

Libertando-se de um único datacenter: Operações práticas de IA geo-distribuída com o stack k0smos
TL;DR: A suposição de um datacenter único e homogêneo não reflete a realidade fragmentada de GPU on-prem, edge e cloud. O stack k0smos (k0s, k0smotron, k0rdent) estende o Kubernetes para multi-cluster geo-distribuído, permitindo treinamento e inferência em hardware heterogêneo (Nvidia+AMD) com conectividade P2P via Cilium. Estudos de campo com o projeto exalsius mostram ser possível rodar workloads de IA em clusters que cruzam continentes e fornecedores, inclusive adaptando-se dinamicamente a janelas de energia renovável. A principal conclusão: com a plataforma certa, a fragmentação deixa de ser um bloqueio absoluto.
Por que a suposição de um datacenter único não se sustenta mais?
Arquiteturas modernas de IA foram construídas sobre a premissa de datacenters centralizados e homogêneos. Na prática, a infraestrutura é fragmentada: recursos computacionais estão espalhados por nuvens privadas, ambientes de pesquisa e hardware on-prem e edge de diferentes gerações. Presos em silos operacionais, alavancar esses recursos distribuídos para workloads exigentes de IA torna-se extremamente difícil. Utilizar GPUs eficientemente deixou de ser apenas um problema de computação; é fundamentalmente um desafio de infraestrutura.
Como a IA geo-distribuída se torna um problema de Kubernetes?
A infraestrutura de IA cruzou silenciosamente um limiar. O que começou como um desafio de machine learning — treinar modelos mais rápido, servir inferência mais barato e escalar computação sob demanda — tornou-se mais amplo e estrutural. Com players como OpenAI construindo suas bases no Kubernetes e a CNCF formalizando essa direção, o Kubernetes se tornou a camada de orquestração de facto para workloads de IA. A IA geo-distribuída é agora fundamentalmente um problema de infraestrutura cloud-native.
No entanto, quando workloads se libertam de um único datacenter centralizado para abranger clusters on-prem, regiões de nuvem e deployments edge, a complexidade se multiplica. Você não está mais apenas agendando um job de treinamento. Precisa gerenciar ciclos de vida de clusters entre geografias, manter conectividade cross-site e integrar hardware em rápida evolução — desde interconexões ultra-rápidas como NVLink até inovações de memória como HBM. Esses são problemas fundamentais de sistemas distribuídos que estão no território do Kubernetes.
É aqui que a orquestração multi-cluster se torna inegociável. Um único cluster não pode abranger essas geografias, e uma frota gerenciada manualmente quebrará rapidamente as equipes. O que é necessário é uma camada de plataforma resiliente que lide com rede cross-site e hardware heterogêneo de forma consistente, permanecendo inteiramente nativa do Kubernetes. Em última análise, a pergunta não é mais se devemos rodar IA no Kubernetes. É se sua plataforma Kubernetes está construída para lidar com IA onde quer que ela precise rodar.
Como usar o stack k0smos como base?
Como um conjunto coeso de projetos open-source, o stack k0smos fornece a base arquitetural para operar infraestrutura de IA geo-distribuída, dividindo responsabilidades em três camadas técnicas. No núcleo está o k0s, uma distribuição Kubernetes totalmente conforme à CNCF, empacotada como um único binário sem dependências. Ao evitar suposições embutidas sobre CNIs específicos, runtimes ou gerenciadores de pacotes, o k0s roda nativamente em praticamente qualquer ambiente Linux sem poluir o sistema operacional host. Esse modelo de execução enxuto o torna um runtime versátil capaz de executar workloads Kubernetes padrão em nós edge fragmentados, servidores bare-metal e VMs com recursos limitados.
Para gerenciar esses deployments em escala, o k0smotron opera como o motor para hosted control planes (HCPs). É um operador Kubernetes que implanta control planes do k0s como pods isolados e versionados dentro de um cluster de gerenciamento central, desacoplando completamente o control plane dos nós workers. Ao tratar control planes como workloads agendados dinamicamente, em vez de infraestrutura dedicada, o k0smotron reduz significativamente a sobrecarga de recursos. Ele permite um modelo de remote machine onde nós workers localizados em qualquer ambiente geo-distribuído — instâncias cloud, hardware on-prem ou nós edge — podem ser anexados ao cluster de gerenciamento central.
Unindo o sistema está o k0rdent, o plano de gerenciamento declarativo para orquestração do ciclo de vida de múltiplos clusters. Ele abstrai provisionamento, configuração e templating da frota de clusters em APIs nativas do Kubernetes, estabelecendo um fluxo de trabalho GitOps onde clusters são declarados, versionados e auditados como infrastructure-as-code. Através de seu suporte a múltiplos provedores, o k0rdent apresenta uma interface operacional consistente independentemente de a infraestrutura subjacente ser bare metal, OpenStack, AWS, vSphere ou qualquer outro provedor de recursos computacionais, padronizando efetivamente ambientes de hardware altamente heterogêneos na camada de plataforma.
Estudos de campo em infraestrutura de IA heterogênea geo-distribuída
Baseando-se no stack k0smos descrito acima, estamos colaborando com a Agência Federal Alemã para Inovação Disruptiva (SPRIND). O objetivo do nosso projeto conjunto exalsius é agregar recursos de GPU heterogêneos fragmentados em um sistema computacional unificado.
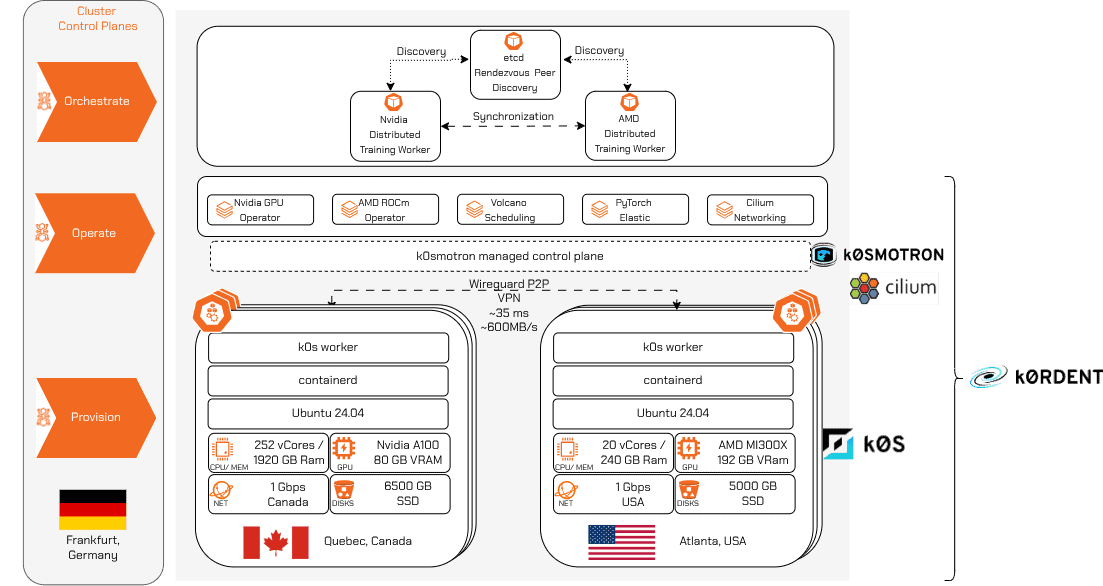
Para validar essa abordagem, construímos um ambiente que reflete a realidade fragmentada da infraestrutura de IA atual. Conforme ilustrado no diagrama de arquitetura, montamos um ambiente que conecta nós Nvidia A100 em Quebec com nós AMD MI300X em Atlanta. O control plane do cluster é hospedado em nós apenas com CPU em Frankfurt, Alemanha. Essa configuração visa provar que ambientes GPU cross-border e cross-vendor podem funcionar de forma coesa.
Como o stack k0smos lida com o ciclo de vida fundamental do cluster, conseguimos evitar a construção de infraestrutura de gerenciamento customizada. Em vez disso, adicionamos componentes para detectar e perfilar automaticamente o hardware disponível (crucial para configurações de treinamento eficientes) e focamos nossa engenharia em três camadas principais:
-
Provisionamento: Utilizamos o ClusterAPI provider do k0smotron para disparar deployments diretamente do nosso cluster de gerenciamento em Frankfurt. Os workers em Quebec e Atlanta foram provisionados com k0s e suas respectivas stacks de software GPU específicas do fornecedor (o Nvidia GPU Operator para as A100s e o ROCm Operator para as MI300Xs).
-
Operação: Para conectividade cross-site, implantamos o projeto CNCF Cilium como nosso CNI, estabelecendo túneis P2P seguros e diretos via Wireguard (~35ms de latência, ~600MB/s) entre os nós workers. O tráfego do plano de dados ignora completamente gateways VPN centralizados, enquanto o estado do cluster permanece gerenciado centralmente em Frankfurt. Sobre essa rede, integramos frameworks de IA como PyTorch Elastic, Ray e vLLM usando ServiceTemplates e Helm charts customizados do k0rdent, provisionados via k0rdent state manager (KSM) usando Sveltos.
-
Orquestração: Adicionamos a abstração operacional e a lógica de negócios necessárias para executar treinamento distribuído e batch workloads de forma confiável sobre a rede P2P.
Nosso primeiro estudo de campo validou essa arquitetura executando workloads de IA estáveis e reproduzíveis em uma configuração geo-distribuída estática. Treinamos com sucesso um conjunto diversificado de modelos de referência, incluindo GPT-NeoX para LLMs, ResNet para visão computacional, GCN para aprendizado em grafos, PPO para reinforcement learning e Wav2Vec2 para áudio, diretamente entre os nós AMD e Nvidia.
O habilitador crítico para esse sucesso foi o co-design da infraestrutura e da metodologia de treinamento. Para evitar que nossos links P2P de longa distância se tornassem um gargalo, implementamos uma abordagem de treinamento distribuído de baixa comunicação utilizando otimização de momentum desacoplado (detalhado em nossas publicações no NeurIPS [add-links] e repositório de código [add-link]). Enquanto a camada de sistemas subjacente gerenciou a execução do hardware heterogêneo, essa camada especializada de treinamento reduziu drasticamente as demandas de comunicação cross-site.
Este estudo provou que distância física e heterogeneidade de hardware não são mais barreiras absolutas para o treinamento de modelos distribuídos. Ao combinar o stack k0smos com nossos componentes de orquestração customizados, os workloads são executados de forma coesa entre sites, completamente agnósticos ao provedor subjacente, localização física ou fornecedor de GPU.
Em nosso segundo estudo de campo, relaxamos a suposição de ambiente estático para refletir um modelo operacional mais realista: um ambiente altamente dinâmico onde recursos de GPU entram e saem do pool de treinamento com base na disponibilidade de eletricidade abundante. À medida que sites geográficos entram e saem de janelas energéticas favoráveis, o tecido de recursos ativos muda constantemente.
Para gerenciar essa rotatividade, adotamos um paradigma de aprendizado federado, tratando cada site como um domínio de treinamento independente que sincroniza o estado do modelo apenas quando ativo. Baseando-nos em nossa fundação k0smos, projetamos esse ciclo de vida dinâmico através de três implementações principais:
-
Expusemos uma API que permite ao scheduler de orquestração provisionar e desprovisionar workers com base em sinais em tempo real de abundância de energia fornecidos pelo nosso parceiro sem fins lucrativos WattTime. Uma extensão customizada do k0smotron traduz esses sinais, ativando capacidade GPU durante janelas favoráveis e liberando-a conforme as condições mudam.
-
Desenvolvemos um operador Kubernetes customizado para o framework Flower AI (links github nas Referências). Implantado via k0rdent state manager (KSM), esse operador reconcilia um recurso customizado declarativo "Federation". Nós recém-iniciados entram instantaneamente na federação como sites de treinamento elegíveis, enquanto nós desprovisionados saem do loop de reconciliação de forma graciosa.
-
Em runtime, o coordenador e os sites ativos se comunicam via gRPC sobre nossa rede P2P segura estabelecida. Implementamos uma estratégia de scheduling customizada no lado do servidor, utilizando uma fila Redis Publish-Subscribe para transmitir de forma confiável conclusões de rodadas e sinais de desligamento através da frota efêmera.
Recentemente apresentado no Flower AI Summit 2026 e EuroSys 2026, este estudo prova que nossa plataforma cloud-native se estende do treinamento geo-distribuído estático para uma orquestração dinâmica e energeticamente consciente. Para um mergulho mais profundo nos detalhes técnicos e resultados experimentais, leia o relatório técnico ou explore o repositório de código (links nas Referências).
Conclusão: viabilidade e desafios
Embora o stack k0smos tenha fornecido uma base cloud-native altamente estável, esses estudos de campo destacaram onde reside o atrito em ambientes fragmentados: gerenciamento do ciclo de vida de GPUs e rede cross-site. Na prática, colocar nós em um estado limpo e pronto para GPU em diferentes sites é um trabalho confuso. Apesar do trabalho pesado feito pelos operadores Nvidia e ROCm, lidar com kernels específicos de nuvem, drivers pré-instalados conflitantes e estados parcialmente configurados requer consciência operacional profunda. Da mesma forma, enquanto WireGuard e Cilium lidaram com conectividade cross-site segura com overhead desprezível de largura de banda, gerenciar restrições de rede específicas do site e sincronização sensível à latência para treinamento distribuído (como torch.distributed) continua sendo um desafio complexo de engenharia.
No entanto, a conclusão mais encorajadora é que executar workloads de IA em hardware heterogêneo geo-distribuído é totalmente viável hoje. Ao agregar capacidade GPU isolada em um tecido de recursos unificado e poderoso, podemos nos adaptar dinamicamente a modelos de execução em mudança sem precisar reconstruir a plataforma subjacente. Para apoiar esse ecossistema em evolução, estamos ativamente contribuindo com nossas customizações e ferramentas de volta como contribuições upstream para os projetos Mirantis k0smos, garantindo que a comunidade mais ampla possa continuar a construir sobre essa base.
Perguntas Frequentes
-
Quais são os principais desafios de rodar IA em hardware heterogêneo geo-distribuído?
Os maiores desafios são o gerenciamento do ciclo de vida de GPUs (drivers, kernels específicos de cada nuvem) e a conectividade cross-site com baixa latência. Mesmo com operadores como Nvidia GPU Operator e ROCm, é comum encontrar estados parcialmente configurados. Além disso, a sincronização de treinamento distribuído (ex: torch.distributed) exige redes otimizadas. -
Como o stack k0smos ajuda a gerenciar clusters multi-cloud?
O k0s é uma distribuição Kubernetes leve e zero-dependency, rodando em qualquer Linux sem poluir o host. O k0smotron desacopla o control plane dos workers, permitindo que nós em diferentes clouds ou edge sejam gerenciados a partir de um cluster central. O k0rdent provê um plano de gestão declarativo com GitOps, abstraindo provedores como AWS, vSphere, bare metal e OpenStack. -
É possível treinar modelos de IA em GPUs de diferentes fabricantes simultaneamente?
Sim. O estudo de campo do projeto exalsius conectou nós Nvidia A100 (Quebec) com AMD MI300X (Atlanta) através de túneis Wireguard via Cilium. O stack k0smos abstraiu a diferença de hardware, e uma camada de treinamento com otimização de momentum desacoplado reduziu a comunicação cross-site, provando ser viável treinar modelos como GPT-NeoX e ResNet em hardware heterogêneo. -
O que diferencia o k0smos de outras soluções de multi-cluster?
O k0smos é 100% Kubernetes-native, zero-dependency e modular. Ele não impõe CNIs, runtimes ou package managers específicos. O k0smotron permite control planes hospedados como pods, reduzindo overhead. O k0rdent oferece templates de cluster e suporte a múltiplos provedores de forma consistente. Tudo isso com foco em ambientes heterogêneos e edge, ideal para empresas brasileiras com infraestrutura fragmentada. -
Como a orquestração dinâmica baseada em energia renovável funciona?
No segundo estudo de campo, uma API exposta pelo k0smotron interpreta sinais de abundância energética (via WattTime) para provisionar ou desprovisionar workers. Usando o framework Flower e um operador Kubernetes customizado, nós entram e saem do pool de treinamento conforme a janela de energia. A comunicação entre coordenador e sites ativos usa gRPC sobre a rede P2P, com filas Redis para broadcast de sinais.
Artigo originalmente publicado por Prithvi Raj (Mirantis), Alexander Acker (Logsight.ai), and Soeren Becker (Logsight.ai) em Cloud Native Computing Foundation.
