

TL;DR: A Microsoft criou um sistema de IA que avalia reuniões virtuais em 5 dimensões — Participação, Engajamento, Estrutura, Sentimento e Qualidade Técnica — usando Azure AI e LLMs. Após testar 68 reuniões reais, descobriu-se que a maioria pontua bem em qualidade técnica (92/100), mas sofre com engajamento (77/100). A conclusão prática: agendas mais claras, pontos de interação intencionais e ações explícitas ao final são as alavancas mais eficazes para times brasileiros que dependem de reuniões remotas produtivas.
Introdução: o problema de medir reuniões
Se suas reuniões pudessem dizer como melhorar, você as ouviria? Pesquisas indicam que 17% das reuniões são percebidas como ineficazes — e isso é um número conservador. Para empresas brasileiras que operam com times remotos ou híbridos, o custo de reuniões improdutivas vai além do tempo perdido: impacta a tomada de decisão, a moral do time e, em última instância, o delivery de projetos.
Foi pensando nisso que a Microsoft, em parceria com a Santa Clara University, desenvolveu o Online Meeting Effectiveness Index (OMEI) — um framework baseado em LLM que transforma gravações de reuniões em scores objetivos e recomendações acionáveis. O projeto analisou 68 reuniões reais disponíveis publicamente no YouTube, abrangendo contextos corporativos, governamentais e acadêmicos, com grupos de 3 a 20 participantes.
Como o OMEI mede a efetividade das reuniões?
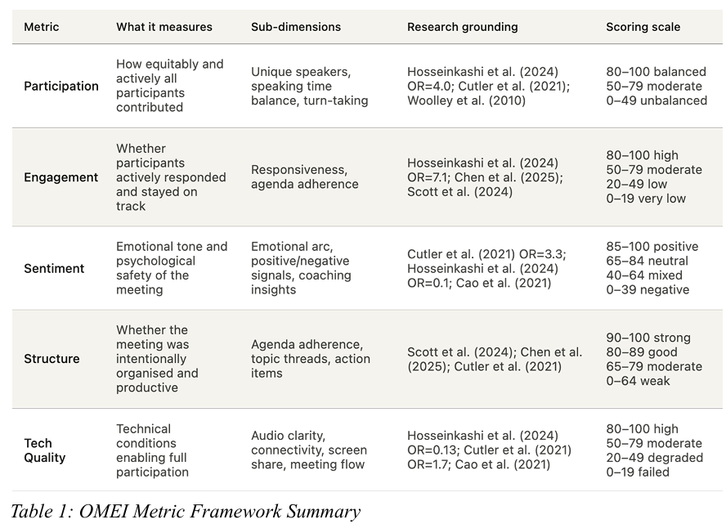
O framework é composto por cinco métricas principais, cada uma com três sub-métricas, totalizando 15 indicadores mensuráveis de qualidade de reunião:
Dimensão 1: Tom Emocional e Segurança Psicológica
A segurança psicológica — a disposição das pessoas em compartilhar pensamentos — é o preditor mais forte de sucesso de uma reunião (OR=3,3), superando pauta, vídeo e tamanho do grupo. Em ambientes remotos, onde a ausência de sinais não verbais aumenta o multitasking, o tom verbal se torna o principal determinante do clima emocional. O OMEI pontua o sentimento em uma escala de 0 a 100.
Dimensão 2: Engajamento Ativo e Adesão à Pauta
Falar por pelo menos 10% do tempo de reunião aumenta em 4x a percepção de inclusão. Grupos com oito ou menos participantes têm 7x mais chances de engajamento vocal, e a efetividade cai cerca de 1 ponto percentual para cada dois participantes adicionais. O OMEI avalia responsividade e adesão à pauta.
Dimensão 3: Quem Falou, Quanto e com Qual Equidade
Não basta que todos falem — é preciso que a distribuição do tempo de fala seja equilibrada. O estudo usa o coeficiente de Gini para medir essa distribuição (0 = perfeitamente igual, 1 = uma pessoa dominou) e avalia turnos de fala para distinguir diálogo real de monólogos desconectados.
Dimensão 4: Estrutura da Reunião e Resultados
Metas pouco claras são um dos maiores obstáculos à produtividade. O OMEI avalia três sub-dimensões: adesão à pauta (não apenas se existe, mas se foi seguida), coerência dos tópicos de discussão e qualidade dos action items gerados.
Dimensão 5: Qualidade Técnica como Pré-requisito
Falhas de confiabilidade reduzem as chances de participação em 87% (OR=0,13). Áudio e vídeo de baixa qualidade reduzem a probabilidade de sucesso em 90% (OR=0,1). O uso de headset, por si só, aumenta as chances de participação em 20%.
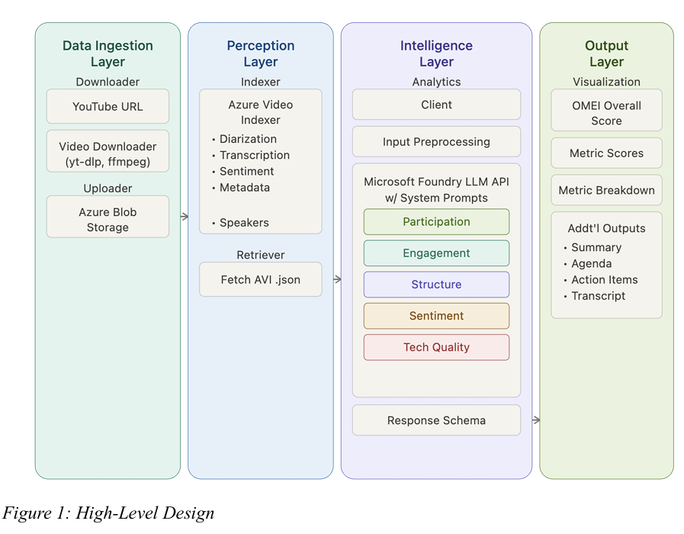
O Pipeline Técnico: do vídeo ao score
A arquitetura do OMEI segue quatro camadas:
- Ingestão de dados: download de vídeos via yt-dlp e FFmpeg, armazenamento no Azure Blob Storage
- Percepção: Azure Video Indexer gera diarização, transcrição, sinais de sentimento e metadados
- Inteligência: dados pré-processados são enviados ao Microsoft Foundry para análise baseada em LLM
- Saída: scores e recomendações são apresentados em uma interface web leve
Metodologia LLM: por que o GPT-5.4-mini foi escolhido
O pipeline testou GPT-5.4-mini, GPT-5.4-nano, DeepSeek-R1, GPT-5.4 e Phi-4. O GPT-5.4-mini foi selecionado pelo melhor equilíbrio entre qualidade de scoring, consistência e recomendações acionáveis. Modelos maiores tendiam a superinterpretar a tarefa, enquanto modelos menores produziam justificativas mais fracas.
Um ponto crítico: nenhum modelo testado foi capaz de realizar cálculos complexos baseados em tempo a partir dos dados de diarização. Por isso, campos quantitativos — como tempo total de fala por participante, índices de equilíbrio e silêncios — foram pré-processados antes da avaliação do LLM.
Lições aprendidas com 68 reuniões
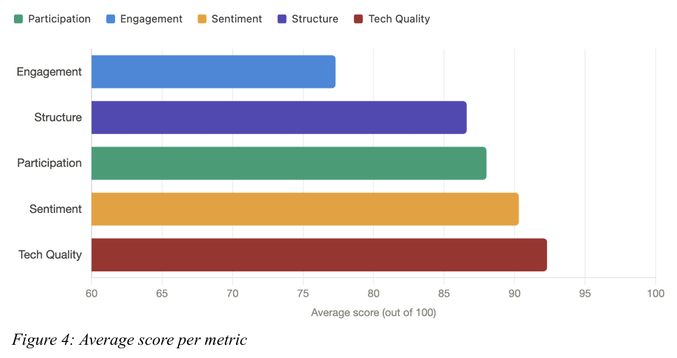
O score médio geral foi de 86/100, com os maiores resultados em Qualidade Técnica (92,3) e Sentimento (90,3), e o menor em Engajamento (77,3).
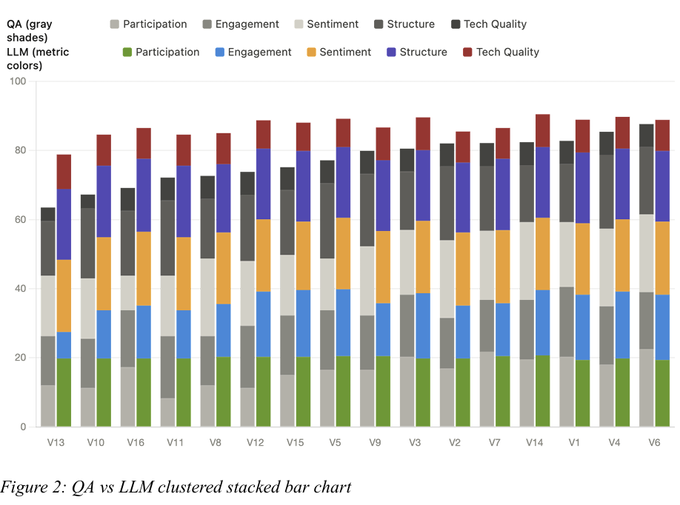
Abordagem de Garantia de Qualidade
Sete analistas humanos independentes avaliaram 14 reuniões, gerando um score composto médio de 66,84. O LLM original, sem calibração, superestimava os scores em ~20 pontos. Após revisão dos prompts, a diferença caiu para ~6 pontos.
Recomendações práticas para organizadores de reunião
- Comece com um propósito declarado e termine com decisões resumidas, action items e responsáveis nomeados
- Em reuniões com muitas apresentações ou grupos grandes, crie intencionalmente pontos de interação (perguntas, pausas para discussão, check-ins)
- Interprete os scores OMEI como indicadores direcionais, não julgamentos definitivos — use-os para identificar padrões recorrentes
Recomendações para integração de software
Embora o protótipo use Azure Video Indexer, o Azure Speech pode ser mais adequado para produção, já que a pontuação depende principalmente de transcrições e dados de timing, não de análise visual. O pré-processamento de sinais numéricos antes do LLM continua sendo necessário.
Conclusão
O OMEI demonstra que LLMs podem transformar dados não estruturados de reuniões virtuais em avaliações significativas de efetividade. Para empresas brasileiras que buscam extrair mais valor de suas reuniões remotas — seja no Teams, Zoom ou Google Meet — o framework oferece um caminho concreto para sair da mera transcrição e avançar para melhorias mensuráveis em colaboração e produtividade.
Perguntas Frequentes
-
O que diferencia o OMEI de outras ferramentas de análise de reuniões?
Diferente de soluções que apenas transcrevem ou gravam reuniões, o OMEI usa um pipeline com Azure Video Indexer e LLMs (GPT-5.4-mini) para gerar scores numéricos e recomendações acionáveis em cinco dimensões. O framework foi calibrado com avaliações humanas independentes para reduzir vieses. -
Como a calibração dos prompts do LLM afeta a precisão do OMEI?
Sem calibração, o LLM original superestimava os scores em aproximadamente 20 pontos. Após revisões nos prompts — incluindo exigência de evidências afirmativas e caps baseados em sinais mensuráveis — a diferença caiu para cerca de 6 pontos. -
Quais métricas de reunião tiveram pior desempenho e o que fazer para melhorá-las?
Engajamento foi a dimensão mais baixa (77,3/100), especialmente em reuniões do tipo apresentação (72/100). A recomendação é incorporar pontos de interação intencionais e garantir que reuniões terminem com action items e responsáveis nomeados. -
O OMEI está pronto para uso em produção?
O projeto atual é um proof of concept. Para produção, recomenda-se usar Azure Speech em vez de Azure Video Indexer, já que a pontuação depende principalmente de transcrições e dados de timing, não de análise visual. -
Como o tamanho do grupo impacta a efetividade da reunião?
Grupos com oito ou menos participantes têm 7x mais chances de engajamento vocal. A efetividade cai cerca de 1 ponto percentual para cada dois participantes adicionais. Falar por pelo menos 10% do tempo aumenta em 4x a percepção de inclusão.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
