

TL;DR: Infraestrutura estatal não precisa ser refém de licença nem de nuvem. Detalhamos como o IBICT ganhou um cluster Kubernetes de produção 100% open source sobre Proxmox e Ceph: o cluster inteiro gerido como código via pipeline GitLab, observabilidade multi-cluster, identidade federada com Keycloak e self-service em Backstage. O diferencial não é só a stack — é tê-la entregado documentada e pronta para a equipe interna (e agentes de IA) sustentarem, sem lock-in.
Quando se fala em Kubernetes no setor público brasileiro, a imagem mental mais comum envolve um contrato com um hyperscaler, uma fatura em dólar e uma dependência que cresce a cada serviço gerenciado consumido. O IBICT (Instituto Brasileiro de Informação em Ciência e Tecnologia) foi na direção oposta: montar tudo em casa, com software livre, sobre a infraestrutura que já existia.
O resultado é um cluster Kubernetes de produção rodando sobre Proxmox VE e Ceph hyperconvergente, com Talos Linux como sistema operacional imutável, GitLab CE auto-hospedado como centro de GitOps, e um stack completo de observabilidade, identidade, backup e self-service. Nenhum componente proprietário. Nenhuma licença por core. E, principalmente, nenhum acoplamento que impeça o IBICT de mudar de direção amanhã.
Este artigo é o detalhamento técnico dessa jornada: as decisões de arquitetura, os trade-offs, os desafios que superamos e — o que mais nos orgulha — como entregamos um ambiente complexo de forma que a equipe interna consiga sustentá-lo. Não é um tutorial; é um mapa de engenharia para quem está considerando o mesmo caminho.
Contexto: o trabalho descrito aqui foi realizado pela Nuvem Online para o IBICT entre abril e junho de 2026, sobre infraestrutura Proxmox/Ceph pré-existente gerenciada pela equipe de infraestrutura do instituto. Por se tratar de um órgão público, este texto descreve arquitetura e decisões — sem expor endereços, versões ou identificadores internos.
Por que uma instituição de pesquisa montaria tudo em casa?
O IBICT é a unidade de pesquisa do MCTI responsável por organizar, preservar e dar acesso à informação científica e tecnológica do país. Sob sua guarda estão acervos que são patrimônio da ciência brasileira: o Catálogo Coletivo Nacional (CCN), a base Bibliodata, o COMUT, o Pinakes e dezenas de sistemas de biblioteconomia, repositórios e portais mantidos por diferentes coordenações e pelos próprios pesquisadores.
Esse é o primeiro fato que molda a arquitetura: não é uma carga de trabalho, são dezenas. Cada projeto de pesquisa, cada sistema de uma coordenação, cada repositório institucional é uma aplicação com ciclo de vida próprio — e todas competem pelo mesmo orçamento público, que é finito e auditado. Multiplicar isso por contratos de nuvem pública, faturados em dólar e por serviço gerenciado consumido, é uma conta que não fecha para quem precisa entregar muito com pouco.
O segundo fato é o que de fato decide a direção: a informação científica sob a guarda do IBICT é propriedade intelectual acadêmica e patrimônio público. Hospedá-la em infraestrutura fora do controle total do instituto — onde os termos de uso, a jurisdição do dado e a continuidade do serviço pertencem a um terceiro — é abrir mão de soberania sobre o próprio acervo. Para um órgão cuja missão é preservar e dar acesso a esse conhecimento, isso não é detalhe operacional: é risco institucional.
A soma dos três vetores — muitos projetos, orçamento finito e soberania inegociável — converge para uma única resposta de engenharia: uma plataforma própria, multi-tenant, sobre software livre, que entregue a experiência de uma nuvem pública sem nenhuma das suas amarras. O custo marginal de mais um projeto precisa tender a zero — um namespace, não um novo contrato — e o custo de saída de qualquer componente precisa ser, também, zero.
O ponto de partida concreto foi trazer o código para dentro de casa. Antes do cluster, parte do versionamento ainda vivia num GitLab de 2021. A primeira entrega foi consolidar um GitLab CE atual, self-hosted, e migrar 22 projetos do acervo bibliográfico — grupo raiz, seis subgrupos, todo o histórico de issues, commits, tags e merge requests — sem perder nada no caminho. Dali, a plataforma cresceu para o que este artigo detalha.
A plataforma em camadas
Antes de descer aos detalhes, o mapa. Tudo o que numa nuvem pública seria um serviço gerenciado e faturado, aqui é um componente open source rodando no próprio datacenter — empilhado em cinco camadas, da virtualização ao self-service:
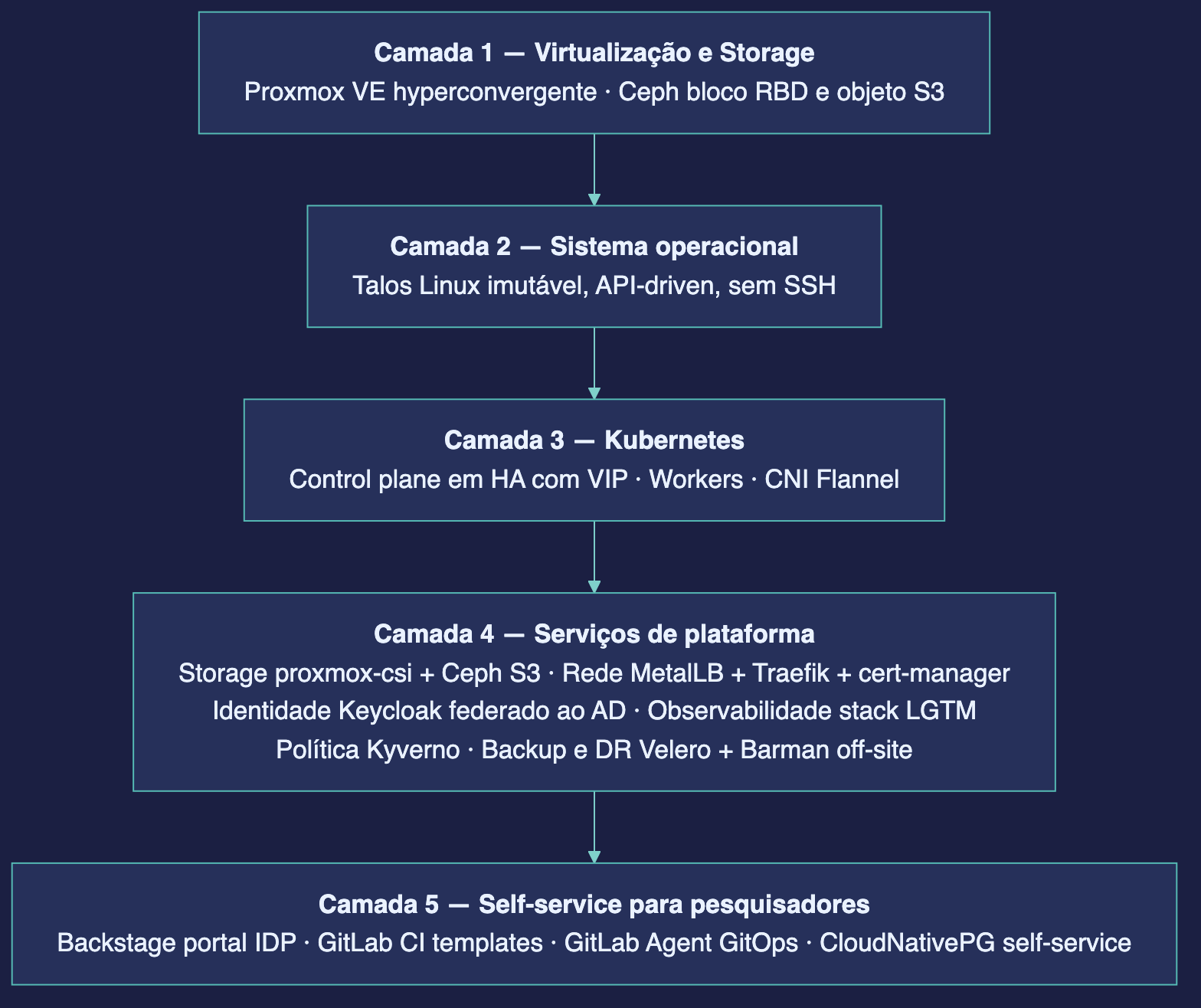
Cada camada é detalhada a seguir. A lógica que as une é sempre a mesma: preferir o componente de comunidade ao produto de fornecedor, manter o dado dentro de casa e garantir que nada prenda o instituto a uma escolha.
Como o Talos Linux muda o jogo da operação on-premises?
O primeiro degrau da stack é o sistema operacional dos nodes. Em vez de um Ubuntu Server ou RHEL com kubeadm, escolhemos o Talos Linux.
Talos é um sistema operacional imutável, minimalista e feito exclusivamente para rodar Kubernetes. Sem SSH, sem gerenciador de pacotes, sem sistema de init genérico — a API do Talos substitui tudo isso. A configuração é declarativa (machine config), o upgrade é atômico (nova imagem de disco, reboot), e a superfície de ataque é drasticamente menor que a de uma distro de propósito geral.
O cluster de produção roda control planes em alta disponibilidade (quórum de etcd, com VIP embutido e sem load balancer externo) e um pool de workers, numa rede de produção isolada. A CNI padrão é Flannel, nativa do Talos — suficiente para um cluster on-premises sem requisitos complexos de network policy no momento.
| Característica | Talos Linux | Distro tradicional (Ubuntu + kubeadm) |
|---|---|---|
| Superfície de ataque | Mínima (sem SSH, sem shell) | Ampla (SSH, systemd, pacotes) |
| Drift de configuração | Impossível (imutável) | Comum (atualizações manuais, pacotes) |
| Upgrade de OS | talosctl upgrade + reboot atômico |
apt upgrade + reinicialização tradicional |
| API de gerenciamento | gRPC nativa (talosctl) | SSH + scripts |
| Curva de aprendizado | Média (paradigma novo) | Baixa (familiaridade Unix) |
E se gerir o cluster inteiro fosse um git push?
A vantagem de uma nuvem pública não é só o catálogo de serviços — é a forma de operar: você descreve o que quer e a plataforma materializa. Trouxemos exatamente isso para dentro do datacenter. Todo o ciclo de vida do cluster é código.
Não existe um servidor onde alguém "instalou o Kubernetes". Existe um repositório de infraestrutura: uma alteração entra por git push, dispara uma pipeline no GitLab, e o Terraform/OpenTofu planeja e aplica a mudança — criando ou atualizando as VMs Talos no Proxmox, fazendo o bootstrap do cluster e instalando a CNI, tudo num fluxo único e sem passo manual. O estado fica guardado de forma central (não na máquina de um engenheiro) e os segredos vêm sempre da pipeline, nunca do repositório.
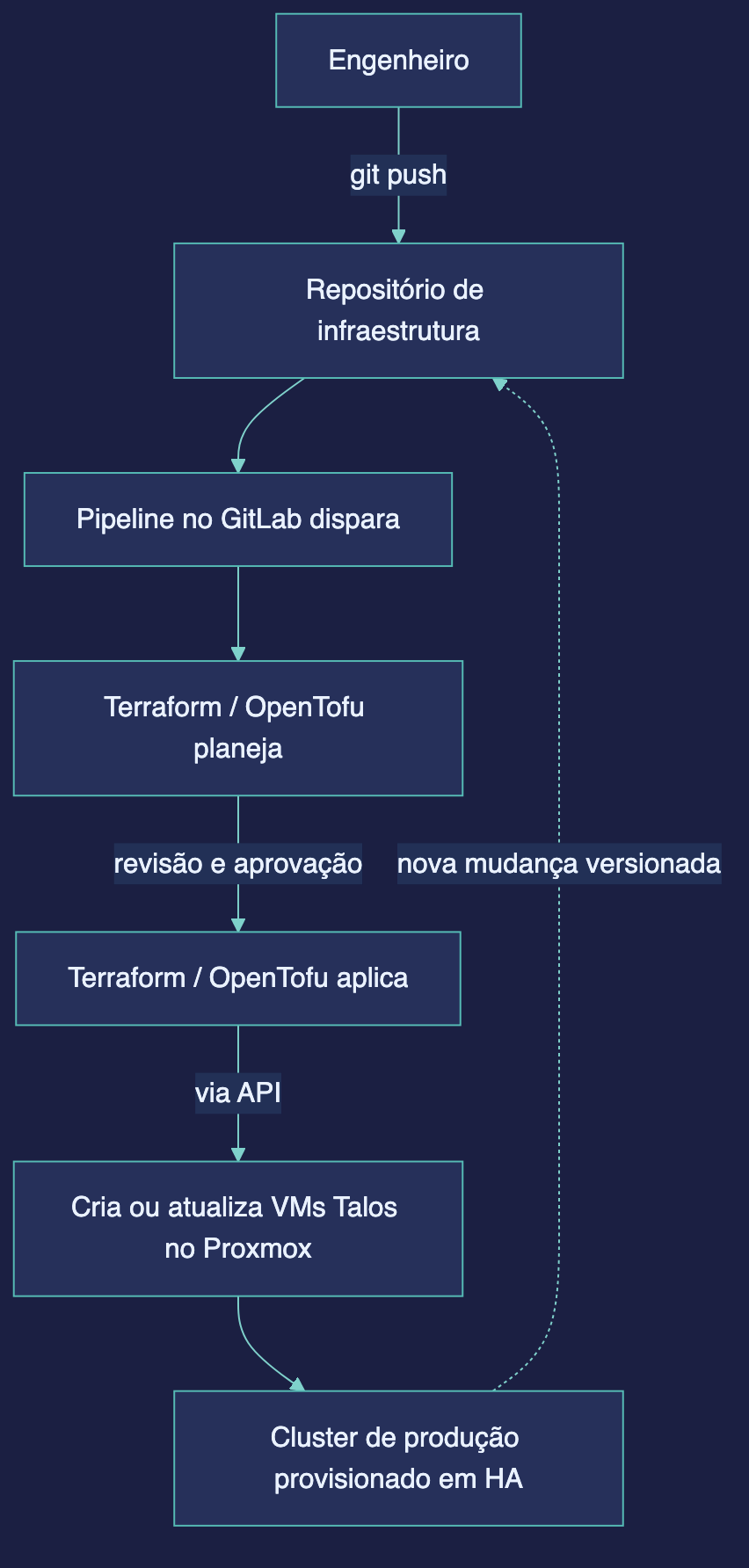
O efeito é que escalar ou alterar o cluster tem a mesma ergonomia de provisionar numa nuvem pública — com uma diferença: o plano é revisável, a mudança é auditável e nada disso depende de um provedor externo. Adicionar um pool de workers é editar um arquivo de variáveis e abrir um merge request. Subir o cluster do zero é um comando.
Por que o proxmox-csi-plugin, e não o ceph-csi direto?
O cluster Proxmox do IBICT é hyperconvergente: os mesmos hosts rodam VMs e fornecem storage via Ceph (RBD + CephFS). O caminho natural seria usar o ceph-csi para que cada pod falasse diretamente com os monitors Ceph. Mas há um bloqueio arquitetônico:
A rede pública do Ceph é isolada da rede dos workers Kubernetes. É uma decisão de segurança padrão em ambientes Proxmox hyperconvergentes — e incompatível com o modelo do ceph-csi, onde cada pod abre conexão TCP própria com os monitors.
Depois de avaliar cinco alternativas (liberar a rota entre as redes, segunda NIC nos workers, VM router dedicada, Rook-Ceph separado), a decisão foi adotar o proxmox-csi-plugin como solução provisória:
| Alternativa | Mantém ceph-csi | RWX | Complexidade | Bloqueio |
|---|---|---|---|---|
| Liberar rota entre as redes | ✅ | ✅ | Baixa | Depende do time de redes |
| 2ª NIC + DHCP na rede Ceph | ✅ | ✅ | Média | DHCP + roteamento extra |
| VM router dedicada | ✅ | ✅ | Alta | SPOF |
| proxmox-csi-plugin | ❌ | ❌ (só RWO) | Baixa | Nenhum |
| Rook-Ceph dedicado | n/a | ✅ | Muito alta | Dobra de Ceph |
O proxmox-csi-plugin não fala com o Ceph — fala com a API do Proxmox, já acessível dos workers. O host Proxmox cria o disco RBD e o expõe como virtio para a VM Talos, exatamente como o disco principal. O I/O do volume vai direto pelo virtio (host → RBD), sem hop extra no caminho de dados — o hop adicional está só no provisionamento.
Trade-off conhecido: sem
ReadWriteMany(CephFS). Workloads que precisam de volumes compartilhados entre pods ficam pendentes. O plano de reativação do ceph-csi — quando a rota entre as redes for liberada — está documentado e os manifests já estão prontos.
O proxmox-cloud-controller-manager complementa o CSI: é ele quem remove o taint node.cloudprovider.kubernetes.io/uninitialized (sem o qual nenhum pod agenda) e aplica os labels de topologia que o CSI usa para reconciliar os volumes. Disso resultam três classes de storage, mapeadas aos pools Ceph por desempenho: SSD (padrão), SATA e HDD para dados frios.
Como o storage de objeto (S3) destravou a observabilidade?
O stack de observabilidade — Loki (logs), Mimir (métricas) e Tempo (traces) — depende de object storage compatível com S3 para operar em modo distribuído e com alta disponibilidade. Sem S3, ficamos limitados a single-replica com filesystem em PVC.
A solução veio do próprio Ceph: o RADOS Gateway (RGW) foi ativado nos hosts Proxmox, expondo uma API S3 compatível no domínio institucional. Em vez de subir um MinIO ou SeaweedFS dentro do Kubernetes — o que seria dupla virtualização sobre PVCs que já estão sobre RBD — o RGW é nativo do Ceph e consome recursos dos próprios hosts Proxmox, não dos workers.
O truque de integração: Services sem seletor + EndpointSlice manual. Os daemons RGW rodam nos próprios hosts Proxmox, fora do Kubernetes. Criamos Services ClusterIP que apontam para esses endpoints externos via EndpointSlice, e o Traefik termina o TLS (cert-manager + Let's Encrypt) e roteia por Host:
cliente → HTTPS → Traefik (termina TLS) → Service ClusterIP (sem seletor) → EndpointSlice manual → RGW nos hosts Proxmox
Com S3 no ar, a migração foi executada — e transparente para os consumidores: os Services internos de escrita e de leitura não mudaram de nome, e o header de tenant permaneceu idêntico. Alloy e Grafana não foram tocados.
| Componente | Antes (sem S3) | Depois (com S3) |
|---|---|---|
| Loki | SingleBinary, 1 réplica, filesystem em PVC | SimpleScalable + S3, com write/read/backend/gateway replicados |
| Mimir | Manifests próprios, monolithic, filesystem em PVC | chart distribuído + S3, HA zone-aware |
| Tempo | Não implantado | Planejado — chart distribuído + bucket S3 |
Como funciona a observabilidade multi-cluster?
O modelo adotado é backends centralizados + satélites leves, inspirado no padrão LGTM (Loki, Grafana, Tempo, Mimir):
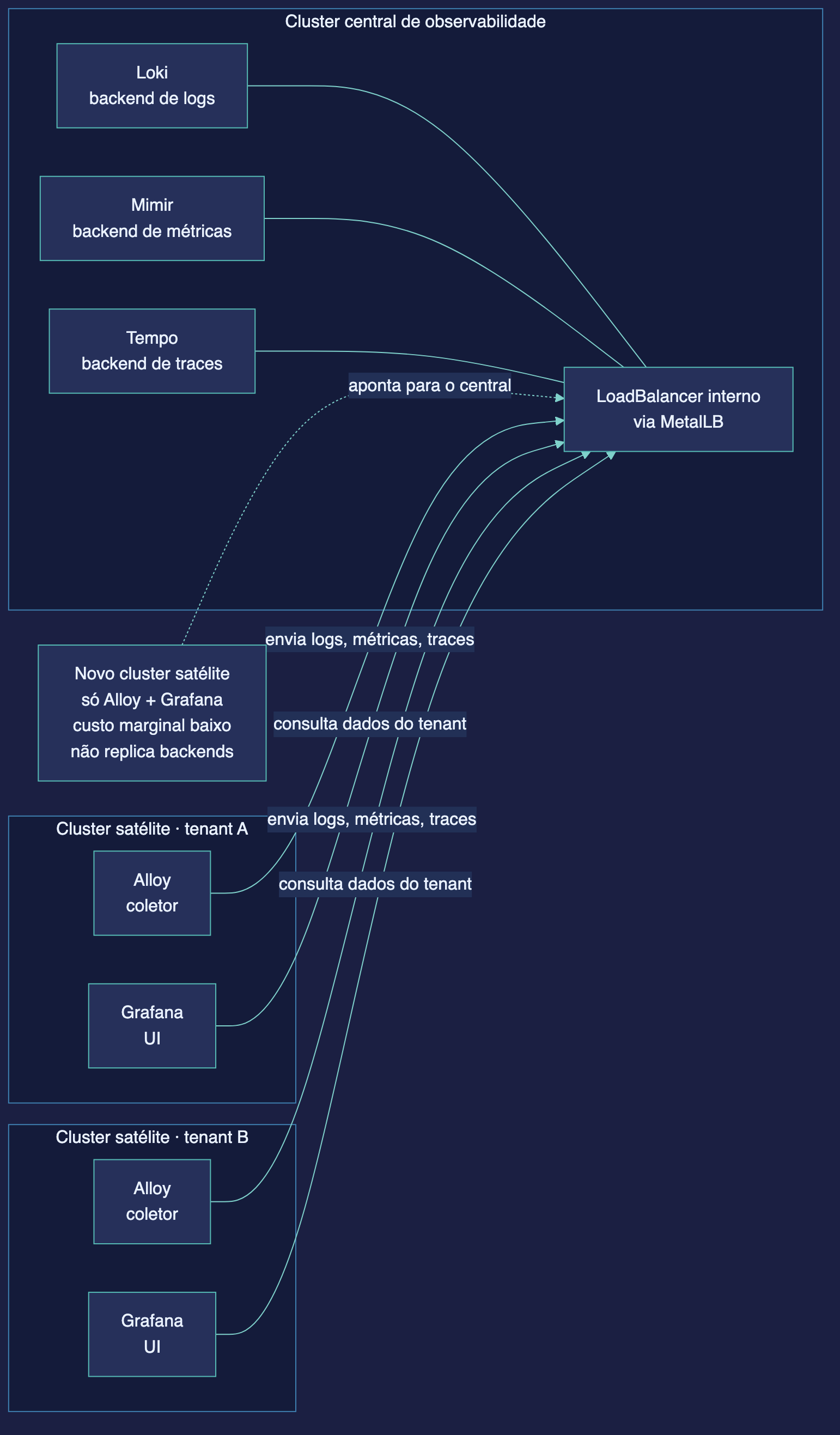
Um cluster novo não sobe Loki, Mimir nem Tempo. Só entram Alloy (coletor) e Grafana (UI), que apontam para os backends centrais via LoadBalancer interno (MetalLB), marcando cada dado com o tenant = nome do cluster. O isolamento é nativo do multi-tenancy do Loki e do Mimir — nenhum dado de um cluster vaza para o Grafana de outro. O custo marginal de mais um cluster é baixo porque a parte cara e com estado fica concentrada e compartilhada.
O Alloy é o coletor unificado: recebe métricas (Prometheus remote write + OTLP), logs (Loki push + OTLP) e traces (OTLP), aplica transformações e encaminha para os backends. O chart grafana/k8s-monitoring provisiona tudo — ServiceMonitors, PodMonitors, regras do kubernetes-mixin e pipelines de telemetria — num único release Helm.
O Grafana não tem persistência: dashboards e datasources são ConfigMaps carregados por sidecar, versionados em Git. Mudanças permanentes são sempre via commit. O OAuth é contra o Keycloak institucional, e cada Grafana de satélite reutiliza o mesmo client OIDC — só acrescenta seu redirect URI.
Como o GitLab CE auto-hospedado se tornou o centro de GitOps?
O GitLab CE roda no próprio cluster, instalado via chart oficial gitlab/gitlab, com PostgreSQL externo no CloudNativePG, Valkey (cache/queue) em release próprio, e object storage no Ceph RGW. O tráfego SSH do Git é roteado pelo Traefik via IngressRouteTCP, compartilhando o mesmo VIP MetalLB da web. A autenticação é federada no Keycloak (via OmniAuth OIDC), com sincronização automática de admins a partir de um grupo do diretório.
O GitLab Agent for Kubernetes (agentk) conecta os clusters ao GitLab, permitindo que pipelines CI/CD façam deploy diretamente — sem distribuir kubeconfig nem abrir acesso à API do cluster. A configuração autoriza qualquer projeto da instância a usar os agentes, o que elimina fricção para novas aplicações.
Os templates de pipeline são compartilhados via include: project de um repositório central de templates — em vez de cada projeto reescrever a sua pipeline:
# .gitlab-ci.yml mínimo de qualquer aplicação
include:
- project: 'infra/templates'
file: '/build/docker-buildah.yml'
- project: 'infra/templates'
file: '/deploy/kubernetes-helm.yml'
variables:
DEPLOY_CLUSTER: "<cluster-alvo>"
DEPLOY_NAMESPACE: "<namespace>"
build:
extends: .docker-build
deploy:
extends: .deploy-helm
rules:
- if: $CI_COMMIT_BRANCH == "develop"
O build usa Buildah (sem Docker daemon privilegiado), o push vai para o container registry do próprio GitLab, e o deploy é helm upgrade --install com overlay por ambiente. Qualquer app que siga o layout esperado (Dockerfile + chart helm/ + kubernetes/<cluster>/<namespace>/values.yaml) ganha CI/CD completo sem escrever pipeline. Atualizar um template propaga a melhoria para todas as aplicações de uma vez.
Como o PostgreSQL virou self-service com CloudNativePG?
Bancos de dados são o ponto de atrito clássico entre times de desenvolvimento e infraestrutura. A resposta aqui foi o CloudNativePG (CNPG), um operator Kubernetes que gerencia clusters PostgreSQL de forma declarativa.
O cluster Postgres principal roda três instâncias (1 primary + 2 standbys com replicação síncrona), com anti-affinity por host Proxmox, atrás de PgBouncer (pool de conexões em modo transaction) e backup off-site diário em S3 via Barman Cloud Plugin (WAL contínuo + base backup, com recuperação a um ponto no tempo).
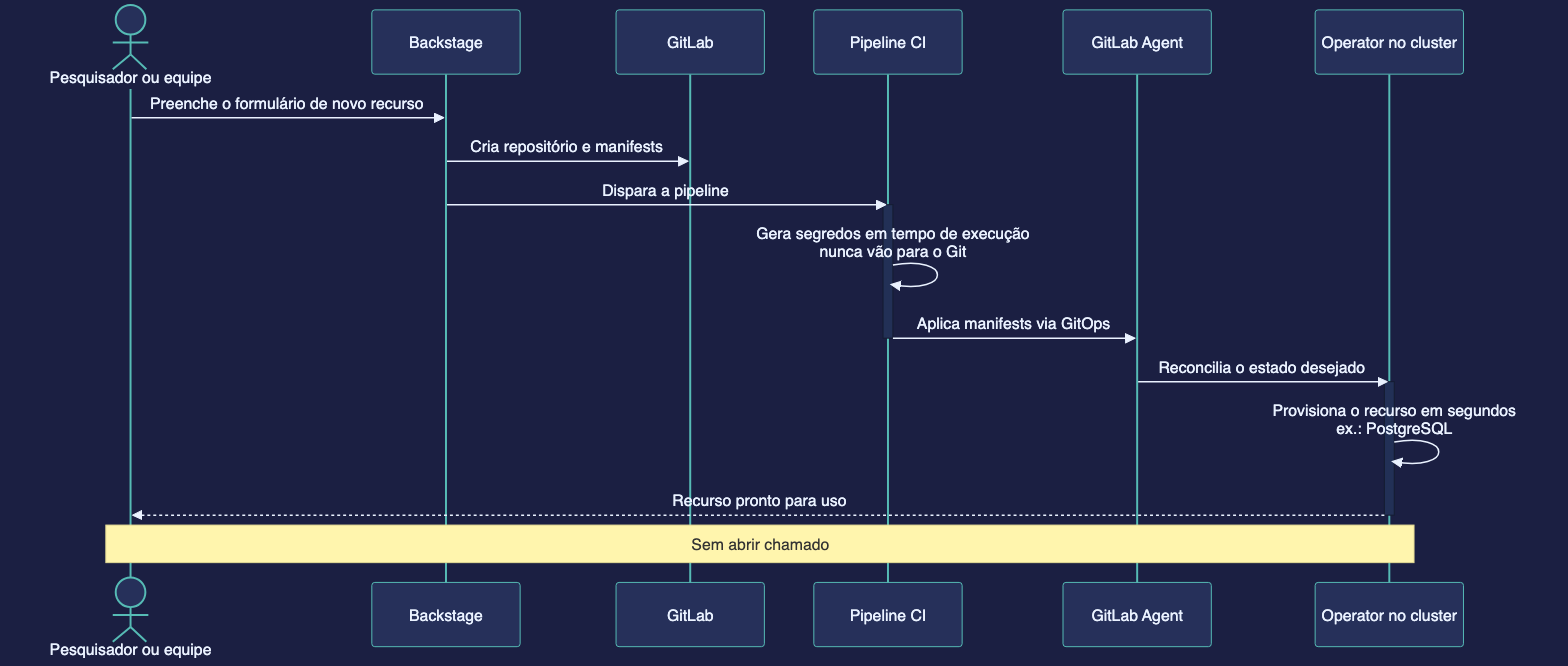
Mas a peça-chave não é o operador em si — é o Backstage Software Template que transformou o provisionamento de bancos em self-service:
# Uma equipe preenche o formulário e ganha um repositório assim:
<banco>/
├── kubernetes/
│ └── <cluster>/<namespace>/
│ ├── cluster.yaml # CNPG Cluster + managed.roles (fonte da verdade)
│ ├── databases.yaml # um Database CRD por banco solicitado
│ ├── objectstore.yaml # backup Barman em S3 (se habilitado)
│ └── scheduledbackup.yaml
├── .gitlab-ci.yml # pipeline que itera os manifests e aplica
└── README.md
O fluxo é autosserviço total:
- O desenvolvedor acessa o portal Backstage (rota
/create). - Escolhe o template "Postgres dedicado (CNPG)".
- Preenche: grupo, nome, clusters-alvo, número de instâncias, storage e bancos desejados.
- O Backstage cria o repositório no GitLab, faz o commit inicial e dispara a pipeline.
- A pipeline gera senhas aleatórias (nunca vão para o Git), cria Secrets e aplica os manifests em cada cluster.
- O CNPG provisiona o Postgres em segundos.
Senhas nunca tocam o repositório. A pipeline lê managed.roles[] como fonte da verdade, gera secrets a partir de /dev/urandom antes do kubectl apply, e o CNPG recarrega automaticamente. O mesmo padrão se repete para outros modelos — WordPress, buckets S3, MySQL, MariaDB — cada um um template no catálogo do Backstage.
Como o Keycloak unifica a identidade sem prender a um provedor?
O plano de identidade do IBICT é o Keycloak, instalado via Operator, com três réplicas em HA e PostgreSQL externo. O tema de login é customizado com Keycloakify (React + Tailwind + DaisyUI), seguindo o Manual de Marca do IBICT.
O realm institucional é o centro de federação:
- LDAP/AD: federação com o diretório institucional para autenticação de usuários internos, com StartTLS obrigatório para operações de senha. Os usuários ficam com credencial local vazia — a autenticação é sempre delegada ao diretório, que é a fonte única da verdade.
- OIDC para todas as aplicações: GitLab, Grafana e Backstage — cada um é um client OIDC no mesmo realm, com roles e redirect URIs gerenciados de forma centralizada.
- Sticky session no Traefik: o tema Keycloakify gera resource hashes por pod; sem sticky session, o HTML de um pod referencia assets que outro pod não reconhece. Resolvido com annotation de cookie sticky no Service do Operator.
A escolha do Keycloak não é acidental: ele fala protocolos abertos (OIDC, SAML 2.0), roda em qualquer Kubernetes e não cobra por usuário. Se o IBICT quiser trocar de IdP no futuro, as aplicações não precisam mudar de código — elas confiam no protocolo, não no produto; trocar de IdP é reconfiguração, não reescrita.
Como o Backstage virou o portal de self-service?
O Backstage é o Internal Developer Platform do IBICT, servido no domínio institucional, com imagem custom, OAuth contra o Keycloak e banco PostgreSQL externo.
O catálogo de software registra automaticamente todos os componentes do ecossistema — repositórios GitLab, clusters Kubernetes, bancos de dados — e os Software Templates são a interface de self-service que elimina o ticket "cria um banco pra mim".
O catálogo de templates é dinâmico: um entity provider customizado descobre automaticamente os repositórios de modelos que contenham um template.yaml. Adicionar um novo template é criar um repositório com o mesmo padrão — sem redeploy do Backstage. Da mesma forma, o seletor de clusters de cada formulário consulta dinamicamente os agentes registrados: adicionar um cluster novo é push de config + instalação do agent, e o seletor passa a oferecê-lo sozinho. Em outras palavras, escalar a plataforma para um novo cluster é autodocumentado.
Como o Velero garante disaster recovery?
O Velero faz backup do estado lógico do cluster — todos os objetos da API Kubernetes — e File System Backup (FSB/Kopia) de volumes de arquivos, gravando tudo no Ceph RGW interno.
Duas rotinas gerenciadas pelo Helm:
| Rotina | Quando | Retenção | O que cobre |
|---|---|---|---|
| Diária | madrugada, todo dia | 30 dias | Todos os namespaces de app + FSB dos volumes anotados |
| Semanal | madrugada de domingo | 90 dias | Ponto de restauração histórico |
FSB é opt-in (defaultVolumesToFsBackup: false): um volume só entra no backup quando o pod é explicitamente anotado. Os candidatos são volumes de arquivos que realmente precisam (uploads, conteúdo de aplicações). Bancos de dados usam backup nativo (CNPG/Barman para Postgres), não FSB cru.
O snapshot de storage via CSI exigiria elevar privilégios no hypervisor — o que feriria o princípio do menor privilégio do cluster. Preferimos não elevar: o Velero (estado lógico + arquivos) e o Barman (bancos) cobrem disaster recovery real sem depender dele.
Quais foram os maiores desafios — e como os superamos?
Nenhuma plataforma dessas nasce pronta. Os obstáculos mais instrutivos não foram os componentes em si, mas as arestas onde eles encontram a realidade de um órgão público. Cinco valem o registro.
1. Trazer anos de história para dentro de casa, sem perder um commit. Migrar dezenas de projetos de um GitLab legado para uma instância atual, self-hosted, preservando todo o histórico (issues, merge requests, tags, comentários) exigiu mais do que um export/import. A instância nova vem, por padrão de segurança, com as fontes de importação desabilitadas; o modo administrativo passou a exigir ativação explícita por sessão; e renomear um grupo travava quando havia imagens no container registry, porque o caminho do grupo está embutido na identidade das imagens. Lição: em ferramentas maduras, privilégio de token não é privilégio de sessão — e cada redução de superfície precisa estar prevista no processo, senão vira horas de depuração. Automatizamos a migração com rastreamento de estado, para retomar de onde parou.
2. Federar identidade sem criar uma segunda cópia das senhas. A decisão-chave foi separar dois planos: um realm só para a administração e outro, federado, para os usuários — que ficam com credencial local vazia, forçando a autenticação a sempre delegar ao Active Directory institucional. Senha e bloqueio se resolvem numa única fonte da verdade; o cluster nunca guarda uma segunda cópia. Lição: federação bem-feita reduz a superfície de ataque em vez de aumentá-la, e isolar a superfície de administração da de autenticação dos usuários é um ganho de SecOps que não custa nada.
3. Storage de bloco contra uma rede isolada por design. A rede do storage é deliberadamente isolada da rede dos workers — boa prática que, no entanto, impede o caminho "natural" de cada pod falar direto com o Ceph. Em vez de furar o isolamento, invertemos a responsabilidade: o hypervisor provisiona o volume e o entrega à VM, e o Kubernetes só conversa com a API do hypervisor — que já é dependência do cluster. Lição: quando a rede é isolada de propósito, a resposta certa raramente é abrir uma exceção; é mover a responsabilidade para quem já está autorizado.
4. Tornar o próprio cluster um artefato versionado. Subir um cluster "na mão" é fonte inesgotável de divergência entre ambientes. Modelamos todo o ciclo de vida como código: um único fluxo descreve rede, máquinas, bootstrap e CNI, com o estado guardado de forma central e os segredos vindo sempre da pipeline. Lição: infraestrutura como código só entrega reprodutibilidade quando é completa — o "último 10% manual" é exatamente onde mora o erro de produção.
5. Integridade do backup acima da conveniência. O caminho cômodo do backup por snapshot esbarrou num requisito de privilégio que feriria o menor privilégio do cluster. Em vez de elevar privilégio, adotamos backup lógico nativo do banco (base diária + WAL contínuo, com recuperação a um ponto no tempo) gravado off-site. Lição: preservar a integridade arquitetural vale mais do que padronizar num único mecanismo. A capacidade que faltava ficou versionada, pronta para quando a plataforma a suportar com segurança.
Quanto custa operar isso?
A pergunta mais comum quando se apresenta essa stack é "quanto custa?". A resposta tem duas camadas.
Licenciamento: zero. Todos os componentes são open source com licenças que não cobram por core, socket ou usuário:
| Componente | Licença | Substitui |
|---|---|---|
| Talos Linux | MPL 2.0 | RHEL CoreOS / Ubuntu |
| Kubernetes | Apache 2.0 | EKS / AKS / OKE / GKE |
| Proxmox VE | AGPLv3 | vSphere / Hyper-V |
| Ceph | LGPL | SAN / NAS proprietário |
| CloudNativePG | Apache 2.0 | RDS / Cloud SQL |
| GitLab CE | MIT | GitHub Enterprise / GitLab SaaS |
| Keycloak | Apache 2.0 | Okta / Auth0 / Azure AD |
| Grafana + Loki + Mimir | AGPLv3 | Datadog / Splunk / New Relic |
| Backstage | Apache 2.0 | Port / Cortex / ServiceNow |
| Velero | Apache 2.0 | Backup de nuvem gerenciado |
| cert-manager | Apache 2.0 | Certificados TLS pagos |
| Traefik | MIT | Nginx Plus / F5 / HAProxy Enterprise |
Custo operacional: tempo de engenharia para implantar e manter. A stack foi desenhada para minimizar esse custo com automação em cada camada:
- Provisionamento: o cluster inteiro sobe a partir de um fluxo único de IaC.
- Deploy de apps: 1 push na branch de deploy faz build + deploy via templates compartilhados.
- Bancos de dados: 1 formulário no Backstage provisiona um cluster Postgres.
- Observabilidade de novos clusters: 2 charts (Alloy + Grafana) com overlays copiáveis.
- Upgrades: Helm upgrade com values versionados.
A conta de hardware (servidores, discos, rede) é do IBICT. O resto é engenharia.
O verdadeiro diferencial: complexidade desmistificada (e pronta para IA)
Montar essa stack é metade do trabalho. A outra metade — a que decide se um órgão consegue operar a plataforma depois que a consultoria sai — é o que consideramos o nosso real diferencial.
Cada componente foi entregue com um README que explica não só o que ele é, mas por que está ali e como operá-lo, com blocos de comando prontos para copiar e colar e um passo de validação ao final. As decisões técnicas difíceis — por que um CSI e não outro, por que um modo de operação transitório, por que um bootloader — ficaram registradas em documentos de decisão, para que ninguém reverta uma escolha sábia sem entender o motivo. Acima dos componentes, procedimentos ponta a ponta (subir uma aplicação, fazer onboard de um cluster satélite, criar um banco) amarram os repositórios numa rotina previsível. O layout é uniforme, os deploys são idempotentes e os segredos nunca moram no Git.
O efeito prático é que a complexidade deixa de ser um muro. Um time pequeno de sustentação — a realidade de quase todo órgão público — consegue manter, atualizar e estender a plataforma sem depender de quem a construiu.
E há uma camada a mais, deliberada: o ambiente foi preparado para que agentes de IA ajudem na sustentação do dia a dia. Documentação em linguagem natural, procedimentos decompostos em passos verificáveis (não "mágicos"), convenções explícitas e uma meta-instrução para agentes na raiz do repositório fazem com que um assistente de IA consiga ler a infraestrutura, executar uma tarefa de operação e confirmar sozinho que ela deu certo — com rastreabilidade de cada mudança. Não é só um ambiente complexo documentado para humanos; é um ambiente documentado para humanos e agentes de IA operarem juntos. Isso muda a economia da sustentação de uma instituição com equipe enxuta — e é, no fim, o que transforma uma boa arquitetura em um caso de sucesso que se sustenta sozinho.
O que esse caso prova sobre infraestrutura estatal?
O argumento padrão contra infraestrutura on-premises no setor público é que "nuvem é mais barato" e "não vale o esforço de operar". Esse argumento é verdadeiro para uma fatia dos casos — mas não para todos, e certamente não para uma instituição que já tem datacenter, equipe de infraestrutura e cargas de trabalho estáveis.
O caso do IBICT prova quatro coisas:
-
É possível rodar Kubernetes de produção sem licença por core. Cada componente da stack — do sistema operacional ao backup — tem uma alternativa open source madura que não cobra pelo uso.
-
Self-service não é exclusividade de nuvem pública. Com Backstage + GitLab CI + CNPG, um desenvolvedor provisiona um banco Postgres em segundos, sem abrir chamado. A experiência é comparável à de um serviço gerenciado — mas o dado mora no datacenter do instituto.
-
A operação pode ser simples mesmo sendo soberana. A complexidade foi documentada e empacotada para a equipe interna sustentar — inclusive com apoio de agentes de IA. Soberania deixou de implicar dependência da consultoria.
-
Portabilidade é uma decisão de arquitetura, não de ferramenta. Essa stack roda em qualquer Proxmox, qualquer Ceph, qualquer Kubernetes. Se o IBICT quiser migrar de hypervisor, de storage ou mesmo para uma nuvem pública, a identidade (Keycloak), o pipeline (GitLab CI), a observabilidade (LGTM) e o portal (Backstage) migram junto — porque são software, não serviço.
O custo de saída é zero. E isso, para uma instituição pública, não é detalhe — é requisito.
Perguntas Frequentes
-
Por que Talos Linux em vez de uma distro tradicional como Ubuntu ou RHEL?
Talos é um sistema operacional imutável, minimalista e feito exclusivamente para Kubernetes — sem SSH, sem gerenciador de pacotes, sem sistema de init genérico. Isso reduz a superfície de ataque, elimina drift de configuração entre nodes e simplifica o ciclo de vida: o upgrade é um único comando que aplica a nova imagem de disco e reinicia o node. Em infraestrutura governamental, onde compliance e previsibilidade são requisitos, a imutabilidade do Talos é um multiplicador de segurança operacional. -
Por que não usar o ceph-csi nativo e sim o proxmox-csi-plugin?
A rede pública do Ceph é isolada da rede dos workers Kubernetes por padrão de segurança do ambiente Proxmox hyperconvergente. O ceph-csi exige que cada pod abra conexão TCP direta com os monitors Ceph — o que é incompatível com esse isolamento. O proxmox-csi-plugin contorna isso falando com a API do Proxmox (já acessível), que provisiona o disco RBD e o expõe como virtio para a VM Talos. O trade-off é que só temos RWO (sem CephFS/RWX), mas o caminho de reativação do ceph-csi fica documentado para quando a rota entre as redes for liberada. -
Como vocês fazem backup e disaster recovery sem snapshots de storage?
Em duas camadas: Velero para o estado lógico do cluster (todos os objetos da API, com rotinas diária e semanal) gravando em S3 via Ceph RGW, com File System Backup (Kopia) para volumes de arquivos anotados. Para bancos Postgres, o CloudNativePG faz backup nativo off-site via Barman Cloud Plugin direto para S3 (WAL contínuo + base diário, com recuperação a um ponto no tempo). O snapshot de storage exigiria elevar privilégios no hypervisor, ferindo o menor privilégio — então preferimos o backup lógico, que cobre disaster recovery real sem depender dele. -
Qual o custo de licenciamento dessa stack?
Zero. Todos os componentes são open source com licenças que não cobram por core, socket ou usuário: Talos (MPL 2.0), Proxmox VE (AGPLv3), Ceph (LGPL), CloudNativePG (Apache 2.0), GitLab CE (MIT), Keycloak (Apache 2.0), Grafana/Loki/Mimir/Alloy (AGPLv3), Backstage (Apache 2.0), Velero (Apache 2.0), cert-manager (Apache 2.0), Traefik (MIT). O custo real é operacional: tempo de engenharia para implantar e manter. O resto é conta de energia e hardware. -
Isso escala para outros órgãos ou unidades?
Sim, e o modelo já contempla isso. O padrão satélite da observabilidade significa que um novo cluster adiciona apenas Alloy (coletor) e Grafana (UI), consumindo os backends centrais Loki e Mimir via LoadBalancer interno. O GitLab Agent replica o mesmo modelo de deploy GitOps. O portal Backstage com templates de self-service permite que qualquer equipe provisione um banco Postgres dedicado em qualquer cluster registrado, sem abrir chamado para a infraestrutura. O custo marginal de um cluster novo é basicamente o hardware.
Fontes:
- Talos Linux — documentation — Sidero Labs
- Proxmox VE — documentation — Proxmox Server Solutions
- Ceph — documentation — Ceph Foundation
- OpenTofu — documentation — The Linux Foundation
- proxmox-csi-plugin — sergelogvinov (GitHub)
- CloudNativePG — documentation — EDB
- Keycloak — documentation — CNCF
- Backstage — documentation — CNCF
- Grafana LGTM Stack — Grafana Labs
- Velero — documentation — VMware Tanzu (CNCF)
- GitLab Agent for Kubernetes — GitLab
- cert-manager — documentation — CNCF
- Traefik Proxy — documentation — Traefik Labs
