

GKE Inference Gateway acelera respostas de IA em até 92%, mostra benchmark independente
TL;DR: O GKE Inference Gateway, com prefix caching e roteamento consciente do modelo, entrega até 92,8% menos TTFT, 62,6% menos ITL e 15,7% mais throughput em inferência de LLMs comparado a um managed Kubernetes tradicional. Para empresas brasileiras que rodam workloads de IA generativa, isso significa redução drástica de latência e melhor aproveitamento de GPUs/TPUs, viabilizando aplicações production-grade com custos mais previsíveis.
Enquanto a IA generativa sai de projetos piloto para ambientes massivos de produção, a eficiência da sua infraestrutura se torna o diferencial definitivo. Uma forma de extrair o máximo dela e minimizar o tempo ocioso de aceleradores caros é usar o GKE Inference Gateway, uma extensão nativa do GKE Gateway que roteia workloads de IA generativa com base em métricas reais dos servidores de modelo.
Em vez de depender de round-robin tradicional — que frequentemente dispara recomputação desnecessária em aceleradores e aumenta a latência para o usuário — o gateway utiliza capacidades avançadas como prefix caching e model-aware routing. Ao garantir que requests cheguem exatamente ao acelerador que já está pronto para processá-los, o GKE transforma a forma como você serve Large Language Models (LLMs), com excelente utilização de hardware e tempos de resposta ultrarrápidos.
De fato, de acordo com um benchmark independente, o GKE Inference Gateway supera o principal serviço Kubernetes gerenciado concorrente com 15,7% mais throughput, 92,8% menos tempo de espera e 62,6% menos latência entre tokens. Esse desempenho leva aplicações baseadas em LLM de lentas e caras para rápidas e prontas para produção.
Esse desempenho é consistente com a experiência da Snap usando o GKE Inference Gateway.
“Na Snap, estamos integrando o llm-d à nossa infraestrutura de IA de produção para viabilizar inferência de alto desempenho em escala. Ao empregar roteamento consciente de cache de prefixo, alcançamos taxas de hit de cache de prefixo de até 75-80%. Apreciamos a natureza open source do llm-d, pois permite integração perfeita com nosso Service Mesh baseado em Envoy.” — Vinay Kola, Senior Manager, Software Engineering, Snap Inc.
Neste artigo, analisamos em detalhes o prefix caching do GKE Inference Gateway, com exemplos práticos, e os resultados do benchmark. Vamos direto ao ponto.
Como o prefix caching reduz a latência em LLMs?
Prefix caching otimiza o desempenho de LLMs armazenando o KV cache (estados de ativação) de prefixos de prompts longos e repetitivos. Quando requests consecutivos de usuários compartilham as mesmas instruções de sistema, contexto ou documentação, o modelo pula completamente o reprocessamento desses tokens. O GKE Inference Gateway lê os prefixos dos requests recebidos e os associa aos pods específicos que já mantêm esses dados em memória. Isso elimina o custo de "pensar" das GPUs e TPUs, transformando loops pesados de raciocínio em respostas quase instantâneas.
Caso de uso 1: Q&A sobre documentação e codebase com RAG
Ao consultar repositórios empresariais massivos, você pode fundamentar as respostas dos LLMs sem latência adicional, fixando conjuntos inteiros de documentação como prefixos estáticos em cache, usando RAG.
Em vez de forçar um LLM a reler milhares de linhas de referências de API ou wikis corporativos para cada pergunta de usuário, o GKE Inference Gateway roteia a consulta para um pod que já tem aquele contexto aquecido em seu KV cache. O LLM só precisa computar a pergunta dinâmica do usuário, eliminando completamente a reavaliação cara de documentos.
[STATIC PREFIX - STAYS IN CACHE] You are an expert AI assistant specializing in technical documentation. Below is the complete API documentation for our software platform. Use this context to answer the user's questions accurately. If the answer cannot be found in the documentation, say "I cannot find that in the provided context."
<documentation> [10,000+ words of API reference documentation, endpoints, error codes, etc.] </documentation>
[DYNAMIC SUFFIX - CHANGES PER REQUEST] User Question: How do I handle a 429 rate limit error using the Python SDK?
Caso de uso 2: Chat multi-turn
Você também pode usar prefix caching para manter interações de atendimento ao cliente em milhares de sessões simultâneas sem acumular custos de computação. Basta armazenar em cache personas de sistema permanentes e regras de negócio principais diretamente no servidor LLM.
Em arquiteturas de chat empresarial, o system prompt base e tabelas de referência permanecem completamente idênticos em milhões de interações. O GKE Inference Gateway lida com essas conversas multi-turn usando roteamento consciente de contexto para evitar processamento repetitivo de tokens, mantendo seu chatbot ultrarrápido mesmo sob pico de tráfego.
[STATIC PREFIX - STAYS IN CACHE]
-System Persona: You are "FinBot", a helpful, empathetic, and compliant virtual assistant for ABC Banking Solutions. You must strictly adhere to the following rules: 1. Never provide concrete investment advice. 2. Always verify if the user is asking about checking or savings. 3. Keep your answers under 3 sentences. 4. If a user is angry, offer to connect them to a human manager.
Here is the current interest rate table for May 2026:
- Savings: 4.2% APR
- Checking: 0.5% APR
- CD (12-month): 5.1% APR
[DYNAMIC SUFFIX - CHANGES PER REQUEST] User: Hi, I'm trying to figure out how much I'd make if I locked away $10,000 for a year?
O que os benchmarks independentes mostram sobre o GKE Inference Gateway?
Para validar essas vantagens arquiteturais, a Principled Technologies publicou recentemente um benchmark independente comparando o GKE (equipado com o GKE Inference Gateway) contra um serviço Kubernetes gerenciado de terceiros utilizando balanceamento HTTP round-robin convencional.
Testado em um workload de prefixo compartilhado com Llama 3.1 8B Instruct, usando hardware idêntico (oito NVIDIA A100 40GB), os resultados revelam um gap massivo de desempenho entre os dois serviços Kubernetes. O GKE não apenas venceu; ele redefiniu a eficiência de inferência em três métricas críticas:
- Maior throughput: 15,7% mais tokens processados por segundo, permitindo maior capacidade de requests ou hardware reduzido para o mesmo workload.
- Tempo até o primeiro token (TTFT) muito mais rápido: 92,8% menos tempo de espera, resultando em inícios de resposta dramaticamente mais rápidos para cenários interativos.
- Menor latência entre tokens (ITL): redução de 62,6%, resultando em streaming de tokens mais suave e rápido após o primeiro token.
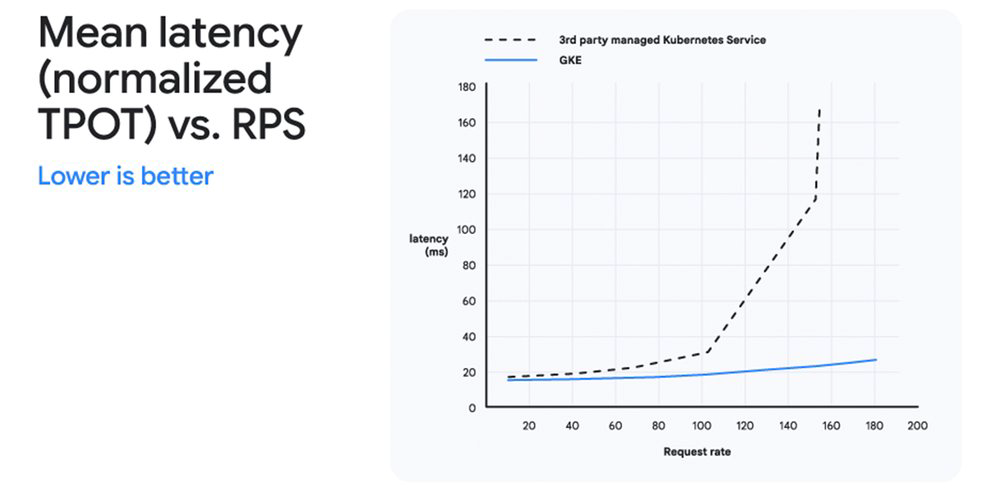
Figura 3: Latência média (tempo normalizado por token de saída) do GKE com GKE Inference Gateway e do serviço Kubernetes gerenciado de terceiros no LLM Llama 3.1-8B Instruct, caso de uso de prefixo compartilhado. Ambas as soluções usaram o mesmo hardware. Fonte: Principled Technologies
| Métrica | GKE | Serviço K8s gerenciado de terceiros | Vantagem do GKE |
|---|---|---|---|
| Throughput médio de tokens de saída | 7.169,21 tokens/s | 6.042,05 tokens/s | 15,7% mais throughput |
| Tempo médio até o primeiro token (TTFT) | 188,36 ms | 2.624,73 ms | 92,8% menos TTFT |
| Latência média entre tokens (ITL) | 30,20 ms | 81,03 ms | 62,6% menos ITL |
Figura 4: GKE com GKE Inference Gateway entregou inferência de IA superior comparado a um serviço Kubernetes gerenciado de terceiros usando HTTP LB padrão.
Como acelerar seus workloads de inferência de IA generativa?
Seja implantando workloads de inferência como agentes de suporte ao cliente em tempo real, assistentes de codificação dinâmicos ou modelos de detecção de fraude em milissegundos, a latência da infraestrutura dita a experiência do usuário. Ao garantir que prefixos de prompts compartilhados atinjam o cache ativo quase 100% do tempo, o GKE Inference Gateway transforma seus LLMs de motores de raciocínio lentos e caros em potências rápidas e eficientes, prontas para produção.
Para explorar a vantagem de desempenho que o GKE Inference Gateway pode trazer para seus workloads de IA generativa, acesse o relatório completo do benchmark aqui e assista a este vídeo explicativo.
Um agradecimento especial a Dan Sullivan, Senior Performance Architect, Principled Technologies.
Perguntas Frequentes
-
O que é prefix caching no contexto do GKE Inference Gateway?
É uma técnica que armazena em cache os estados de ativação (KV cache) de prefixos de prompts longos e repetitivos. Quando novos requests compartilham o mesmo contexto (system instructions, documentação), o modelo evita reprocessar esses tokens, reduzindo drasticamente latência e uso de computação. -
Como o GKE Inference Gateway se compara a um serviço Kubernetes gerenciado tradicional?
Segundo benchmark da Principled Technologies, o GKE com Inference Gateway superou o concorrente com 15,7% mais throughput, 92,8% menos tempo para o primeiro token (TTFT) e 62,6% menos latência entre tokens (ITL), usando o mesmo hardware (8x NVIDIA A100 40GB) e workload Llama 3.1 8B. -
Quais casos de uso se beneficiam mais do prefix caching?
Workloads com prompts compartilhados, como Q&A sobre documentação com RAG e chats multi-turn com system prompts fixos. O cache de prefixo evita recomputação cara em GPUs/TPUs, tornando aplicações de IA generativa mais rápidas e eficientes. -
O GKE Inference Gateway é open source?
O componente llm-d (utilizado no roteamento) é open source, como destacado pelo case da Snap, que o integrou ao seu Service Mesh baseado em Envoy. Isso permite personalização e integração com stacks existentes.
Artigo originalmente publicado por Susan Wu - Outbound Product Manager em Cloud Blog.
