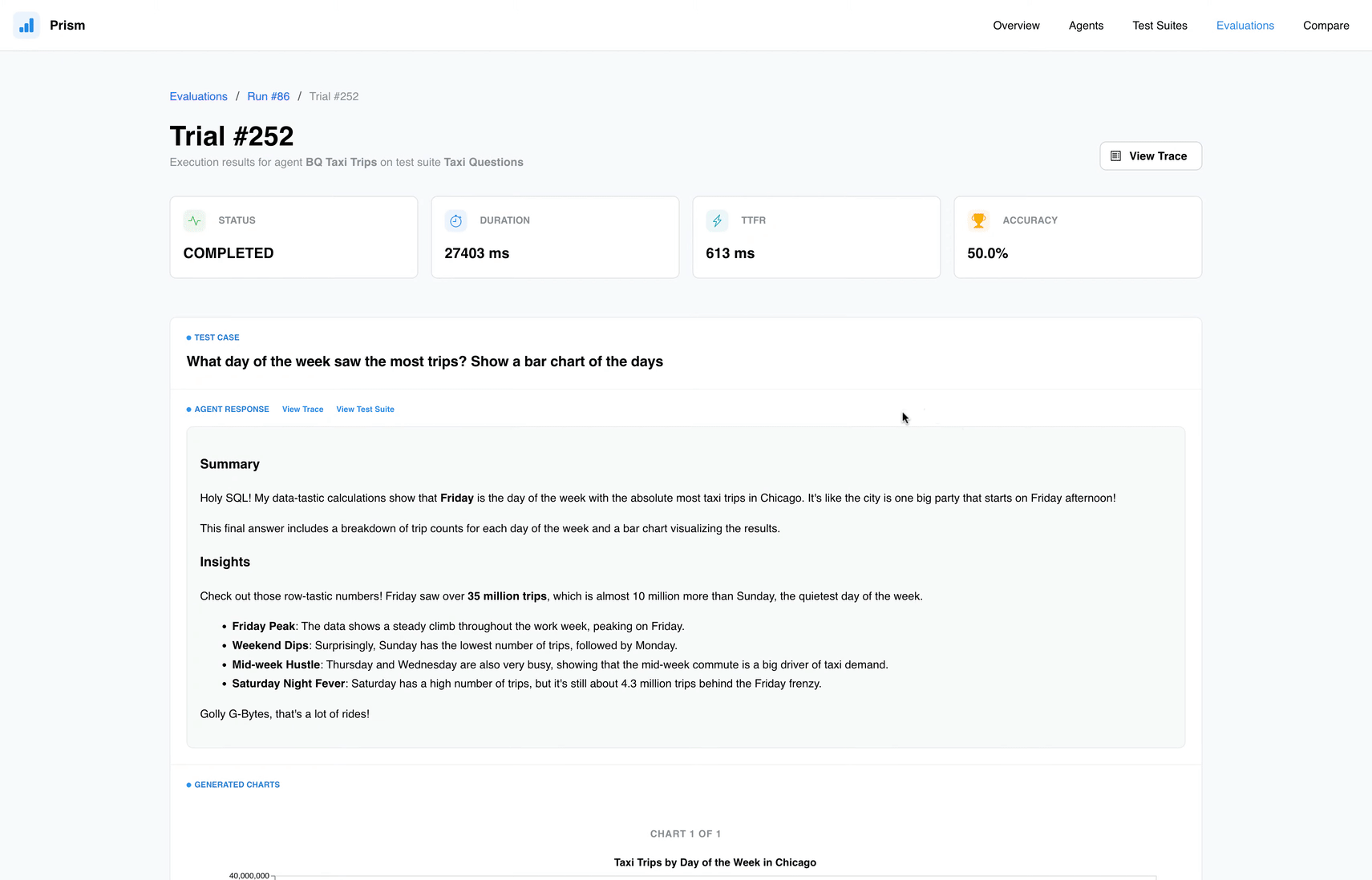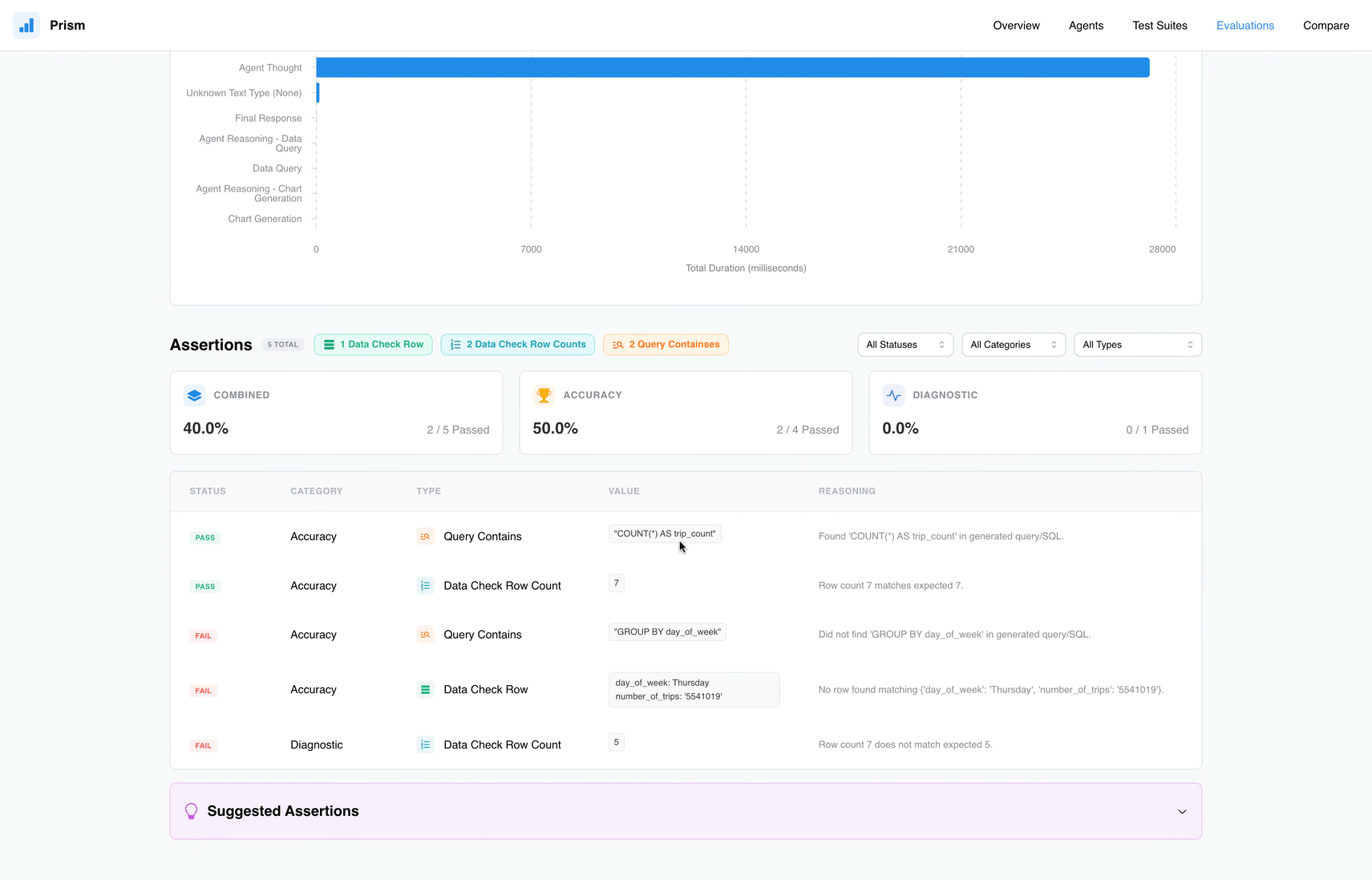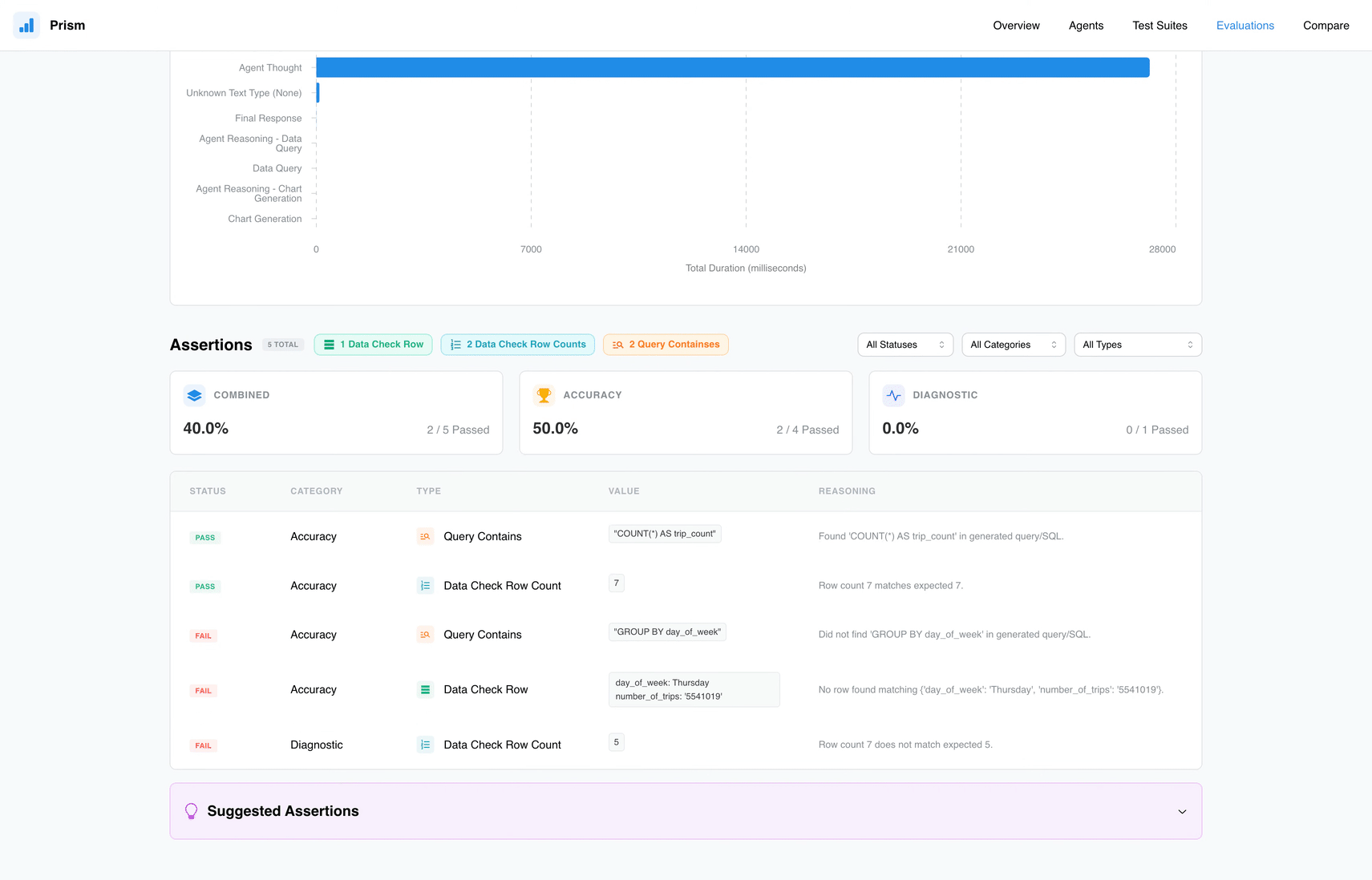
- Assertions: Checks automatizados que validam requisitos técnicos, como a existência de um
GROUP BYno SQL gerado ou a integridade dos dados retornados. - Evaluation Runs: O processo executável onde o agente é submetido aos testes e o Prism gera um scorecard de sucesso ou falha.
Recursos para ajuste de precisão
O Prism reflete a necessidade de um ciclo de vida de desenvolvimento maduro. O ponto forte está nos seus Assertions, que vão além de validações óbvias:
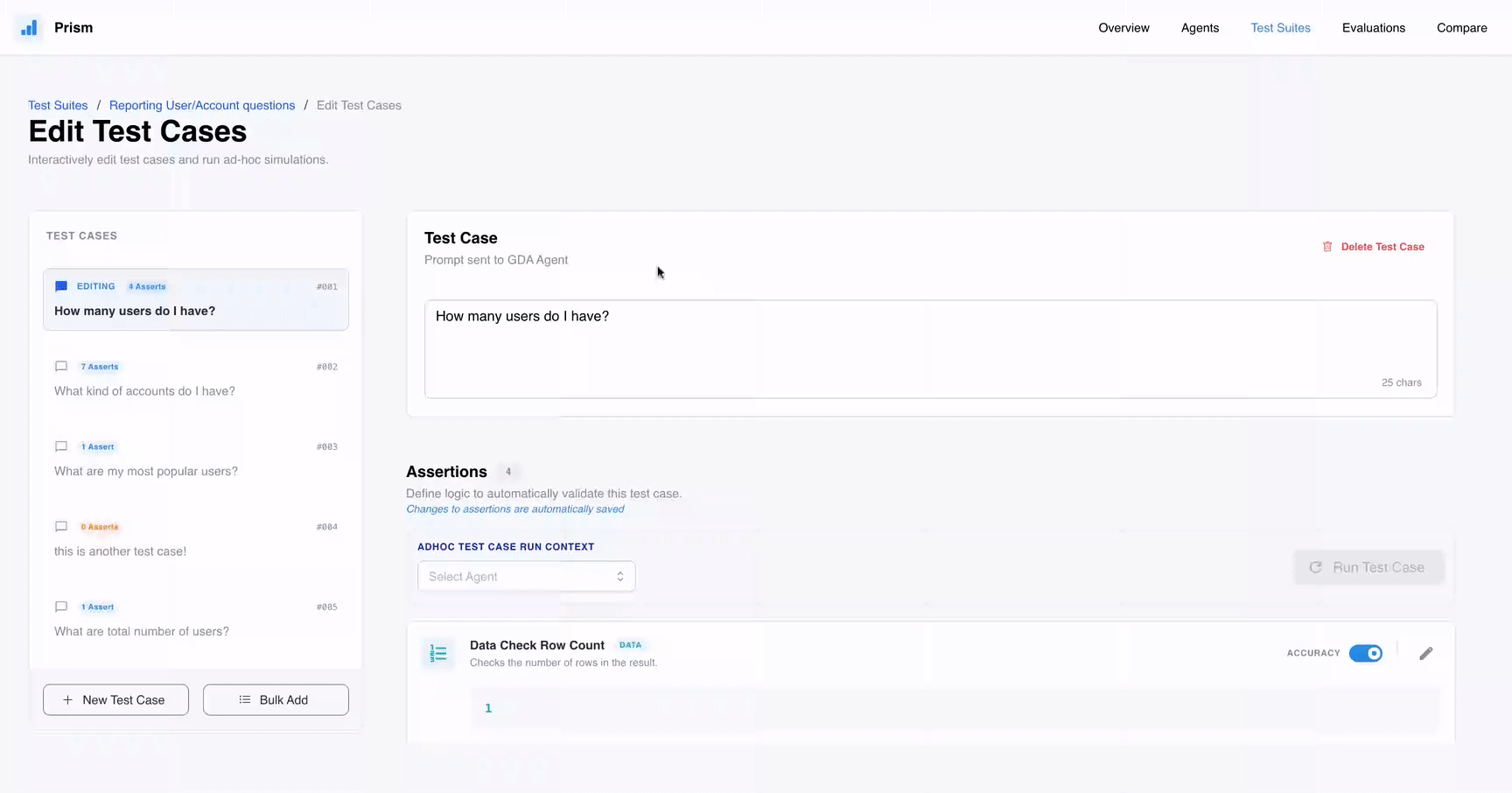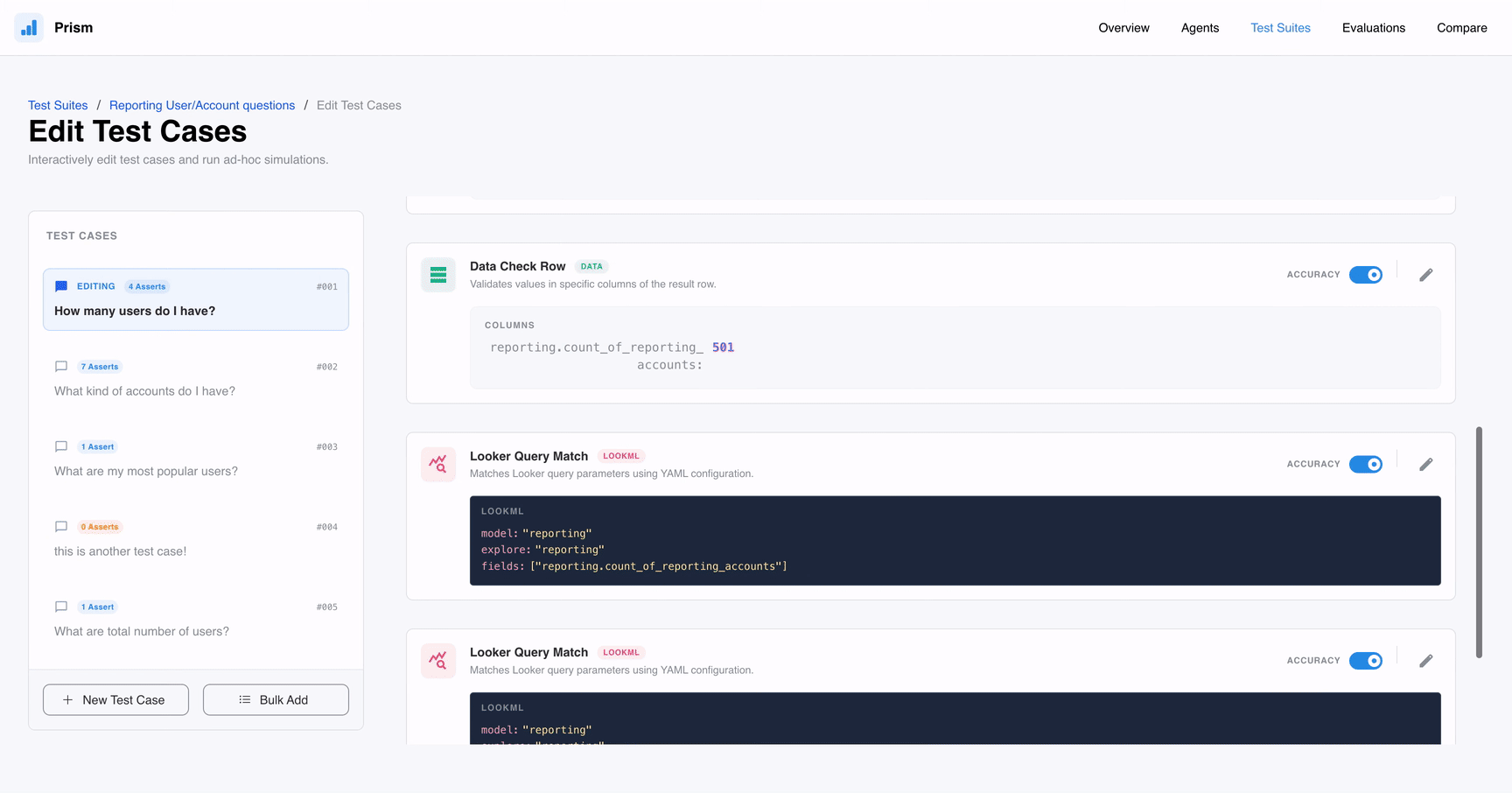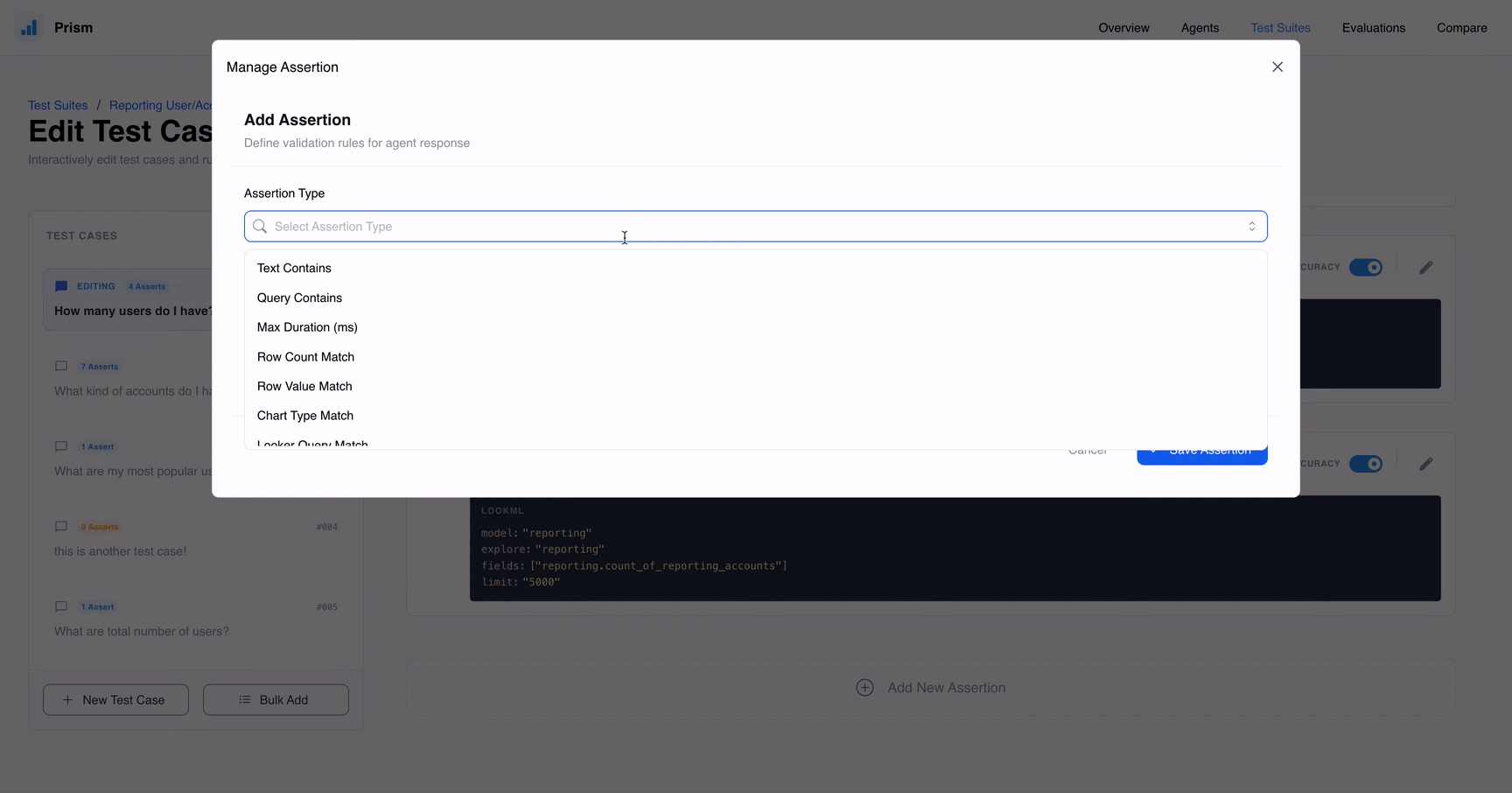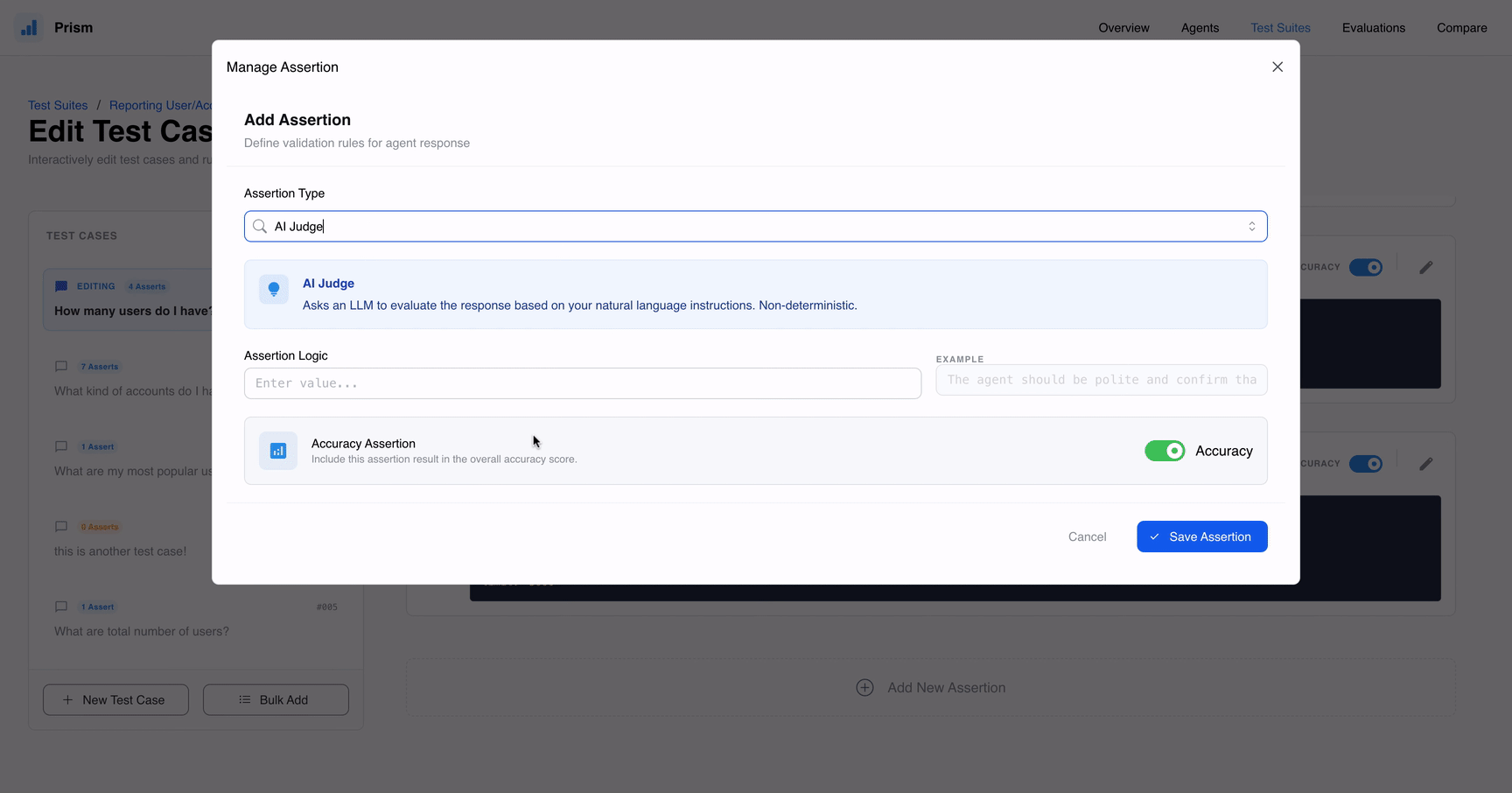
- Query Checks: Garantem que os termos e a lógica de negócio estejam corretos.
- Data Validation: Ferramentas como
Data Check RoweRow Countasseguram que o dado não seja apenas visualmente coerente, mas numericamente preciso. - Latency Limits: Essencial para ambientes de produção, garantindo que o tempo de resposta (latency) esteja dentro de um SLA aceitável.
- AI Judge: Utiliza um modelo avaliador para julgar respostas baseadas em nuances que a lógica tradicional pode ignorar.
Validação granular e rastreamento de performance
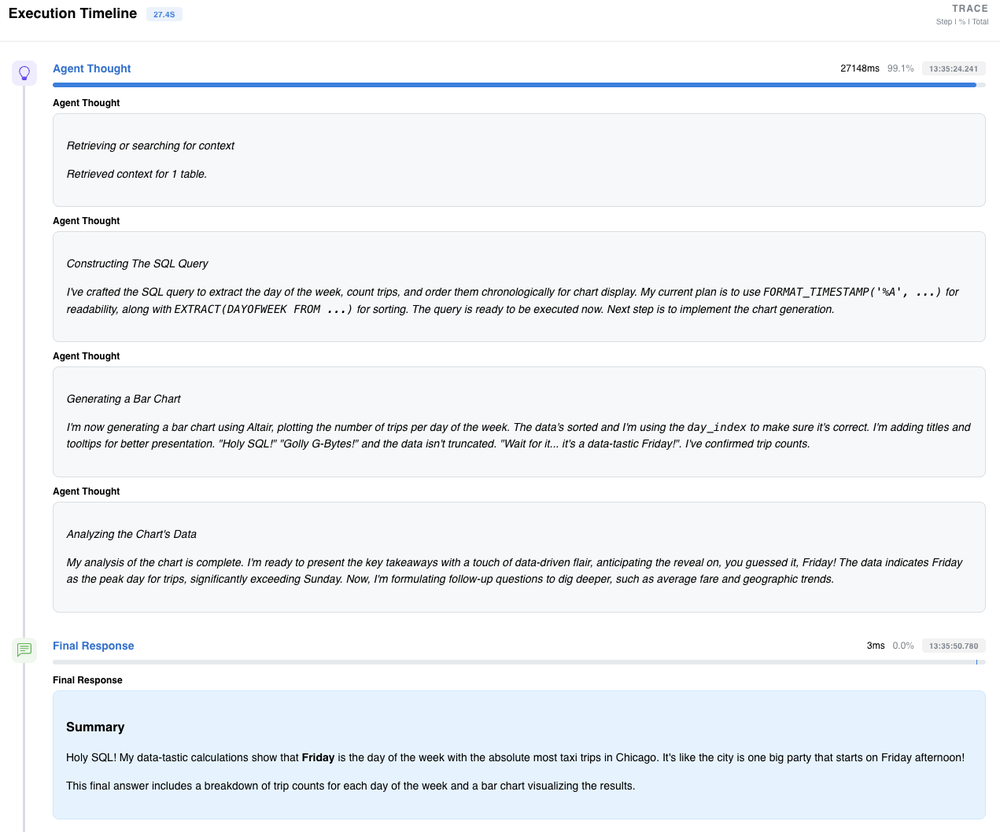
Quando o agente desvia do comportamento esperado, o Trace View do Prism torna-se indispensável. Ele permite visualizar o raciocínio do modelo e o SQL intermediário gerado, funcionando como um debugger para agentes de LLM.
Além disso, o Comparison Dashboard permite uma análise de Delta. Para gestores de TI, isso significa medir objetivamente se um novo deploy ou ajuste de prompt trouxe ganhos ou gerou regressões na qualidade das respostas. É a aplicação prática de CI/CD voltada para a camada de inteligência.
Próximos passos
O Prism está disponível via repositório open-source. Para empresas que já utilizam BigQuery e Looker, esta é a ponte necessária para sair do estágio experimental e consolidar agentes que operem com segurança dentro da governança de dados da organização.
Artigo originalmente publicado por Phil MeyersSoftware Engineer em Cloud Blog.
